ChatGPT为什么这么强
1.从周五到周末ChatGPT已经疯传开来,其对话能力让人惊艳。从玩梗、写诗、写剧本,到给程序找bug,帮人设计网页,甚至帮你生成AIGC的提示词,一副无所不能的样子。可以去Twitter上看Ben Tossell梳理的一些例子,或者自己去试试!一位MBA老师让ChatGPT回答自己的管理学题目,结论是以后不能再布置可以带回家的作业了。很多人用了以后无法自拔,就如这位所见:
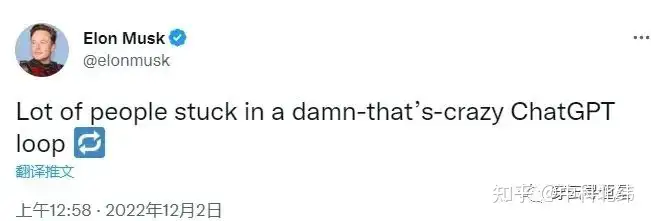
Musk问ChatGPT怎么设计Twitter(不得不说还挺有创意):
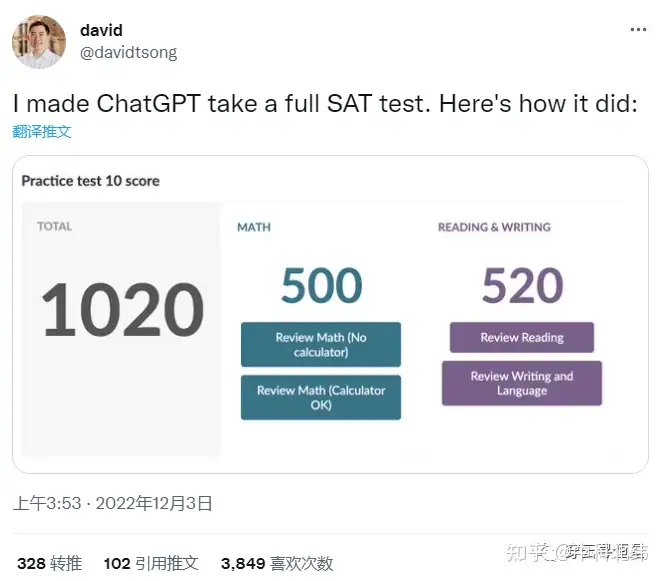
2.有人让ChatGPT参加了智商测试,得分83; SAT测试得分1020,对应人类考生52%分位。要知道ChatGPT并没有对数学方面做过优化,已经是相当不错的结果了。

3.ChatGPT的提升点

相比之前的GPT-3,ChatGPT的提升点在于能记住之前的对话,连续对话的感觉让人舒服。
ChatGPT可以承认错误,如果你认为他的回答不对,你可以让他改正,并给出更好的答案。
ChatGPT可以质疑不正确的前提,GPT-3刚发布后很多人测试的体验并不好,因为AI经常创造虚假的内容(只是话语通顺,但脱离实际),而现在再问哥伦布2015年来到美国的情景这样的问题,AI已经知道哥伦布不属于这个时代了。

ChatGPT还采用了注重道德水平的训练方式,按照预先设计的道德准则,对不怀好意的提问和请求说不;当然,尽管OpenAI非常小心,这种准则还是可能被聪明的提问方式绕开。
4.ChatGPT的训练方法
当下大模型的工作范式是预训练-微调。首先在数据量庞大的公开数据集上训练,然后将其迁移到目标场景中(比如跟人类对话),通过目标场景中的小数据集进行微调,使模型达到需要的性能。微调/prompt等工作从本质上对模型改变并不大,但是有可能大幅提升模型的实际表现。人类问问题方式对于GPT-3而言不是最自然的理解方式,要么改造任务,要么微调模型,总之是让模型和任务更加匹配,从而实现更好的效果。
ChatGPT是22年1月推出的InstructGPT的兄弟模型。InstructGPT增加了人类对模型输出结果的演示,并且对结果进行了排序,在此基础上完成训练,可以比GPT-3更好的完成人类指令。ChatGPT新加入的训练方式被称为从人类反馈中强化学习(Reinforcement Learning from Human Feedback,RLHF)。
ChatGPT是基于GPT-3.5模型,训练集基于文本和代码,在微软Azure AI服务器上完成训练。原先GPT-3的训练集只有文本,所以这次新增了代码理解和生成的能力。

5.为什么ChatGPT的提升这么明显
除了带有记忆能力、上下文连续对话能带给人显著的交互体验提升,ChatGPT的训练方式也值得关注。上述提到的RLHF方法首见于22年3月发表的论文(Training language models to follow instructions with human feedback),但根据业界的推测,RLHF并未用到InstructGPT的训练中。InstructGPT所用到的text-davinci-002遇到了一些问题,会呈现出模式坍塌(mode collapse)现象,不管问他什么问题,经常收敛到同样的答案,比如正面情绪相关的回答都是跟婚礼派对相关。
这次RLHF的方法得以在ChatGPT上应用,并取得了很好的效果。但RLHF实际上并不容易训练,强化学习很容易遇到模式坍塌,反馈过于稀疏这类问题,训练起来很困难。这可能也是为什么论文在3月发表,ChatGPT在12月才上线,中间需要大量的时间来调优。
此外,指令调整(instruction tuning)的贡献也很大。InstructGPT虽然在参数上比GPT-3少了100倍(13亿 vs 1750亿),它的输出效果比GPT-3以及用监督学习进行微调的模型都要好得多。
根据知乎用户避暑山庄梁朝伟的观点:Instruction Tuning和Prompt方法的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于,Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做language model任务,而Instruction Tuning则是激发语言模型的理解能力,通过给出更明显的指令,让模型去理解并做出正确的反馈。
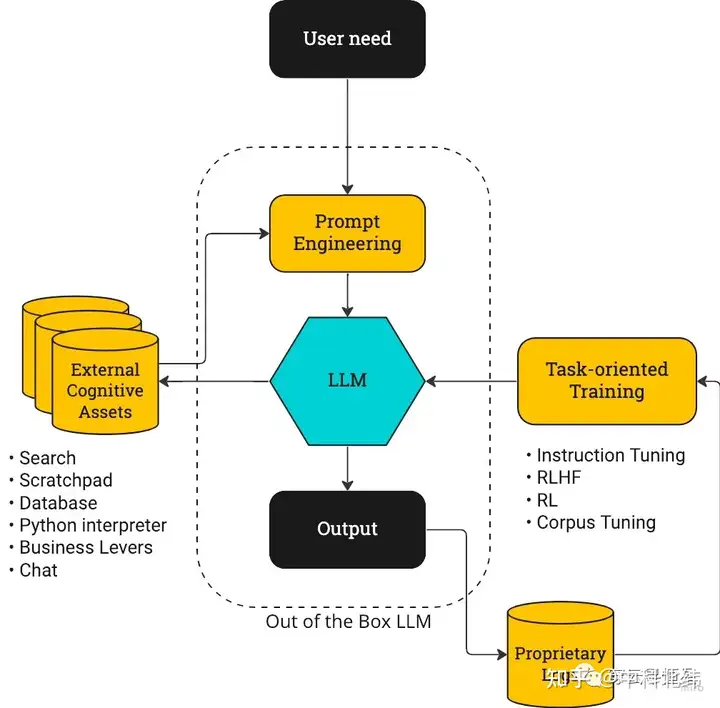
参考下图,以前大模型的提升重心更多放在了大模型(LLM)本身和Prompt Engineering上,而ChatGPT的迭代重点是右侧的闭环。
action-driven LLM训练流程图
最后,ChatGPT在过于保守不提供有效回答和提供虚假信息之间做出了较好的权衡。之前Meta用于科研的大模型Galactica上线仅3天就被迫下线,因为提供了过多虚假的信息。这跟Meta的宣传策略也有关,其本意是想帮助研究人员整理信息、辅助写作,但Meta将其模型宣传为可以总结学术论文,解决数学问题,生成维基文章,编写科学代码,为分子和蛋白质做注解等,过高期望带来了反效果,科研人员本来就是挑剔的。ChatGPT尽管不能完全避免虚假信息的问题,但可以看出在微调/Prompt方面做了足够细致的工作,一些自相矛盾的提问可以被甄别出来,让用户对其回答更有信心。
6.商业策略也是重要一环
这次ChatGPT是免费不限量向公众开放,用户可以尽情在平台上尝试各种奇异疯狂的想法,而此前GPT-3是根据使用量(token)来收费的。在使用过程中,用户可以提供反馈,这些反馈是对OpenAI最有价值的信息。OpenAI并不急于创收也不缺钱,坊间传言最新一轮估值已经达到数百亿美金,还有金主爸爸微软。
对于AI发展来说,工程的重要性实际上大于科学,创建一个迭代反馈的闭环至关重要。OpenAI很注重商业应用,GPT-3已经拥有大量客户。这些客户跟OpenAI的反馈互动也是推动进步的关键一环。相比之下,谷歌的闭门造车就显得不合时宜,或许是缺乏商业化的文化,或许是受限于投入产出比,谷歌对于大模型的应用一直很克制,即便起点很高,但如果一直像Waymo做自动驾驶一样小规模迭代,早晚会被更为开放,获得更多数据的企业超越。

7.后续提升点
RLHF是一种较新的方法,随着OpenAI不断摸索,结合ChatGPT搜集到的用户反馈,模型还有进一步提升的空间。尤其是在道德/alignment层面,需要屏蔽掉这几天大家试验出来的绕过系统限制产生负面信息的方法。
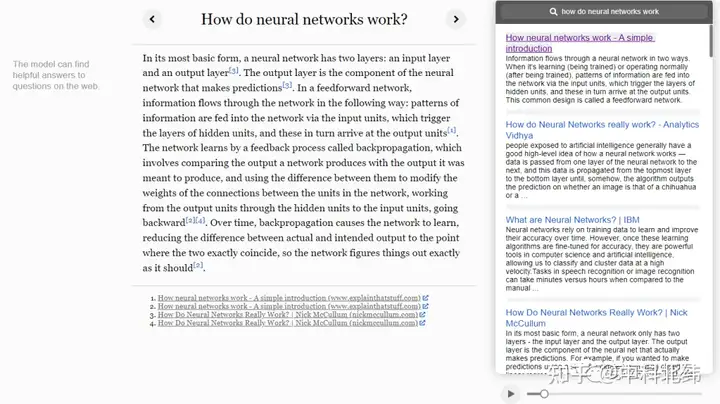
当然也别忘了,OpenAI还有WebGPT这样的工具,可以理解为高阶版网页爬虫,从互联网上摘取信息来回答问题,并提供相应出处。比如下面的问题How do neural networks work,WebGPT利用了GPT-3本身具备的语义理解能力和互联网公开信息,自己结合出了一份答案,不失为一种升级的搜索能力。
在MIT Technology Review对OpenAI科学家的采访中,他们提到了后续有可能将ChatGPT和WebGPT的能力结合起来。有网友挖掘出了ChatGPT内设的提示词,其中包含browsing:disabled,把浏览网页能力关闭了,也就是说后续有可能加入这个能力。可以设想,ChatGPT+WebGPT可以产生更为有意思的结果,信息可以实时更新,对于事实真假的判断将更为准确。
与WebGPT的这种结合,对应到上面 action-driven LLM训练流程图 的左半部分,即连接外部的信息源和工具库。事实上网页搜索只是一种可能,还结合利用各种工具(比如各种办公软件、SaaS软件),实现更丰富的功能。
在产品层面,是不是有更好的界面和实现方式也值得讨论。同屏对话框形式容易让人产生过高的预期,因为要保障对话的流畅性。在这一点上,Github Copilot产品就做得很好,Copilot主打的是programming pair,以伙伴的身份提出建议。从用户角度,这个建议好就接受,不好就不接受;即便提出了很多不被接受的建议,但在随机时间间隔产生的有效建议带来的爽感就会让用户上瘾。如果ChatGPT后续成为写作助手、编剧助手、工作助手等等,类似Copilot的产品形态会容易让人接受。
写在最后
很多人惊叹于ChatGPT的能力,但其实真正惊艳的还在后面。OpenAI最厉害的不是他关于大模型的理解,而是其工程化、迭代反馈的能力,以及alignment(AI跟人类目标的统一)方面的工作。很欣赏OpenAI CEO Sam Altman的一句话:Trust the exponential. Flat looking backwards, vertical looking forwards. 我们就处在即将起飞的这个点上。
-
上一篇
大火的ChatGPT,比国内的大模型强在哪里
本文将从以下几个方面展开:
-
下一篇
近日,由人工智能实验室OpenAI发布的对话式大型语言模型ChatGPT在各大中外媒体平台掀起了一阵狂潮。短短4天时间,其用户量到达百万级,注册用户之多导致服务器一度爆满。继 AI 绘画之后,由OpenAI 上线的 ChatGPT 成了新的流量收割机,也引发了网友的一系列花式整活。ChatGPT的功能是如此强大,以致连马斯克都认为我们离强大到危险的 AI 不远了。
ChatGPT究竟是什么?
ChatGPT是由美国开放人工智能研究中心(OpenAI)发布的一个聊天机器人程序,其实早在去年11月30日就已经发布了,有一项调查显示,截至2023年1月,美国约有89%的大学生在用ChatGPT完成作业。
本质上来说,ChatGPT是一个由技术驱动的自然语言处理工具,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码等任务。
那么,为什么ChatGPT能引起如此大的市场反应呢?
之所以能让马斯克发出强大到危险的AI的感叹,是因为ChatGPT作为一个人工智能模型,真的在产出类似人类的常识、认知、需求和价值。比如,根据很多用户的反馈,你可以提问ChatGPT对很多社会问题的看法,而其可以从广大群众的角度,通过客观理论的推理来进行解释,从而提供具有社会价值的答案。
而从技术角度来说,它是因为引入了新的算法技术RLHF,即基于人类反馈的强化学习。可以说,ChatGPT的火爆是技术工程和服务产品的胜利。过去我们更为常用的是LLM,也就是大型语言模型,但是它的建模过程中并没有显式的引入人的偏好和主观意见,因而就缺少了人们从ChatGPT上面可以找到的人的味道,而RLHF的本质逻辑就是用生成文本的人工反馈作为性能衡量的标准,或者说是用这种反馈来优化模型,也就是说,直接使用强化学习的方式来直接优化带有人类反馈的语言模型。
正是这种快速反馈,让用户有了对ChatGPT拟人化的可能,一系列类似人的语言反馈行为再叠加轻松便捷的聊天场景,人们由原本对人工智能技术的准确性、即时性、客观性的苛刻要求,已经逐步转变为人性化、趣味化、互动化的反馈需求,甚至ChatGPT有一些不太恰当的回复也会成为人与其聊天中的乐趣所在,换个说法,ChatGPT可以提供人们在聊天中所需要的情绪价值,而不仅仅是信息反馈。
更低的门槛让人工智能向通用技术转变
ChatGPT所提供的新的聊天模式,让AI技术的门槛变低了,这种变低有两个层面的含义。
一个层面是AI技术进入人们现实生活的门槛变低了。ChatGPT通过一个更为随意和通俗的聊天场景直接和用户建立了联系,并且其多元化的功能可以通过一个统一的聊天接口对接不同的用户,这就让用户层面的通用化变为了可能。
另一个层面是AI本身语料获取的门槛变低了。通过这种更为随意化的聊天场景,用户在多轮聊天过程中就会不断的提供对于ChatGPT反馈结果的进一步人工反馈,从而提供更多的语料帮助模型的进一步强化。
而门槛变低的结果,就是人工智能技术成功出圈,开始可以独立的引领一个AI为核心的大型商业化结构的形成,也就是AIGC,AIGC即AI Generated Content,是指利用人工智能技术来生成内容。在内容为王的当代互联网时代,人工智能技术生成内容自带的客观性、即时性、准确性和话题性都将成为其商用吸引力的重要来源。笔者认为从短期而言,可以大规模商用的领域,包括但不限于归纳性和整理性的文字类工作,规范性的代码类工作,图像生成和智能客服等工作。
人力资源和数据获取,是大规模商用的局限性所在
ChatGPT并没有从本质上改变AI的产品结构,其同样也是由模型和训练数据两部分来构成。模型就是类似神经网络模型,只是这一次的transformer模型有了更强的并行化操作能力和扩展性,同时匹配更大规模的数据集,就可以不断地训练出更强大的模型。
而ChatGPT未来发展可能的局限性也正是由这两方面而生。其一是模型。ChatGPT模型的背后对于标注员的工作量和综合素质要求很高,加入人工反馈的模型强化是其具有人味的关键,而这也将成为其不断扩大的局限所在。
其二就是数据和算力。由于ChatGPT的技术路线与其他AI甚至和人脑都不太一样,所以其仍然会受到算力资源和算法的限制,其也无法更加深入地具备真正意义上的逻辑思维,而大量数据的获取还会伴随一系列的隐私安全等问题。
那么可能的突破点在哪里? 笔者有如下两个想法,一个是让AI为AI打工。随着人为反馈的加入,AI模型本身就可以提供一定程度的人为反馈,因而其也可以作为整个AI模型人为反馈的来源。
另一个是让用户自主成为语料的不断供应者,即,通过更随意的聊天场景、更无感的信息反馈来得到更巨量的语料获取,从而满足数据规模的需求。
强大到危险的ChatGPT,会替代人类思考吗?