ChatGPT在萨摩耶云科技集团场景应用实践及探索
原标题:ChatGPT在萨摩耶云科技集团场景应用实践及探索
一、背景和需求
随着ChatGPT的流行,各行各业都在思考对话机器人在各自领域的应用,国内各大AI公司也在开始行动,研发自己的ChatGPT,萨摩耶云科技集团作为一家AI决策驱动的公司,在信贷和跨境电商等领域积累了丰富的经验,在信贷营销,信贷客服,风险控制,代码编写,跨境电商内容生成等业务场景中都有和ChatGPT结合的业务场景。
本文将详细介绍ChatGPT的技术原理和使用方案,同时简要介绍在信贷营销和客服,跨境电商AIGC等场景的一个实现探讨。
二、ChatGPT的技术原理
1、语言模型的定义
语言模型可以理解为给定一些字或者词,预测下一个字或者词的模型,这里的字或者词在 NLP 领域通常也被称为 token,即给定已有 token,预测下一个 token 。训练语言模型基本不需要人工标注数据,比如以I have a dream为例,它可以被拆解为:
| 训练数据 | 标签 |
| I | have |
| I have | a |
| I have a | dream |
数学化地描述就是,给定一个句子,比如 ,语言模型其实就是想最大化:
其中 k是文本窗尺寸,条件概率P采用参数为Θ的神经网络建模。
2、语言模型的发展历程
2003年 Bengio 发表了论文《A Neural Probabilistic Language Model》,用了一个三层的神经网络来构建语言模型(NNLM),开启了神经网络语言模型的历程。2013年谷歌发表了论文《Efficient Estimation of Word Representations in Vector Space》,同时开源了word2vec工具,能够高效的生成词向量,在NLP领域获得了大量关注。2018年Allen人工智能研究所发布了论文《Deep contextualized word representations》,提出了ELMO,解决了word2vec只能生成静态词向量的问题,能够很好应对一词多义场景,并能包含上下文语境。但是ELMO受限于LSTM的遗忘性质,在特征抽取能力上仍有待提升。之后随着谷歌采用引入了自注意力机制(Self Attention)的Transformer方式构建深度网络,超强的语言特征抽取能力,使得 NLP 开启了 Transformer 的时代。
2018 年 OpenAI 采用 Transformer Decoder 结构在大规模语料上训练了 GPT1 模型通过使用预训练模型+微调的训练模式出色地完成了各种特定的NLP任务,并于随后 2019 年提出了 GPT2,GPT2 拥有和 GPT1 一样的模型结构,得益于更高的数据质量和更大的数据规模以及创造性的引入多任务学习模式,能够完成包括对话、翻译等各种NLP任务。但是由于 GPT 采用 Decoder 的单向结构天然缺陷是无法感知上下文,Google 很快提出了 Encoder 结构的 Bert 模型可以感知上下文,效果上也明显有提升,同年 Google 采用 Encoder-Decoder 结构,提出了 T5 模型。从此大规模预训练语言模型分成三个分支开启了后续的一系列研究。
直到2020 年 OpenAI 提出 GPT3 将 GPT 模型提升到全新的高度,其训练参数超 1750 亿,训练语料达到了45TB之多,开启了超大模型时代,并在预训练+微调的基础上创造性的引入了情境学习模式,将人为提示作为语料输入。由于 GPT3 可以产生通顺的句子但是准确性等问题一直存在,2021~2022年期间出现 了InstructGPT、ChatGPT 等后续优化的工作,通过引入强化学习模式实现了模型可以理解人类指令的含义,会甄别高水准答案,质疑错误问题和拒绝不适当的请求等。
3、GPT-1/2/3介绍
GPT-1
GPT的全称叫Generative Pre-trained Transformer,是一个生成式的预训练语言模型,分成了两个阶段进行训练:
第一阶段:无监督预训练,这个阶段GPT 使用了一个多层的 Transformer Decoder作为语言模型,其网络结果如下:
其中,是tokens的文本向量,n是网络层数,是token嵌入矩阵,是位置嵌入矩阵。有了模型结构和开始提到的L1目标函数,就可以训练出一个初步的大语言模型。
第二个阶段:监督微调,在第一阶段训练出一组模型参数后,第二阶段会利用一些有标签数据进行微调。假设输入为 ,标签为 ,则模型会在之前输出层的基础上再叠加一个线性层作为最终的输出:
目标函数为:
GPT会同时考虑语言模型的自回归目标函数以提升改进监督微调模型的泛化能力和收敛速度,于是目标函数优化为:
在微调阶段,需要的唯一额外参数是 ,以及分隔符标记的嵌入。下图展示的就是 GPT 做微调时对文本的一些常见做法,其实就是拼接和加分割符之类的操作。
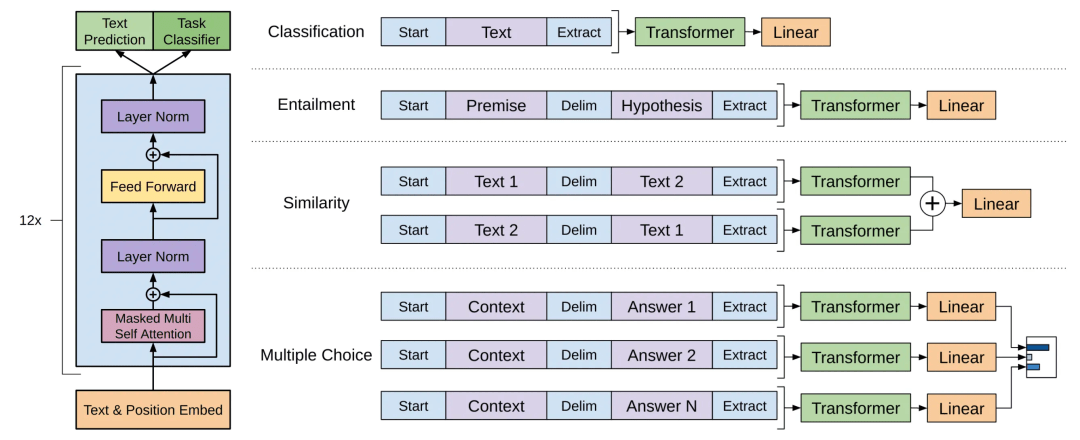
2018年,OpenAI发布了1.17亿参数的GPT-1,使用的数据集主要是一些书籍类的语料。
GPT-2
GPT-1 依赖有标签数据进行监督学习,只能对单一任务进行处理,,而 GPT-2则引入了多任务学习的概念,它在预训练时考虑了各种不同的任务,更加的通用化。因此,GPT-2 的模型从原本 GPT-1 的:
改为 task conditioning 的形式:
也就是把任务也作为模型的输入,具体的做法是引入一些表示任务的 token,比如:
- 翻译任务
input:china
task: [翻译为中文]
output:中国
- 问答任务
input:我是XXX
task1: [问题] 我是谁
task2: [答案]
output:XXX
上面例子中 [翻译为中文]、[问题] 、[答案] 这些就是用于告诉模型执行什么任务的 token。通过这样的方式,各种任务都能塞进预训练里进行了,想学的越多,模型的容量自然也需要更大,2019年,OpenAI发布了拥有15亿参数的语言模型GPT-2。
GPT-3
GPT3 可以理解为 GPT2 的升级版,OpenAI于2020年发布,使用了 45TB 的训练数据,拥有 175B 的参数量,真正诠释了什么叫大力出奇迹,语料也更加丰富,包含了维基百科,书籍,杂志期刊,Reddit链接,网站爬取,GitHub代码等等各种类型。
GPT3 主要提出了两个概念:
- 情境学习:就是人工对模型进行引导,教会它应当输出什么内容,比如翻译任务可以采用输入请把以下英文翻译为中文:I hava a dream,这样模型就能够基于这一场景做出回答,跟GPT2多任务Token思路一致,只是表达更加拟人化。
- Zero-shot, one-shot和few-shot:通过不使用一条样例的 Zero-shot、仅使用一条样例的 One-shot 和使用少量样例的 Few-shot 来完成推理任务,比之前的微调模式更进一步,直接在原始语料中进行植入,具体如下图所示:

图片来自于论文《LanguageModels are Few-Shot Learners》
- ChatGPT的训练步骤
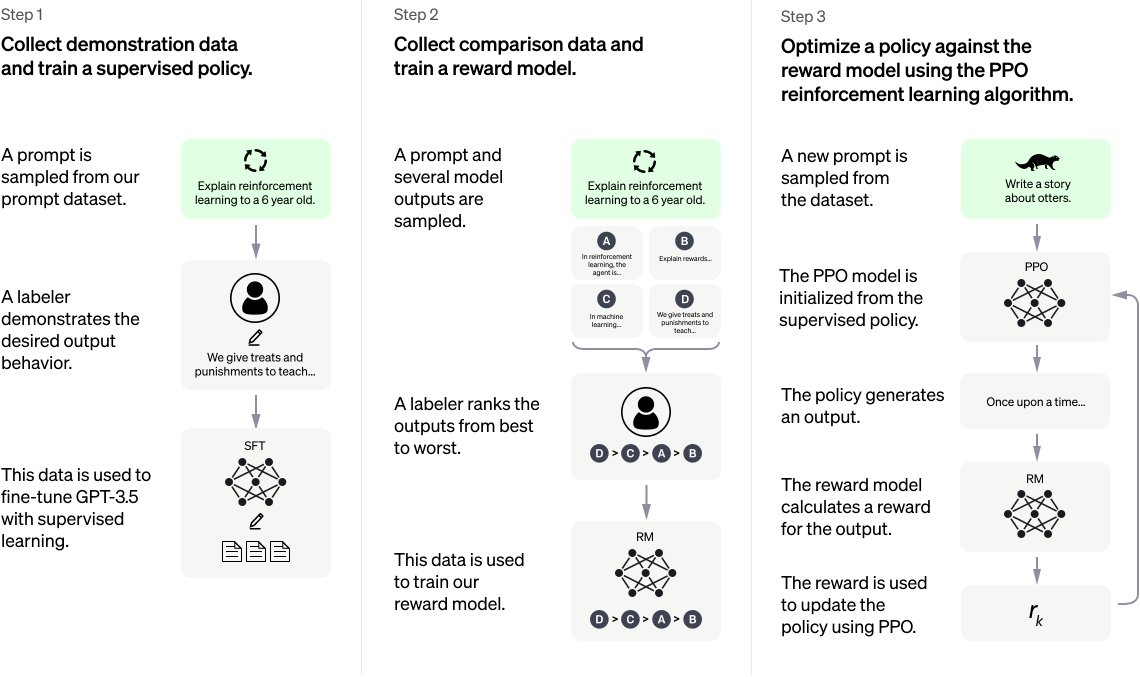
图片来自于OpenAI官网
根据OpenAI官网介绍,ChatGPT使用了RHLF( Learning from Human Feedback)方法来对模型进行训练,它分三步来进行:
第一步:基于 GPT3.5 模型进行微调。从用户的 prompt数据集合中采样,人工标注 prompt 对应的答案,然后使用标注好的 prompt 和对应的答案去微调GPT3.5,经过微调的模型已经具备在对话场景初步理解人类意图的能力。
第二步:训练奖励模型。第一步微调的模型不知道自己答的好不好,需要通过人工标注的答案比较数据来训练一个奖励模型,从而让奖励模型来帮助评估模型生成的回答好不好。具体做法是采样用户提交的 prompt以及让第一步微调的模型生成 n 个不同的答案,比如 A、B、C、D。接下来使用钞能力人工对 A、B、C、D 按照相关性、有害性等标准进行综合打分和排序。有了这个人工标注的答案对比数据,再采取 pair-wise 损失函数来训练奖励模型 ,使得模型就具备了判别答案的好坏能力。
第三步:使用PPO强化学习来增强第一步生成的微调模型。首先第一步使用监督策略微调 的GPT3.5 模型初始化 PPO 模型,采样一批和前面用户提交 prompt 不同的集合,使用 PPO 模型生成答案,使用第二步回报模型对答案打分,通过产生的策略梯度去更新 PPO 模型。这一步利用强化学习来鼓励 PPO 模型生成更符合奖励模型判别高质量的答案。
通过第二和第三步的不断迭代训练,使得 PPO 模型能力越来越强,直到人都很难分辨出来。
5、参考论文
GPT1论文:Improving Language Understanding by Generative Pre-Training
GPT2论文:Language Models are Unsupervised Multitask Learners
GPT3论文:Language Models are Few-Shot Learners
InstructGPT论文:Training language models to follow instructions with human feedback
RHLF算法论文:Augmenting Reinforcement Learning with Human Feedback
RHLF算法解读:Illustrating Reinforcement Learning from Human Feedback
PPO算法:Proximal Policy Optimization Algorithms
ChatGPT:Optimizing Language Models for Dialogue
Claude:Constitutional AI: Harmlessness from AI Feedback
三、ChatGPT模型的使用方案
1.方案一:自己训练
自己训练,ChatGPT当前没有开源,但是网上有一个开源的gpt-neox项目和ColossalAI项目,huggingface提供了transformer的库,可以基于这三个项目进一步的使用RHLF算法和PPO算法训练出一个自己的基于GPT的语言生成模型。
gpt-neox GitHub地址:https://github.com/EleutherAI/gpt-neox
ColossalAI GitHub地址:https://github.com/hpcaitech/ColossalAI
huggingface transformers GitHub地址:https://github.com/huggingface/transformers
- 准备训练数据:代码文本,其他文本等。
- 使用AutoTokenizer将数据集token化。
- 初始化GPT模型GPT2LMHeadModel
- 使用Trainer训练GPT模型
- 训练奖励模型,使其能够对前四步不同模型生成的文本进行打分
- 使用PPO算法训练一个智能体能够利用第五步的奖励模型生成符合意图的文本。具体可参考:
当然实际ChatGPT肯定比这复杂得多,训练成本和人工成本也是非常之高。
2.方案二:微调模型
基于OpenAI提供的模型微调接口使用自有数据集创建定制模型。
定制模型:https://platform.openai.com/docs/guides/fine-tuning
1.准备数据集:
准备如下格式的mydata.jsonl文件
{"prompt": " ", "completion": " "}
{"prompt": " ", "completion": " "}
{"prompt": " ", "completion": " "}
其中prompt text为输入项提问,ideal generated text为输出项回答。
2.上传数据集
上传:
POST https://api.openai.com/v1/files
openai.File.create( file=open("mydata.jsonl", "rb"), purpose=fine-tune)
查看:
GET https://api.openai.com/v1/files
openai.File.list
3.微调模型
POST https://api.openai.com/v1/fine-tunes
openai.FineTune.create(training_file="file-XGinujblHPwGLSztz8cPS8XY")
3.方案三:API调用
直接调用OpenAI接口,通过提供足够丰富的提示和多轮对话,使得GPT模型能够更加准确的回答问题。
接口调用:https://openai.com/api/
模型参数:
1)engine(模型名称):训练成的模型名称或直接使用text-davinci-002/text-davinci-003
2)prompt(输入提示):提问的内容,描述需要模型做什么事情
3)max_tokens(提示符标记长度):1024。提示符的标记计数加上max_tokens不能超过模型的上下文长度。大多数模型的上下文长度为2048个令牌
4)temperature(温度采样):0.5。[0, 1]区间,数值越大回答的多样性就越大
5)top_p(核采样):1。[0, 1]区间,数值越大回答的多样性就越大,有temperature就不需要top_p
6)frequency_penalty(重复性惩罚):0.2。[-2, 2]区间,正值会根据新标记到目前为止是否出现在文本中来惩罚它们,从而增加模型谈论新主题的可能性。
7)presence_penalty(频率惩罚):0.2。[-2, 2]区间,正值会根据新符号在文本中的现有频率来惩罚它们,从而降低模型逐字重复同一行的可能性。
- 三种方案对比
| 时间成本 | 资金成本 | 效果 | 安全 | |
| 方案一 | 1个月以上 | 涉及到大量GPU资源,每次训练超400万美金以上,还涉及大量人工成本 | 完全定制化,可本地化部署 | 合规,敏感信息不外泄 |
| 方案二 | 视数据集大小,小时到天级别 | 视数据集大小,一般几十到上万美元 | 对已有GPT模型的微调,只能在线调用,可定制化 | 涉及到敏感信息可能会外泄 |
| 方案三 | 无,随时可用 | 按量付费 | 不改变模型只是给模型尽量多的提示,只能在线调用,定制化能力一般 | 涉及到敏感信息可能会外泄 |
四、信贷营销和客服机器人的实现
营销和客服是信贷领域不可缺少的两个环节,当前萨摩耶云科技集团营销上有广告投放,短信,外呼,app推送,资源位个性化展示等各种渠道,客户服务则主要是微信公众号等渠道,通过实现营销和客服机器人,可以提升营销和客服效率,也可以进一步提升用户体验
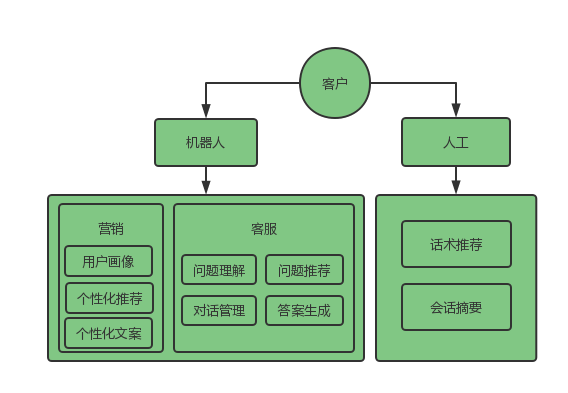
在营销或者客服过程中,客户的沟通对象可能有两个,机器人或者人工,因此营销和客服机器人涉及到的技术也主要包括两方面:
机器人层面,在营销上主要是基于用户画像的个性化推荐和个性化文案生成,在客服上主要是问题理解,对话管理,问题推荐,答案生成等四个方面。
人工层面,则主要是话术推荐和会话摘要生成,这个营销和客服场景都会用到。
实现上由于信贷领域的特殊性,对安全和合规要求较高,所以主要还是依赖于自己训练类似于ChatGPT的语言模型,再叠加个性化推荐模型,结合业务知识图谱以及业务流程API来实现,当然这个成本也会比较大,涉及到GPU训练和人工标注和数据准备,业务系统集成等的开销。
五、跨境电商AIGC的实现
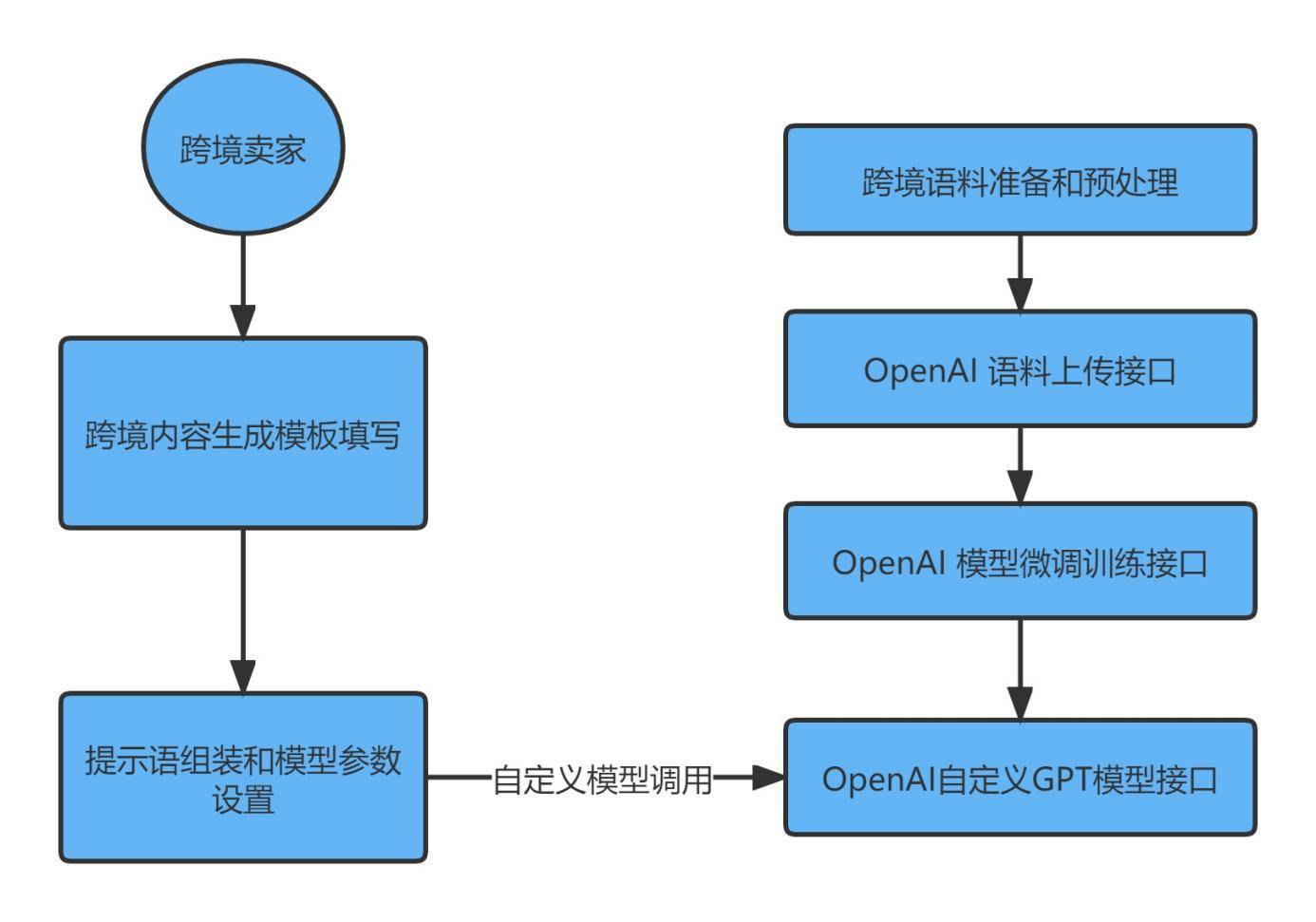
跨境电商AIGC,当前chatGPT在国内使用不方便,再加上chatGPT是通用模型,对于2021年以后的内容知道得比较少,因此虽然chatGPT可以直接帮助跨境卖家生成内容,但是效果还是需要进一步改进,OpenAI提供了对GPT模型进行微调然后生成自定义GPT模型的接口能力,而且跨境电商的语料在安全以及合规上限制不大,因此可以基于OpenAI提供的定制化能力来实现。
通过OpenAI提供的语料上传/模型微调/模型调用接口,可以上传自己的训练语料对GPT模型进行微调,达到定制化模型的效果,从而帮助跨境电商卖家提升英文内容编写效率和效果的目的。技术实现方案如下图所示:
未来,随着ChatGPT相关大模型,AIGC,AGI等技术的不断发展,将为识别、生成和决策重新赋能,对数字经济的发展可能会产生渗透性甚至颠覆性作用。如何应对人工智能会是件有意思的事情,但AI的未来肯定超酷。(文章来源:萨摩耶云科技集团易小华)
本网站上的内容(包括但不限于文字、图片及音视频),除转载外,均为时代在线版权所有,未经书面协议授权,禁止转载、链接、转贴或以其他 方式使用。违反上述声明者,本网将追究其相关法律责任。如其他媒体、网站或个人转载使用,请联系本网站丁先生:chiding@time-weekly.com

