国内首个ChatGPT检测器发布,它是如何区别人类与AI的?我们还能做什么?
作为之前还停留在预训练模型时代 的 NLP学术边缘人员,在硕士毕业后、博士入学前的几个月,本来就挺迷茫的,一波ChatGPT刷屏直接搞的更迷茫了。很认同之前孙学长
说的,ChatGPT带来的冲击太大了,本来现在应该在赶ACL的,哈哈。不过也很开心接受了 大模型时代 的思想,于是想着先做点什么,就很开心的加入了 必扬的团队,和好兄弟们一起做了点工作。主要的信息必扬已经说过了,我就不再喧宾夺主了,我来简单介绍一下基于统计/语言学特征的检测原理。其他信息参考Biyang 的回答。
以下内容来源于本人浅薄的理解,如有纰漏,还请提出宝贵意见!
首先声明,这些工作基本没什么原创idea,相关工作都给出了。就是在我们数据上试了一下,我们也没想着设计新检测器(求生欲拉满)。
基于统计特征检测器demo (huggingface demo和modelscope demo) 中,使用的是两个基于语言模型统计特征 的逻辑回归(Logistic regression) 模型。逻辑回归模型本身就不介绍了,下面分别介绍使用的两种统计特征:(1)GLTRTest-2[1]和 (2) 语言模型困惑度 ppl (这个没放在论文里 )。
一、GLTR Test-2
这组特征由 2019 年 ACL 的一篇 demo paper[1]提出,它利用的是本文生成模型解码阶段的特点,即总是选择预测的概率较高的词输出(选择最高概率 也是大多数 ML&DL 模型预测的基本方式)。
基于这个思想,思考以下观点:
- 这些 预训练语言模型 是基于海量的文本进行学习,它们其实在建模数据中 常见的/高频的 词汇组合、表达方式 等,是学习了 整个语料库的 公共特征;
- 人类撰写的文本,带有作者特定的 词汇组合、表达方式 等习惯(比如我喜欢在中文插空格,方便快速抓重点,或者杨院长几乎每个视频都要 又来绑架小猫啦 并且 谴责3号楼),这些文本与语言模型学习到的常见高频特征是一定程度上不符的,不经过特殊的指导(特殊prompt)也一般生成不出来。
综合以上两点,就可以猜想,人类撰写的文本有时候不符合语言模型建模的公共特征,那人类文本中的一些词汇,也大概率会被语言模型分配较低的概率。而模型生成的文本中的词汇,一般都会有较高的概率。我们可以用这个特点来分辨!
所以,GLTR Test-2 使用语言模型(我英文用的 GPT2-small[2],中文 Wenzhong-GPT2-110M[3])按照从左到右的文本生成顺序,依次在每个词的位置上 预测整个词表的生成概率分布(一个长度为词表大小的数组,每个元素是预测概率/分数,黑话祛魅hh),然后找到这个词的概率在整个分布中的排名。
ps:这个排名可以简单理解为, 给定之前的文本,语言模型要续写的时候,在它的小脑瓜中 这个词可能被选择的顺序。
最终,根据所有词的排名,构造了4个特征:
1. 文本中 语言模型预测排名 top-10 的词 的数量
2. 文本中 语言模型预测排名 10-100 的词 的数量
3. 文本中 语言模型预测排名 100-1000 的词 的数量
4. 文本中 语言模型预测排名 1000+ 的词 的数量然后拿人类文本和GPT文本的这四类特征训练一个逻辑回归模型,就完成了一个检测器。
下面我们看一个 GLTR 论文中的可视化(他们也提供了英文的在线demo):

图中绿色代表 top-10的词,黄色 10-100,红色 100-1000,紫色 1000+。可以看到人类写的什么颜色都有,模型生成的基本都是绿的(图中下半部分,模型生成的文本,有黄和红是因为计算特征的模型与生成的模型不是同一个,难免会有不一致),即预测排名较高的。
模型生成的文本 (Generated) 与 人类撰写的文本 (Human-Written) 区别还是挺明显的哈。
二、语言模型困惑度 PPL
这个模型很简单。语言模型困惑度 (Perplexity, PPL. 参见高赞解读通俗解释困惑度) 是用来评价生成文本的质量的评价指标。
但是,也有研究 (citation 等下翻一下) 发现,用预训练的语言模型计算文本PPL的话,人类的文本PPL很多时候反而挺高的,模型生成的文本比较低,可以参考我在论文中画的 人类-ChatGPT ppl分布图,蓝色是 ChatGPT,黄色是人类:
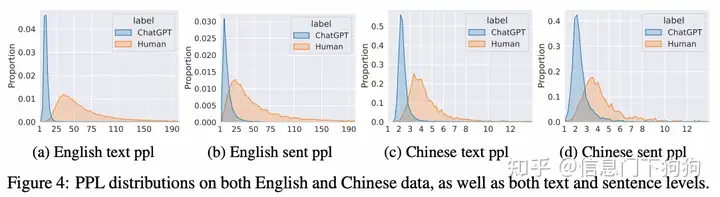
所以就用不同级别的ppl 构建了一组特征,比如 整条文本的PPL,所有句子PPL的最大/小值、均值、标准差 等等,也同样训练一个逻辑回归模型。
这组特征的想法也一部分来源于之前爆火的 GPTZero[4],我使用了一下这个web demo,但是不知道他们具体是怎么实现的。
我写的这个ppl特征模型,英文效果挺好的,测试集准确率有 90+,中文上暂时只有 60上下,所以没放进论文。可能是我搞的急,参没调好,回头再试试。
广告时间(自由跳过 )
目前我们论文 已经上线 arxiv,有需要的同学可以查阅。第一版赶的比较急,还很粗糙,欢迎提出宝贵意见!

数据集全面上线 HuggingFace 和 ModelScope,全量数据训练的模型也上线 HuggingFace,详情见项目github,ModelScope 正在准备中~
(小小夹带私货一下)后续会推出 基于AdaSeq一行命令训练ChatGPT检测器,欢迎大家试用!
最后,提高人工智能方法的实用性、易用性,降低其应用门槛,减少其不良影响,是我这种普通从业者力所能及的事情,也是我目前阶段自己所能设想的研究大背景。比如研究 低资源、半监督等,减少数据成本;研究 人在回路的有交互的模型构建方法,让更多人能轻松定制、持续改进自己的人工智能应用;等等。
希望能有更多志同道合的小伙伴们一起,推进 AI 的民主化,引用 AI2[5]的口号:让人工智能造福万千大众, AI for the Common Good!
参考
- ^abGLTR: Statistical Detection and Visualization of Generated Texthttps://aclanthology.org/P19-3019/
- ^GPT2-smallhttps://huggingface.co/gpt2
- ^Wenzhong-GPT2-110Mhttps://huggingface.co/IDEA-CCNL/Wenzhong-GPT2-110M
- ^GPTZerohttps://etedward-gptzero-main-zqgfwb.streamlit.app/
- ^Allen Institute for Artificial Intelligencehttps://allenai.org/