虚拟数字人制作简单吗?
关于虚拟数字人的制作,小编在行行查 | 行业研究数据库帮你找到了些数据希望对你有所帮助。
虚拟数字人的制作流程涵盖了诸多技术,制作方式与制作技术仍在不断进化中。虚拟人制作流程中最为核心、最具挑战的是建模、驱动、渲染三大流程。
•建模环节:以真人为模型或设计人物为虚拟数字人建立基本的3D模型。3D 建模为构建虚拟人形象的基础,重点在于实现细节的精细还原;
•驱动环节:通过真人动作捕捉(真人驱动型)、训练驱动模型(算法驱动型)等形式确定虚拟数字人的基本动作;
•渲染环节:根据在设计环节中确定的虚拟人最终呈现效果和应用场景等外界要素,将模型与其运动进行渲染以呈现最佳效果。渲染技术用于提升虚拟人的逼真程度,实时互动亦需要实现实时渲染。
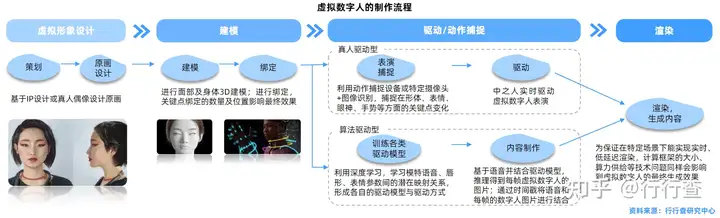
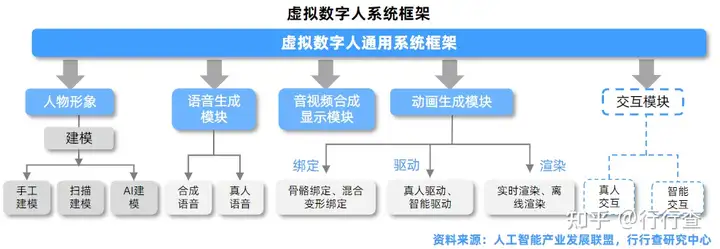
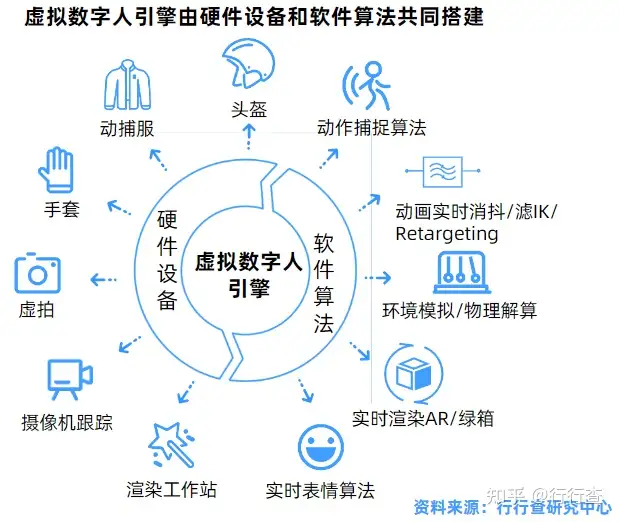
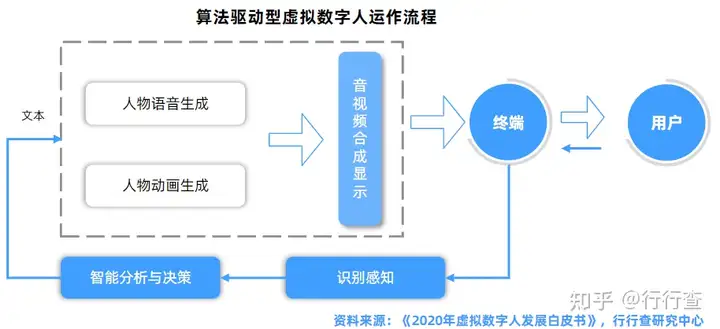
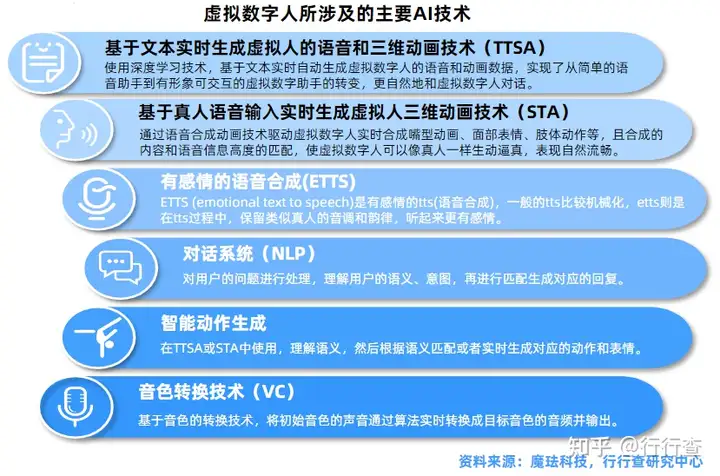
虚拟数字人的三大基本特征(具备人的外观、人的行为、人的思想),基于大量技术栈的支撑,涉及硬件设备和软件算法众多领域:图形识别、视觉技术、3D建模、CG渲染、动作捕捉、人工智能、计算机语音技术、自然语言处理等。而一个虚拟数字人,一般情况下会由人物形象、语音生成、动画生成、音视频合成显示、交互等五个模块构成。
•人物形象:根据人物图形资源的维度,可分为2D和3D两大类,从外形上又可分为卡通、拟人、写实、超写实等风格;
•语音生成模块:基于文本生成对应的人物语音;
•动画生成模块:基于文本生成对应的人物动画;
•音视频合成显示模块:将语音和动画合成视频,再显示给用户;
•交互模块:使虚拟数字人具备交互功能,即通过语音语义识别等智能技术识别用户的意图,并根据用户当前意图决定数字人后续的语音和动作,驱动人物开启下一轮交互。
建模:精度可达毫秒级
目前虚拟数字人的扫描建模技术可分为静态重建和动态光场重建两大类,其中静态扫描处于主流地位应用广泛,而高保真动态光场三维重建技术初露锋芒,是未来建模技术发展的重要方向。
静态建模技术
•结构光扫描重建:早期的静态建模技术以结构光扫描重建为主,但其扫描时间长,对人体运动目标的友好度和适应性不佳,因而更多应用于工业生产、检测领域。
•拍照式相机阵列扫描重建:近年来得到飞速发展,目前可实现毫秒级高速拍照扫描(高性能的相机阵列精度可达到亚毫米级),满足数字人扫描重建需求,成为当前人物建模主流方式。
动态光场重建技术
相比静态建模技术,动态光场重建不仅可以重建人物的几何模型,还可一次性获取动态的人物模型数据,并高品质重现不同视角下观看人体的光影效果,成为虚拟数字人建模重点发展方向。动态光场重建是目前世界上最新的深度扫描技术,此技术可忽略材质,直接采集三维世界的光线,然后实时渲染出真实的动态表演者模型,它主要包含人体动态三维重建和光场成像两部分。

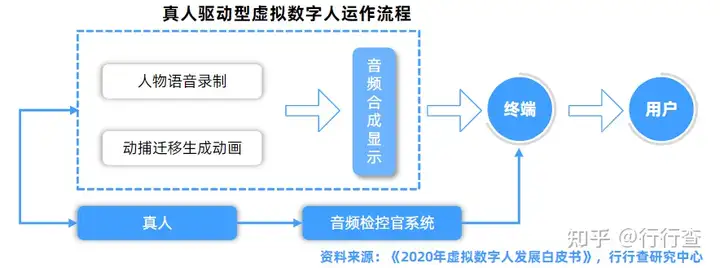
驱动:完整采集数据
驱动技术可分为真人驱动和算法驱动(又称智能驱动),其中真人驱动是指通过动作捕捉技术采集真人演员的动作和面部表情数据,之后将这些数据迁移合成到虚拟数字人身上,而近年来基于计算机视觉的捕捉技术发展迅猛。动作捕捉技术按照实现方式的不同,可分为光学式、惯性式、电磁式以及基于计算机视觉的动作捕捉等。现阶段,光学式和惯性式动作捕捉占据主导地位,基于计算机视觉的动作捕捉成为聚焦热点。
•光学动作捕捉通过对目标上特定光点的监视和跟踪来完成运动捕捉的任务。最常用的是基于Marker(马克点)的光学动作捕捉,即在演员身上粘贴能够反射红外光的马克点,通过摄像头对反光马克点的追踪,来对演员的动作进行捕捉。这种方式对动作的捕捉精度高,但对环境要求也高,并且造价高昂。
•惯性动作捕捉主要是基于惯性测量单元(InertialMeasurementUnit,IMU)来完成对人体动作的捕捉,即把集成了加速度计、陀螺仪和磁力计的IMU绑在人体的特定骨骼节点上,通过算法对测量数值进行计算,从而完成动作捕捉。这种惯性动作捕捉方案价格相对低廉,但精度较低,会随着连续使用时间的增加产生累积误差,发生位置漂移。
•基于计算机视觉的动作捕捉主要是通过采集及计算深度信息来完成对动作的捕捉,是近些年才兴起的技术。这种视觉动捕方式因其简单、易用、低价,已成为目前使用的频率较高的动作捕捉方案。

驱动:智能合成形象
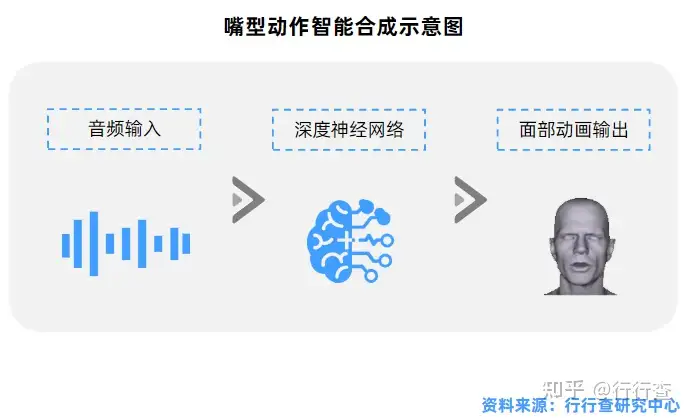
算法驱动通过智能系统自动读取并解析识别外界输入信息,根据解析结果决策虚拟数字人后续的输出文本,然后驱动人物模型生成相应的语音与动作来使虚拟数字人跟用户互动。它是基于深度学习模型在视觉、语音和自然语言等方向的广泛应用,可以自驱动学习模特说话时的唇动、表情、语音以及姿态和动作等。当前虚拟数字人已实现嘴型动作的智能合成,其他身体部位的动作目前还只支持录播。
•嘴型动作智能合成:底层逻辑是建立输入文本到输出音频与输出视觉信息的关联映射,主要是对已采集到的文本的语音和嘴型视频/动画数据进行模型训练,得到一个输入任意文本都可以驱动嘴型的模型,再通过模型智能合成。
•眨眼、微点头、挑眉等拟人动作合成:目前都是通过采用一种随机策略或某个脚本策略将预录好的视频/3D动作进行循环播放来实现。例如3D肢体动作目前就是通过在某个位置触发这个预录好的肢体动作数据得到。触发策略是通过人手动配置得到的,未来希望通过智能分析文本,学习人类的表达,实现自动配置。
渲染:突破恐怖谷效应
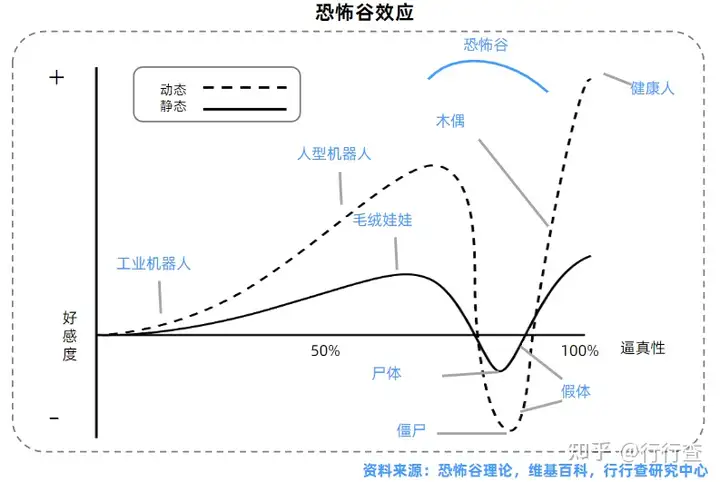
渲染技术是在电脑绘图中是指用软件从模型生成图像的过程。它将三维场景中的模型(包括几何、视点、纹理以及照明信息),按照设定好的环境、灯光、材质及渲染参数投影成数字图像。在虚拟数字人的制作流水线中,渲染是最后一项重要步骤,决定了最终作品的质量与风格。基于物理的渲染技术(PBR)的进步以及重光照等新型渲染技术的出现使数字人皮肤纹理变得真实,突破了恐怖谷效应。虚拟数字人恐怖谷效应主要由其外表、表情、动作上与真人的差异带来,而PBR基于真实物理世界的成像规律,通过更真实的反映模型表面反射光线和折射光线的强弱,使得渲染效果突破了塑料感,从而提升虚拟数字人的美感、增强画面视觉效果。
渲染:算法持续优化
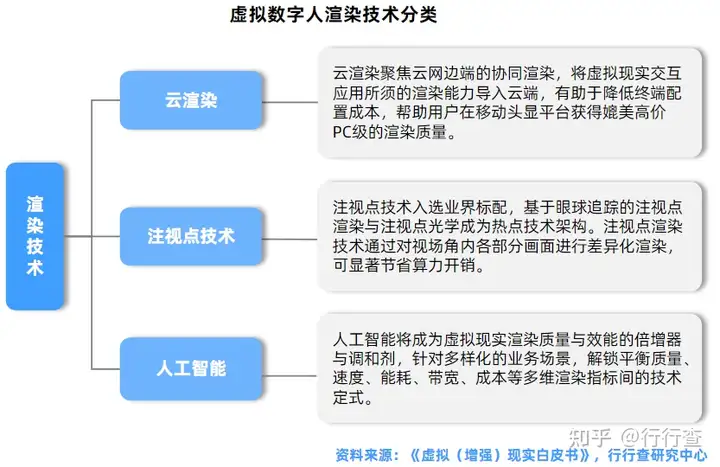
渲染技术又可分为离线渲染和实时渲染。为实现虚拟数字人的实时操控与实时交互,各大渲染引擎一直在发力突破算法,提升实时渲染效率,希望在实时渲染的画面质量、渲染速度、计算资源三者中取得最优解。渲染技术的升级是综合实力的体现,每一次技术提升对数字人皮肤纹理、3D效果、质感和细节等方面提升巨大。
•离线渲染:是在计算出画面时并不显示画面,计算机根据预先定义好的光线、轨迹渲染图片,渲染完成后再将图片连续播放,实现动画效果。优点是渲染质量相对好,美学和视觉效果好,缺点是无法实时控制,主要应用于影视等方面,代表性软件包括Maya、3DMax等。
•实时渲染:是指计算机边计算画面边将其输出显示,优点是可以实时操控,缺点是要受系统的负荷能力的限制,必要时要牺牲画面效果,主要应用于游戏等方面,代表引擎包括UnrealEngine(虚幻)、UnityEngine等。


AI:提升智能化水平
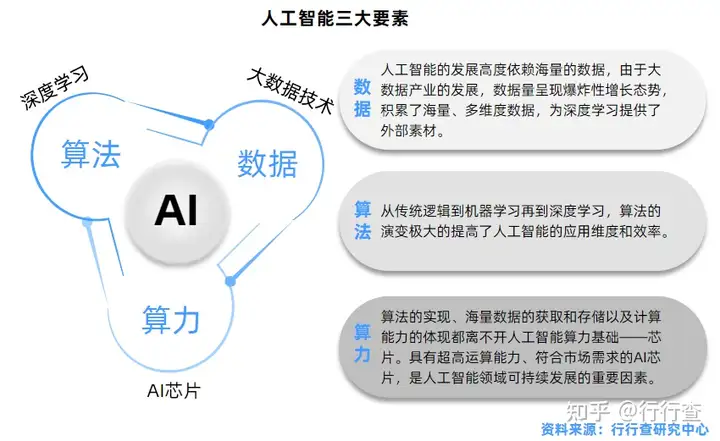
人工智能(AI)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学,用来生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括语言识别、图像识别、自然语言处理和专家系统等。人工智能具有算力、算法、数据三大要素。
虚拟数字人的最终智能效果受人工智能技术(AI),如语音合成(语音表述在韵律、情感、流畅度等方面是否符合真人发声习惯)、NLP技术(与使用者的语言交互是否顺畅、是否能够理解使用者需求)、语音识别(能否准确识别使用者需求)等技术的共同影响。
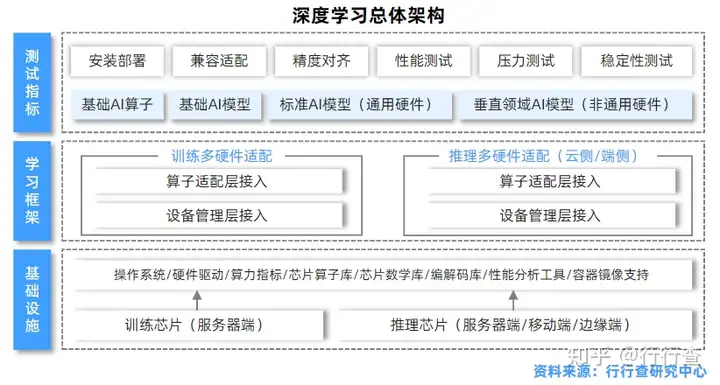
深度学习:赋予虚拟数字人类似人的视觉、听觉、触觉等对外界刺激做出反应的能力
通过深度学习技术可对数据信息进行总结、抽象,并发现其中的规律。在数据输入后,通过多层非线性的特征学习和分层特征提取,最终对输入的图像、声音等数据进行预测。深度学习框架多硬件平台适配总体架构技术方案包括设备管理层接入接口、算子适配层接入接口,训练框架与推理框架的多硬件适配指标体系包括安装部署、兼容适配、算子支持、模型支持、训练性能、稳定性和易扩展性等。
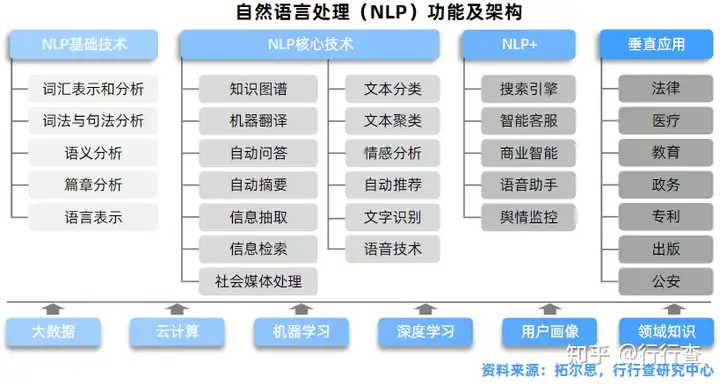
自然语言处理:赋予虚拟数字人理解用户需求并解答的能力
自然语言处理(NLP)是指利用人类交流所使用的自然语言与机器进行交互通讯的技术。通过为对的处理,使得虚拟数字人对自然语言可读并理解。自然语言处理技术是人工智能最早的应用技术,该技术细分领域包括文本分类和聚类、信息检索和过滤、机器翻译等。
数据来源:行行查,行业研究数据库

可点击下方链接查看相关行业研究报告


欢迎评论、点赞、收藏和转发! 有任何喜欢的行业和话题也可以私信我们。
-
上一篇
原创虚拟数字人直播软件,是怎么做到无人直播带货的?
原标题:虚拟数字人直播软件,是怎么做到无人直播带货的?
-
下一篇
直播与短视频的优势对比
与其费尽心思策划视频脚本、撰写文案、拍摄、剪辑等多道繁琐工作相比,无人直播只需将手机放置在指定位置,直接展示门店环境、产品介绍和制作过程,再辅以话术促单,简单高效。
无需制作视频、积累粉丝,只需要开启直播,抖音将根据POI地址定位推送附近目标人群进入直播间。这样能够获得精准的流量、稳定的客源和高效的转化率。
此外,无人直播相较于短视频,能够带来实时互动和更强的真实感和时效性。观众所见即所得,更有助于促进消费和即时成交。
无人自动直播系统的优势包括:
1.高度灵活性:AI直播带货能够一直在线,提供持续的直播内容,可以满足观众随时观看的需求,以时间上的宽度优势获取较多的流量。
2.低成本:相比真人主播,AI直播带货的成本更低。AI主播只需要按照软件平摊到月份的成本,而真人主播需要支付底薪和提成等费用,尤其是中、头部主播的巨额坑位费,常常令品牌闻之肝颤。
3. 无时间限制:AI主播没有真人主播的工作时间限制。真人主播的直播时间通常为3-4小时,过了6小时就接近了工作极限,而AI主播可以不知疲倦地24小时不间断直播。
4. 可控性强:AI主播可以完全由创作者控制,包括外貌、语言、动作、情绪等方面,可以根据产品或品牌需求进行定制,以达到更好的宣传效果。
5. 降低风险:对于品牌方和直播间来说,使用AI主播可以降低风险。真人主播可能面临负面消息或禁播的风险,近年来多位明星塌房就给品牌造成了声誉和经济上的损失,而AI主播则几乎不会受到这些问题的影响。
无人直播系统内容
AI数字人自动直播,AI虚拟直播系统!
