AI模型生产全流程介绍--模型部署那些事
初衷
刚进入AI这个行业时,我一脸懵逼,完全不懂各种 AI模型生产过程的各种专有名词,更不要说明白这个过程,在网上目前也很少有资料是站在给技术小白的角度将AI模型生产的整个过程讲明白,更多的是在各个具体的环节的技术的讨论。而这对于一个新入行的同学或者说非技术的同学来看,想了解整个AI模型生产流程的模型部署过程是一件非常痛苦的事情,所以想从自己入门以来所了解的相关内容做个串联,希望可以将这个过程讲明白,也给自己的学习过程做个沉淀,后续更好的支持业务~
本篇内容会有什么样的内容?
- 首先本篇内容完全不涉及到具体技术的讨论。
- 介绍整个AI模型生产的全流程
- 模型部署的流程介绍
概念解释:模型? 算法? 网络?
AI模型特指使用神经网络作为参数结构进行优化的最终具有一个特定作用的模式。 不知道大家在刚开始接触AI模型概念时,是否有这样的疑惑,模型,算法和网络经常是混着出的,而经常好像是互相替换使用的。而下面关于网络,模型和算法的概念是我认为讲的比较清楚的。
- 网络: 一种简单的网络结构,不包含任何权重参数。
- 模型: 设计一个网络后,在某些数据集上进行训练,得到一个包含权重参数的数据,称为模型。
- 算法: 在模型的基础上通过一些代码具体实现某些相关目的,这些代码以及模型文件等等资源被称为某算法。
AI模型生产处于AI产业图谱的哪个位置?
AI(Artificial intelligence:人工智能)是指可模仿人类智能来执行任务,并基于收集的信息对自身进行迭代式改进的系统和机器。人工智能产业图谱可参考下图。
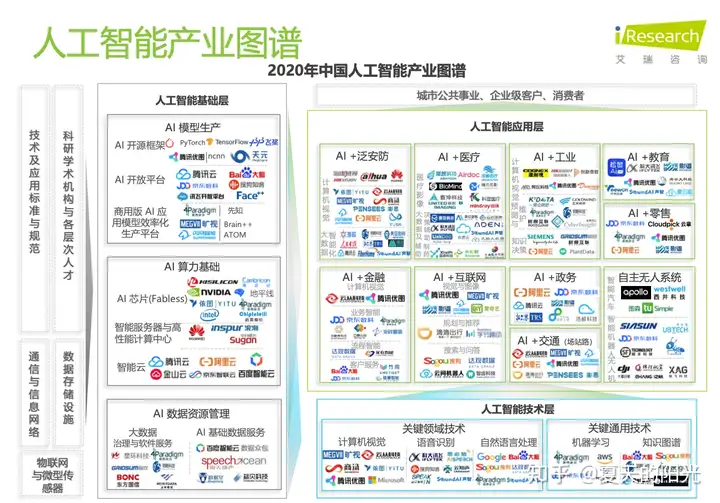
我们一般接触到更多的与AI相关的内容更多是在人工智能应用层。例如:人脸识别功能,智能语音对话功能,无人零售等。这些都是具体的AI技术在实际行业中的应用。这些AI技术一般又会分为:人工智能又可以分为计算机视觉(CV)、语音识别、自然语言处理(NLP)以及现在很火的知识图谱等。比如人脸识别属于CV技术领域。而这些AI技术的应用,都离不开具体的AI模型。AI模型生产过程属于人工智能的基础层,是上层这些应用的基础。AI基础层 = 算法(AI模型)+ 数据 + 算力。
AI 模型生产流程过程
生产一个具体的AI模型都会有哪些步骤呢?我们以一个具体例子来串起整个过程。我希望能达到的目的是:输入一张影视明星的图片,可以帮我输出这个明星的名字。而AI模型生产流程可以分为一下6个步骤:

1、确定目的:首先你要明白AI只是一个技术,是帮助你实现一些你想要的功能的工具。所以第一步,要清楚知道你希望通过AI来解决什么问题?商业目的是什么。才能知道需要寻找哪块的AI技术和开发思路。而我希望达到的目的是:输入一张影视明星的图片,可以帮我输出这个明星的名字。分解下这个需求:其实是一个简单的图片分类的问题。而图片分类属于计算机视觉里面的一个具体场景。2、准备数据数据准备主要是指收集和预处理数据的过程。按照确定的分析目的,有目的性的收集、整合相关数据,数据准备是AI开发的一个基础。此时最重要的是保证获取数据的真实可靠性。而事实上,不能一次性将所有数据都采集全,因此,在数据标注阶段你可能会发现还缺少某一部分数据源,反复调整优化。

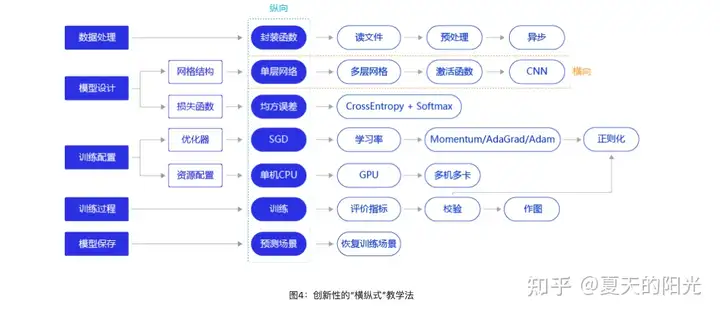
而在这个例子中,首先你需要从网上下载大量的明星的图片(所有你想识别的明星的相关的图片),此时你获得的是大量不规则的图片数据,可以图片的大小,格式都不一样;之后你需要针对这些数据进行处理:包括数据标注(该例中需要将每张图片都标记成所代表的明星),图片的标准化(相同大小和格式),还有数据清洗等(可能下载了些不是明星的图片,将其去掉),此时你得到了一个标准的数据集;之后的步骤不是必要的,如果你的图片比较少,可以通过裁剪,旋转等手段,将图片丰富一下,也可以提高后续模型的正确性,因为可能输入的图片是一张倒着的图片。3、模型设计 & 算法选择模型网络结构设计,相当于模型的假设空间,即模型能够表达的关系集合。其过程是假设一种网络结构后,设计其评价函数(Loss),然后寻找优化寻解方法。其实现在的AI业务都无需从头开始模型结构设计,因为目前有各种优秀的AI大佬们设计出各种经典的算法解决实际中某类具体问题。例如解决图像分类问题的算法就有:AlexNet、GoogleNet、ResNet、MobileNet、ShuffleNet、VGG等经典算法。所以现有的模型结构设计一般是选择具体的某种算法,而且算法的具体实现,现有也有很多开源的算法库已经提前帮大家实现提前好。目前模型设计更多是一种算法选择,选择适合自己业务的算法,进行结构微调。目前计算机视觉领域的开源算法库有OpenMMLab,Transformer的开源算法库Hugging face。在影视明星识别问题,其实是一个图像多分类问题,我们可以选择图像分类的算法。4、训练、评估模型除了数据和算法外,更重要的是在模型参数设计上。模型训练的参数直接影响模型的精度以及模型收敛时间,而且参数的选择极大依赖于开发者的经验,参数选择不当会导致模型精度无法达到预期结果,或者模型训练时间大大增加。所以大家才会调侃算法工程师是调参师。训练模型的结果通常是一个或多个机器学习或深度学习模型,模型可以应用到新的数据中,得到预测、评价等结果。训练得到模型之后,还需要对模型进行评估和考察。往往不能一次性获得一个满意的模型,需要反复的调整算法参数、数据,不断评估训练生成的模型。一些常用的指标,如准确率、召回率、AUC等,能帮助您有效的评估,最终获得一个满意的模型。目前市面上有各类开源的训练框架可供大家选择。例如:Pytorch、TensorFlow、MxNet、Caffe、PaddlePaddle等等。在这个例子中,图片分类这个场景中模型评估标准就是准确率,就是给模型一张标注好的王一博的照片,模型的预测结果应该是王一博,而不是其他明星。下面的过程是百度PaddlePaddle教程里展示的数据处理到模型保存过程的流程。
5、模型部署模型训练好之后,就到了AI模型实际应用的最后一环 --- 模型部署。模型部署是将已经训练好的模型,部署到实际的应用场景中,所以模型部署更多是工程化的过程,就是解决实际的模型应用问题。模型部署的流程如下:
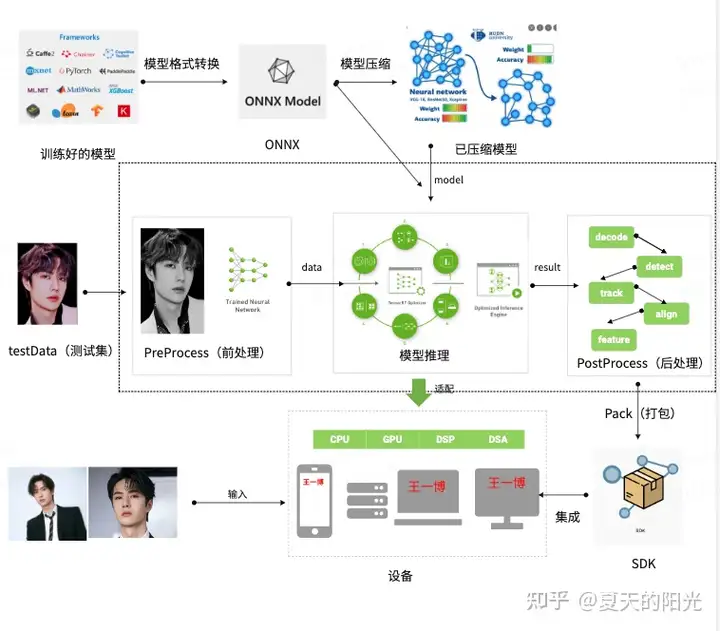
1、模型格式转换首先研究员通过各种训练框架训练好的模型一般都需要进行模型格式适配。模型训练大家可以选择各种不同的训练框架,例如TensorFlow,Pytorch,PaddlePaddle,Caffe等等一系列的开源框架,这么多不同的训练框架他们训练出来的模型格式都有各自的标准,各不相同,部署要解决的第一个问题就是要适配各种不同的模型格式。但是如果要一个个训练框架去适配格式,工作量太大,也不适合扩展,所以微软联合Facebook等大厂推出一种中间格式ONNX,希望能解决多种模型格式适配的问题,就是无论是什么训练框架训练出来的模型格式,最终都是用ONNX格式来进行部署。所以一般模型部署可以跑的第一步要解决的问题就是模型格式转换。
2、模型压缩模型压缩是对已经训练好的深度模型进行精简,进而得到一个轻量且准确率相当的网络,压缩后的网络具有更小的结构和更少的参数,可以有效降低计算和存储开销,便于部署在受限的硬件环境中。训练的时候因为要保证前后向传播,每次梯度的更新是很微小的,这个时候需要相对较高的精度,一般来说需要float型,如FP32,32位的浮点型来处理数据,但是在推理(Inference)的时候,对精度的要求没有那么高,很多研究表明可以用低精度,如半长(16)的float型,即FP16,也可以用8位的整型(INT8)来做推理(Inference)。所以,一般来说,在模型部署时会对模型进行压缩。模型压缩方法有:蒸馏,剪枝,量化等。
3、模型推理和前后处理前处理:因为模型推理的输入是Tensor(多维矩阵)数据,但是正常AI应用的输入都是图片,视频,文字等数据,所以前处理就是要将业务的输入数据(图像,视频,文字等)预先处理成模型推理可以接收的数据---Tensor(多维矩阵)。以图像处理为例,前处理动作就包括但不限于:图像格式转换,颜色空间变换,图像变换(resize,warpaffine(仿射变换)),图像滤波等操作。OpenCV就是intel推出开源的跨平台的计算机视觉库。https://github.com/opencv/opencv模型推理:模型推理应该是模型部署pipline中最核心的部分。就是需要在实际应用环境中(具体部署设备)将实际输入的数据(转换成Tensor数据后)在训练好的模型中跑通,并且性能和精度等商业指标上达到预期效果。这个过程包括了对部署设备的适配(CPU/GPU/DSP/NPU),要想将模型跑在任何一种设备上,都需要提前针对设备进行适配,并且还要保证性能和精度等指标。这是个非常复杂的过程,后续希望出文章详细介绍。市面上有非常多的开源深度学习推理框架都是在解决模型推理相关的问题。例如:国内各大厂推出的开源的推理框架:OpenPPL、NCNN、TNN、MNN、PaddleLite、Tengine等等,还有NVIDIA推出的针对GPU卡的TensorRT、intel针对intel芯片的OpenVINO等。后处理:就是将模型推理后的Tensor数据转换成业务可以识别的特征数据(不同的业务会呈现不同的最终效果数据)。
总结下:模型推理和前后处理的流程:
- step1:PreProcess(Image -> Tensor)
- step2:NN Forword/Inference(Input Tensor -> Output Tensor)
- step3:PostProcess(Output Tensor -> Annotation Data)。
4、部署 SDK 和集成部署SDK:需要模型推理和前后处理功能打包,并考虑实际应用中的license、模型安全(加解密)等功能实现,最终输入一个业务方方便使用的部署SDK。这是一种单机模式的部署,现在大型模型部署和公有云部署可能是另一种形式。集成:由具体的业务方工程化的同学去实现,将部署SDK集成到具体的应用中,根据实际业务需要通过接口调用,最终达到实际应用AI的效果。例如:上述例子中,具体是要将部署SDK集成进手机端还是pc端,是通过app来实现还是小程序来实现,最终效果如何展示,这些都是集成部分具体业务同学去实现。整个AI模型生产的全流程就介绍完了,没有很多高深的技术讨论,只是将整个流程串起来,让大家对AI的模型生产过程有一个全面的认识。如有错误,欢迎指正!

全国最大的AI模型社区,阿里推出大杀器:AI可调用所有大模型
在人工智能进入千模大战白热化之际,一些玩家开始另辟蹊径,想做大模型背后的代理人。这种智能Agent模式也被称作大型模型调用器。

创建生成式AI团队,训练AI大模型
原标题:创建生成式AI团队,训练AI大模型