OpenAI发布GPT-4,超预期还是低于预期?
原标题:OpenAI发布GPT-4,超预期还是低于预期?
原标题:Open AI发布GPT-4,超预期还是低于预期?
行业更新系列
北京时间3月15日凌晨,Open AI发布ChatGPT-4。ChatGPT Plus的订阅者可以付费获得具有使用上限的GPT-4访问权限。在发布中,GPT-4展现了更强的能力,如:
- 创造力:GPT-4比此前的版本更具创造性和协作性。它可以生成、编辑,并与用户一起迭代创意和技术写作任务,例如作曲、写剧本或学习用户的写作风格。
- 图片输入:GPT-4可以接受图像作为输入,并基于此生成标题、分类和分析。
- 支持更长的输入:GPT-4能够处理超过25,000字的文本,允许用例,如长形式的内容创建,扩展对话,以及文档搜索和分析等。
我们并不希望单纯对GPT-4的新能力进行罗列,而是希望谈谈我们眼中GPT-4相对于此前版本的一些值得关注的进步,以及我们的理解。
亮点1:多模态的输入方式
多模态的意义不仅在于场景拓展,也在于模型自身的能力提升。
- 多模态的输入模式有望使得AI的应用场景被进一步拓展。多模态能力是目前市场中对于GPT-4讨论最多的点,但讨论往往集中在多模态相对于单模态在应用场景拓展方面的潜力。比如,大模型的能力能否被引入一些处理图片的场景中,让目前的产品变得更强大。
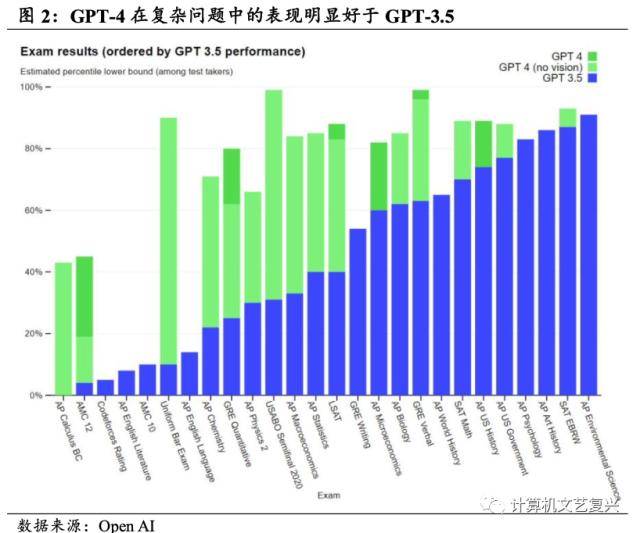
- 我们认为,除场景拓展外,同时值得关注的是多模态是否能够使模型本身的能力获得增强,并解决更为复杂的问题。如同人类感知世界的过程是通过输入文本、图片、视频等各类信息实现的,那么多模态能否使得模型本身获得更强甚至额外的能力值得关注。根据Open AI发布的结果,GPT-4在处理复杂问题时的表现明显好于此前的GPT-3.5。比如在模拟律师资格考试的任务中,GPT-4的分数落在前10%的考生中,而GP4-3.5的分数则落在了后10%。

亮点2:训练结果的可预测性
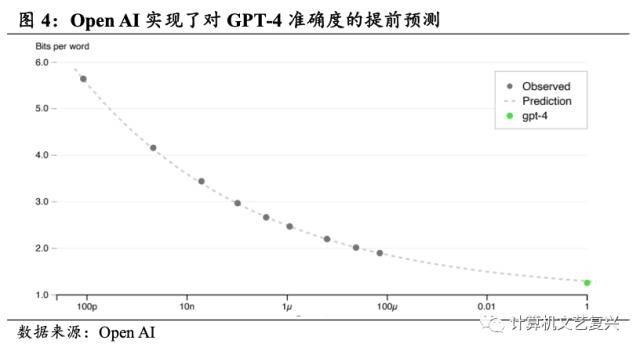
大模型的训练结果变得更可预测。根据Open AI的表述,GPT-4的一个重点是构建了一个可预测的深度学习堆栈,可以使用不超过GPT-4计算量千分之一的训练模型对GPT-4一些性能进行准确的预测。这使得我们能够在花费较少代价的情况下让AI模型的目标更符合人类的意图和价值观。一方面能够加快模型的迭代效率,毕竟针对特定模型进行广泛的调优是不现实的;另一方面,也有助于解决目前ChatGPT会生成一些对人类有害或者歧视性答案的问题。
亮点3:大模型能力来自于模型自身而非强化学习
模型能力似乎不受强化学习(RLHF)的显著影响。我们认为,这是GPT-4发布中另一个非常值得关注的点。
- GPT系列大模型中诸如推理能力等一系列能力是涌现出来的,目前对于这些能力是如何产生的并没有共识。一方面,ChatGPT确实表现出了一定的乌鸦智能(该比喻源自朱松纯教授,将乌鸦和鹦鹉对比,乌鸦具有理解能力,而鹦鹉的问答方式是鹦鹉学舌)。但另一方面,其技术路线是深度学习+强化学习(其中强化学习是指GhatGPT利用了人类的反馈信息直接优化语言模型)。那么,这些涌现出来的能力究竟是来源于大模型本身,还是仅仅是引入了强化学习后机器的回答更符合人的语言习惯而产生的表象?
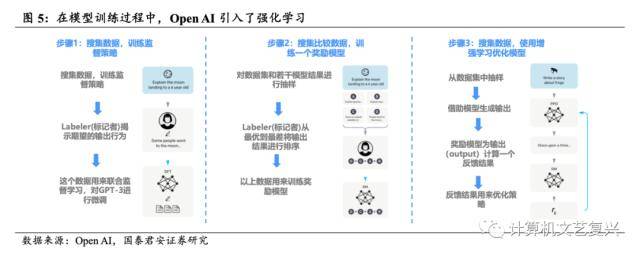
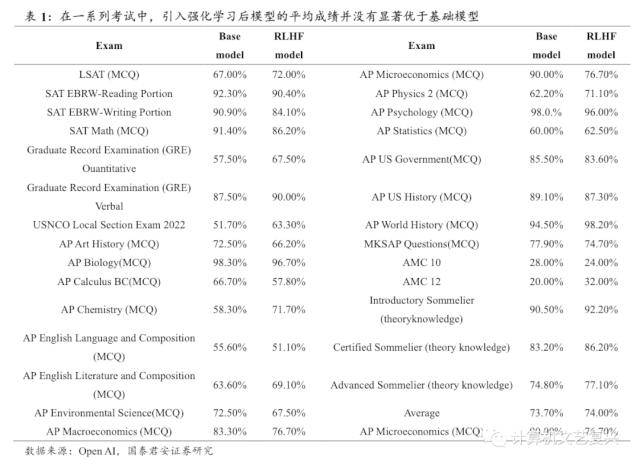
- 模型能力似乎并不来自强化学习。为了测试强化学习对于模型能力的影响,Open AI分别基于GPT-4基础模型和加入强化学习的GPT-4模型运行了一系列考试中的多项选择题部分。结果显示,在所有的考试中,基础的GPT-4模型的平均成绩为73.7%,而引入强化学习后的模型的平均成绩为74.0%,这意味着强化学习并没有显著改变基础模型的能力,换句话说,大模型的能力来自于模型本身。根据Open AI的表述,强化学习的意义更多地在于让模型的输出更符合人类的意图和习惯,而不是模型能力的提升(有时甚至会降低模型的考试成绩)。