耦合系统下训练AI模型-进步or倒退?
最近阅读了MICRO20的一篇文章-《TrainBox: An Extreme-Scale Neural Network Training Server Architecture by Systematically Balancing Operations》。一反常态,该文章选择从存储与网络角度将资源耦合整机部署,使得操作专用化,减少数据的移动与带宽争用,优化AI训练效率。
系统资源整合与解耦是两种对立的设计哲学,也逐渐成为系统顶会的热点话题。本文从整机的角度出发,将各部分操作专用化,解决了当前DNN训练的一些问题。读完该文章后引发了许多思考,借助本文,我将总结一些想法,对未来的AI架构设计提出展望。
一、概述
在讲故事前,我们普及一下AI的训练流程:
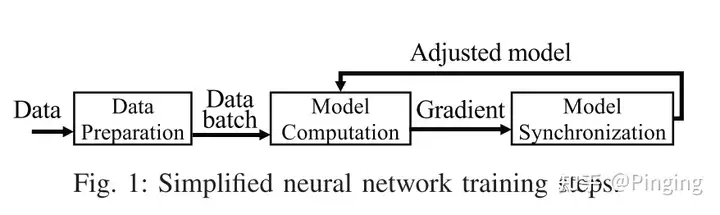
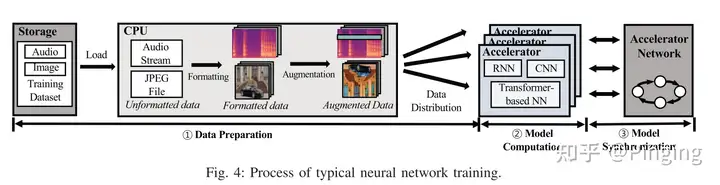
简单来说,模型的训练包括前期的数据准备以及后面的模型梯度更新。数据准备阶段包括数据从底层存储介质读取+数据在CPU中进行增强。之后传入GPU中进行模型训练。
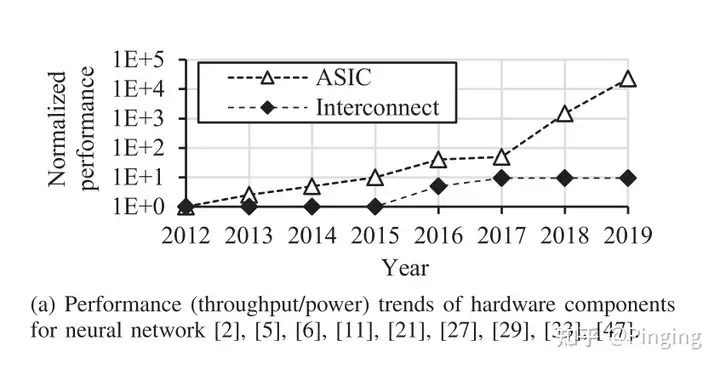
随着AI技术的发展,其迎来了黄金的时代。之前的AI系统研究更多的是关注计算模块,想尽一切办法让计算更快,而随着计算设备能力的增强(加之分布式训练模式的普及),AI训练逐渐从计算向着其他瓶颈迁移。例如下图所示,随着技术的更新,用于计算的ASIC越来越快,而网络互连的进步却很有限,逐渐拉开差距。同样,该趋势适用于数据增强。
我们再来看一个趋势:

上图展示了当前的训练瓶颈逐渐由模型参数更新转移到数据预处理。其中Current表示最基本的训练方法,没有使用比较先进的设备或者优化手段。能够看出此时的数据处理并没有占据很高的比例。随着使用了更多的强劲GPU以及更快的网络互连,计算部分越来越小,使得数据处理部分逐渐成为了瓶颈。而这个问题是实实在在存在的。
这里提供一个数据:当DNN服务器配备了256个训练加速卡后,CPU核数,内存带宽以及PCIe的带宽分别需要扩展50,7.6以及7.1倍才能不拖计算的后腿。
于是本文通过数据预处理与网络两个角度设计新的方案对DNN训练进行优化。
二、动机
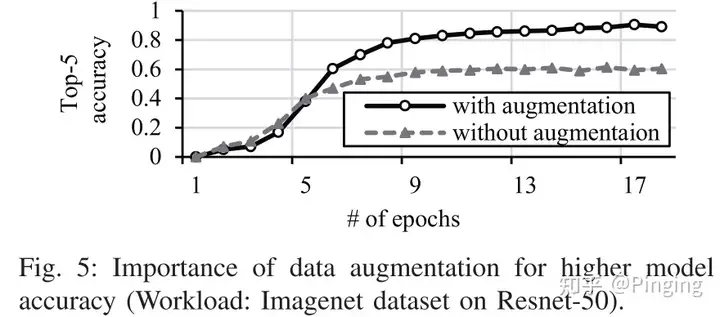
- 为什么要有数据增强?下图表明没有数据增强的话DNN的精度会下降非常多。
- 数据准备过程具体花费多少时间?
下图给了一些DNN训练过程中的时间Breakdown分解图,该图用数据阐述了数据准备是瓶颈这个事实-即最高有98.1%的时间都花在了数据准备过程。
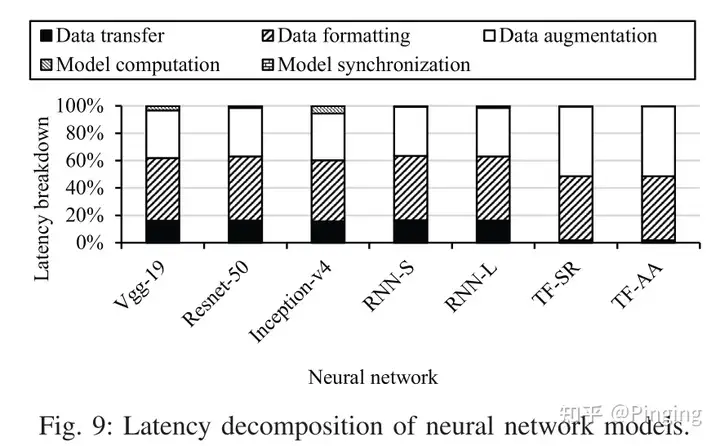
- 现有DNN训练架构是什么样?
如下图所示,现有DNN计算与存储设备由PCIe以及NVLINK互连到一起,并组织成树状结构。
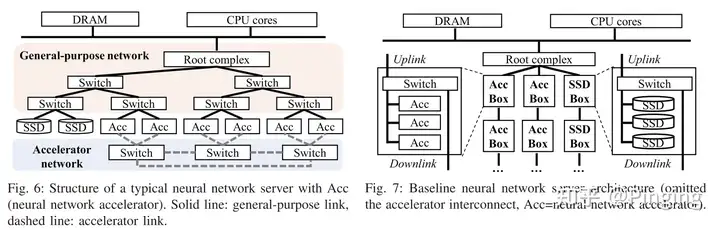
- 资源都到哪里去了?
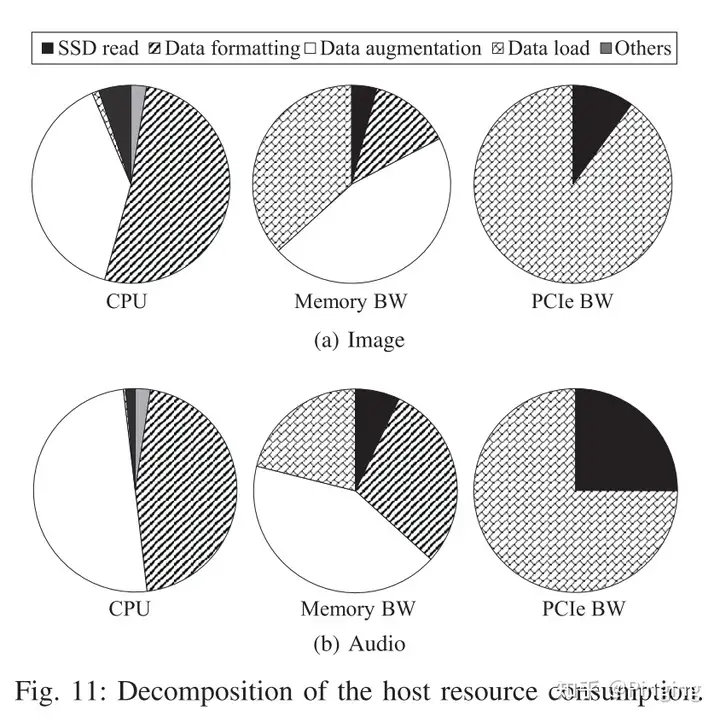
下图展示了系统资源的具体去处,a图是图片应用,b图是视频应用。对于CPU应用来说,数据增强以及数据格式处理占据了大部分CPU资源。大部分内存用到了数据读取以及增强过程,而PCIe的带宽主要用于数据IO。
三、设计思路
通过问题分析,我们发现,传统架构下的DNN训练的网络瓶颈来源于数据传输间的争用,而数据增强过程的瓶颈来源于低效的CPU操作。为了解决这两个问题,这个文章提出了TrainBox,既然大的池子间会有数据传输的冲突,所以干脆我资源耦合化,数据仅仅在小范围传输,不要传太远的路程。
此外,对于数据增强部分,由于CPU的计算能力有限(并行性也不够高),所以该文章提出了使用FPGA加速器来加速数据增强。
下面概述一下这个过程:TrainBox设计了新型架构从而打破了传统架构的局限性。如下图所示,图12显示,各种组件都需要传递数据到RC(即传输到同一个网络路径)上,产生了CPU瓶颈、DRAM带宽争用以及网络带宽的的争用。
解决CPU瓶颈问题:文章使用硬件加速器(FPGA)来加速数据预处理阶段。由图13所示,文章将各种FPGA组件设计为预处理计算单元,而不是CPU。用此方法,系统避免了大量的CPU对DRAM访问,也解放了CPU的工作,用更快速的FPGA也加速了预处理效率。
解决DRAM带宽争用问题:DRAM带宽的消耗来源于两个方面(1)来源于CPU在数据增强的过程中对内存的访问;(2)来源于数据从底层磁盘读取到DRAM(做一个buffer);图12的FPGA方案优化了1中的内容,然而目前数据仍会从磁盘读到DRAM中,并由FPGA访问DRAM,读取延迟仍然没办法解决。因此,本文提出了第二个方案来解决buffer对DRAM带宽的消耗。作者使用PCIe的 P2P特性,将磁盘的数据直接传到FPGA中。通过这种方案,由图14可知,就可以不用经过DRAM,也就不需要Buffer过程的带宽占用。
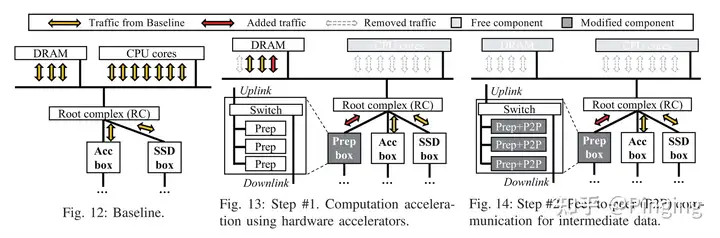
网络争用问题:经过上述两种优化,虽然解决了CPU以及DRAM带宽的问题,但是网络争用却更严重了。现在的Flow为:SSD->RC->FPGA->RC->GPU加速器;而原来只有SSD->RC->GPU(因为把预处理的部分下移了,所以传输都走RC了)。为了解决这个问题,本文选择的系统哲学是将通信本地化。由下图所示,将SSD、Acc以及FPGA放到一个Box里。相当于专用化起来,这样数据就在局部传输而避免了频繁的远端传输。
但是这样会引入一些问题,比如如果FPGA的预处理跟不上Acc的速度怎么办?又会造成瓶颈。所以本文又使用以太网交换机将FPGA连接起来,这样就可以使用远端的FPGA帮助进行预处理操作(用别人剩下的资源),加速预处理过程。
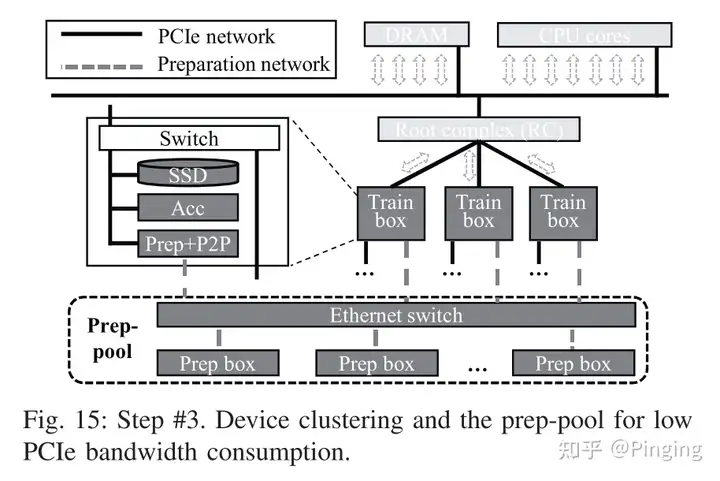
下图阐述了实际搭建结构图,其中TrainBox Rack集成了多个Train box,而每个box里面集成了SSD,并用Swith连接了多个Acc以及FPGA。
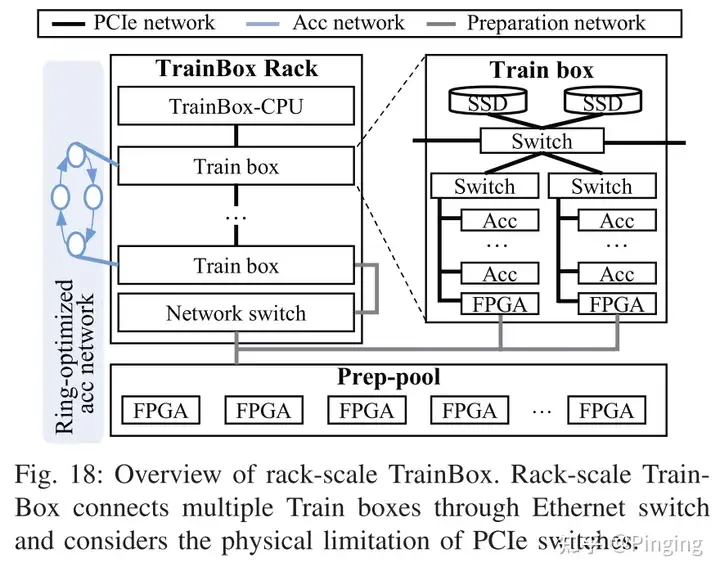
当然这个系统结构设计我认为终究是一种平衡,适用于某些场景但是真正的实用性还值得商榷。我们可以在末尾进行一些分析。
下面放几个效果图:
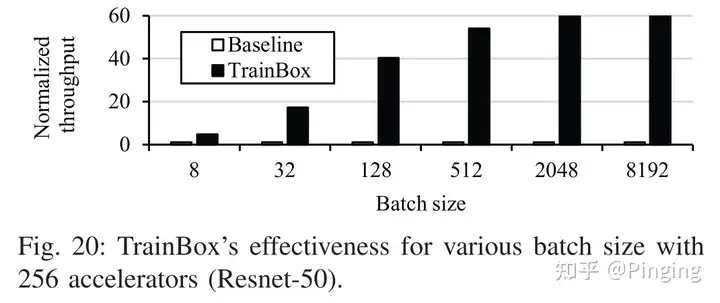
能看出来,这种架构确实是能够提升DNN训练的吞吐。另一些图(因为篇幅就先不展示)也说明了这种方案的可扩展性非常好。提升的原因就是因为CPU、Memory均得到了加速,瓶颈问题被解决了,并且这种方案能够按需去FPGA池子中获取增强资源,随着训练加速器数量的增多,增强能力也随之增加,扩展性更好(CPU的计算能力太弱,对可扩展性不友好)。
四、架构讨论
惊喜的是这是一篇比较出新的耦合架构方向的文章。虽然他没点出耦合架构,但是能看出来,他尝试将多个设备组件拼接到一个local环境下,用此方法避免数据传输过程中对资源的争用, 为的就是解决解耦的缺点。
解耦能提升资源利用率,部署更方便。然而对于性能层面,解耦并不一定能发挥优势,尤其是对于单个任务或者少量任务。所以面向这种场景,就可以考虑是否将设备进行部分耦合设计。所以,之前大热的解耦方案并不一定适用于所有场景。
我个人认为,本文将资源打散,分配到各个组件中,并用local的互连手段相连,类似于整机的方法部署系统,有点类似于时代的倒退。不过他针对增强瓶颈,又使用了FPGA池化,整个过程可抽象为部分资源解耦,部分资源整机部署。这种方案也为我们后期的研究提供了思路,取其精华去其糟粕。
不过这种架构未来是否有市场呢?我觉得是看业务场景的。如果针对AI专用的场景进行这种结构的搭建是非常有必要的。但是针对AI的特征,这种训练架构也引入了一些问题:(1)训练数据不可避免的会存放到多个SSD中(除非复制多份到每个box里),这样又退化成了远端读取,搞不好网络传输会更慢;(2)这种耦合系统不可避免的会有资源利用率不高的问题,比如某些box里的Acc不够用,有些Acc却用不完等。所以这种架构我们可以更深入的考虑将各种资源也做备用池化操作。训练时优先整机架构,迫不得已可退化为池子进行使用。

