AI大模型关键时间点,这些时间点要把握好机会

人工智能(AI)技术在最近几年发展非常迅速,其中一个重要的趋势就是研究和开发AI大模型。AI大模型是一种通过训练和优化来提高AI性能的技术。它主要适用于自然语言处理(NLP)和计算机视觉(CV)领域。
与传统的小型AI模型相比,大型AI模型具有更高的复杂性和能力。这些模型通常有数百万,甚至数十亿的参数,可以模拟更多的数据和场景。此外,大型模型还可以针对不同的任务进行微调,以获得更好的性能。
AI大模型的主要优势是可以提高计算机视觉和自然语言处理任务的准确性。例如,使用大型语言模型(如GPT-3)可以执行更自然的文本生成和理解任务。类似地,使用大型视觉模型(如ImageNet)可以识别更精细和复杂的图像。
然而,AI大模型也存在一些挑战。首先,它们需要大量的计算资源来进行训练和推理,这使得它们在大多数计算机上无法实现。其次,它们需要许多数据来训练和优化,这可能会导致隐私和安全问题。
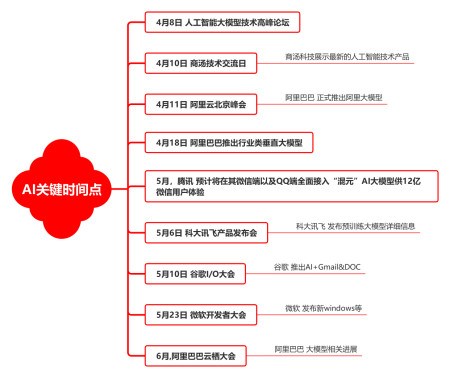
总的来说,AI大模型是AI技术的重要发展趋势之一。它们可以提高AI任务的准确性,但也需要解决计算资源和数据隐私等问题。在未来,我们可以期待看到更多的AI大模型被应用到现实生活中,以提升人们的生活品质。
-
上一篇
 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
今天的演讲主要介绍我们公司做的开源软件 Colossal-AI 的一些技术原理和应用。
首先简单介绍一下我本人。我在加州大学伯克利分校获得博士学位,现在在新加坡国立大学任教,同时创立了潞晨科技。公司另外一位核心成员 James Demmel 教授是美国科学院工程院院士,也是加州大学伯克利分校前计算机系主任兼院长。
今天的演讲分四个部分。第一部分简单介绍大模型的挑战以及目前 Colossal-AI 社区的发展情况,接下来两个部分介绍一些技术细节,最后一部分介绍具体应用上的效果。
首先给大家展示一张图:横坐标是时间,纵坐标是 AI 模型的参数量。过去六年中,最好的 AI 模型参数量已经上升了 1 万倍左右。
比如,2016 年 ResNet-50 只有 2000 万参数,2020 年 GPT-3 已经达到 1750 亿参数的规模。据说 GPT-4 也是用的混合专家系统,跟谷歌 Switch Transformer、智源的「悟道」都是同一种技术。Switch Transformer 参数规模大概 1.6 万亿,据说 GPT-4 有 16 个专家(模型),每个专家(模型)有千亿左右(参数)。
所以说,过去六、七年 —— 从 ResNet-50 到 GPT-4—— 最好模型的参数量刚好大了 10 万倍左右。
但是,以 GPT-3 为例,模型构造没有到 100 层,ResNet-50 也是 50 层左右,层数基本上没变化,模型不是变得更深而是变得更宽,大了 1-10 万倍左右,也给 GPU 内存造成更大压力,但 GPU 内存每 18 月只增长 1.7 倍,这就需要对下一代人工智能基础设施进行优化或者重建。
所以,我们打造了 Colossal-AI 系统。这是 Colossal-AI 系统结构图,包括三个层次。
第一个层次是内存管理系统,因为大模型太吃内存。
第二部分是N-Dim 并行技术(N 维并行技术)。据说 OpenAI 已经用 10 万张 GPU 卡训练大模型。前两天一家美国创业公司融资了 13 亿美金,背后基础设施据说已经有 2 万张 GPU 卡。未来,从 1 个 GPU 到 10、100、10000 个 GPU ,自动扩展效率会对训练系统产生根本性影响,所以我们打造了 N 维并行系统。
第三部分是低延迟的推理系统,也是目前 Colossal-AI 的主要模块。模型训练好后要服务用户,用户每调用一次模型就是做一次推理,这跟成本有直接关系。所以,推理的延迟要很低,成本要降到最低。
虽然 Colossal-AI 开源社区只推出了 20 个月左右,但发展速度非常快。(下图)横坐标是时间,纵坐标是 GitHub 上的星数,可以看出 Colossal-AI 增长速度远超于传统开源软件。
Colossal-AI 增速也远超与 Colossal-AI 类似软件,比如 DeepSpeed。
目前 Colossal-AI 用户遍布全球。中国、美国、欧洲、印度、东南亚都有很多用户。在全球 AI 生态系统中也都发挥了更重要的作用。
WAIC2023新加坡国立大学尤洋教授:AI大模型的挑战与系统优化
-
下一篇
Hao老师
如何快速训练自己的AI大模型?丨多模态学习