jenkins学习之pipeline
一、背景
1.想法
jenkins1.x主要是实现的持续集成过程,集成各个插件,但是终究需要人为手工的操作,如果job太复杂,人为容易出错。于是jenkins2.x开始流行pipeline的写法,以代码的方式来进行job的构建。正如社会潮流总是从人工到自动化的过程,在之前那篇文章中提及,要做一个devops的小工具,从java代码实现上来说,对于我还是比较复杂,代码实现部分还在钻研中。本篇文章只是讲讲jenkins中pipeline怎么写!
二、pipeline基本语法介绍
学习一种编程语言(groovy)最开始的步骤总是学习它的语法,知晓它的规则。但是对于pipeline来说,暂时还不需要深入去学习groovy,下面简单的为大家介绍下pipeline的一些主要的基本知识:
agent:该部分指定整个Pipeline或特定阶段将在Jenkins环境中执行的位置,具体取决于该agent 部分的放置位置。该部分必须在pipeline块内的顶层定义 ,也可以使用在stage级。
stage:表示这个Pipeline的某一个执行阶段(使用stage使得逻辑变得更加简单明了)
steps: 包含一个或者多个在stage块中执行的step序列(在这里执行操作:运行maven或者部署等等)
environment:指定键值对,可用于step中,主要是为常量或者变量赋值,根据所在的位置来决定其作用范围(类似于java中全局和局部的概念)
options:允许执行pipeline内置的专用选项,也可以使用由插件提供的
parameters:提供触发pipeline时的参数列表
trigger:定义了触发pipeline的方式(jenkins1.x中的pollscm定时构建)
tools:自动安装工具,注意这里使用的一定是在jenkins全局配置中已经定义好了的
when:可以用来执行一些代码逻辑
post:可以根据pipeline的状态来执行一些操作
以上是属于个人理解,具体以官方文档为准。下面再来详细说说里面比较重要的agent,其他的部分请大家自行google或者百度,相对来说比较简单。我的理解是:agent是一个机器总代理,它其中的参数都是为了指定一些可以使用的机器
agent的一些参数如下:
any : 在任何可用的机器上执行pipeline
none : 当在pipeline顶层使用none时,每个stage需要指定相应的agent,比方说:
pipeline{agentnone//没有指定agentstages{stage(checkout code){steps{shecho "checkout code"}}}}以上代码会报下面这串错误,原因就是没有指定agent应用的节点:

label:在指定的机器上运行pipeline或者stage,比方说
agent{ label slave1} //指定slave1的节点机器运行该stage或者pipeline这个设置的作用:在大规模集群中,CI机器往往是相同的配置,而此时你的项目又需要一些额外的配置,这个时候这个设置可以很好的完成这个功能
docker:定义这个参数后,指定pipeline或stage时会动态的接收一个指定节点的docker的镜像,并且还可以接受一个args的参数用于执行docker run 的参数。比方说你的项目要在A环境中做测试,在B环境中做预发验证,在C环境做灰度发布(这里只是简单的打个比方,实际中不是这样的,只是为了说明此时需要在不同的环境中做不同的事情),这个时候涉及到多个环境,常规做法可以是直接指定几个不同的slave的从节点,但是如果我此时想做测试并且只有一台机器,那我可以在这台机器上做几个docker镜像,分别用于不同的构建过程.比方说:
agent{
docker{
image mydocker //指定docker的镜像名称
label slave1 //指定在哪个机器上执行docker镜像
args -v /tmp:/tmp //运行时传入docker run的参数
}
}以上命令是在slave1的从节点机器上用mydocker的镜像生成一个容器,并传入-v /tmp:/tmp的参数
以上是我想分享给大家的基本知识,可能其中理解不对,也请大牛出来指正.
这个网站也推荐给大家:Jenkins持续集成 - 管道详解,如若作者认为我放在这里不合适,请联系我删除.同时也推荐大家浏览一下官方文档:
三、pipeline实际应用(小实例)
实例1.用pipeline实现:从代码库中拉取最新的代码,然后做pmd检测,如果此次构建成功的话输出hello!success!;如果失败的话输出failed!Please check pipeline code!并发送邮件到指定的地址上。按照以下流程做测试:
a.本地构建一个maven项目并上传到github上(最近github贼慢,之后考虑在自己服务器上搭建gerrit作为代码存放地址来演示)
***注意项目上传时一些不需要的文件及时使用.gitignore给忽略掉,要在git add 之前写好.gitignore文件,避免文件被track后忽略不了***
以上表示文件上传成功.
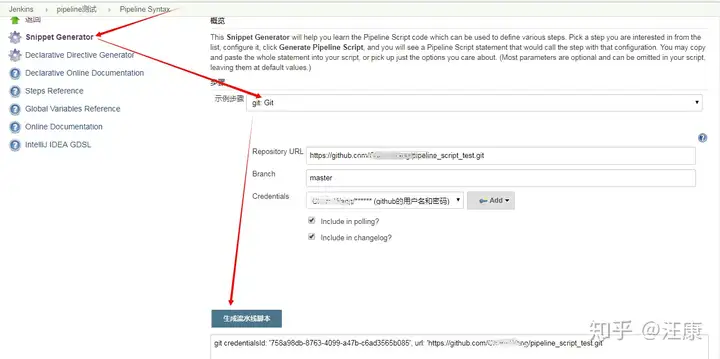
b.写好pipeline并运行,最后核查结果
***部分脚本可以使用jenkins中的Pipeline Syntax来生成,比如拉取代码的***
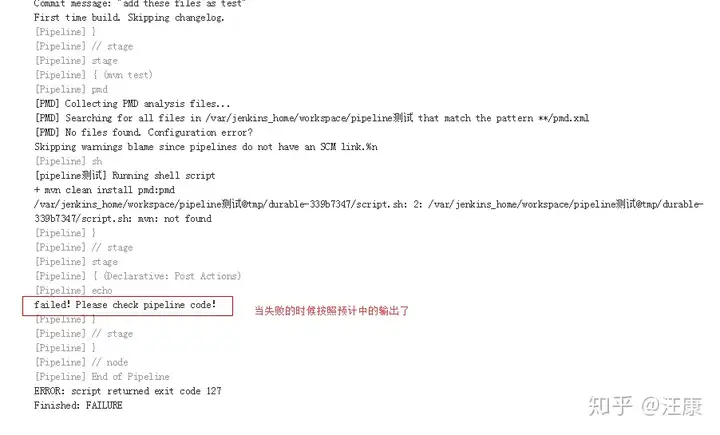
下面开始演示失败时候的场景,此时没配置mvn的环境,但是执行mvn命令,按照预计中的报错了:
下面开始演示正确的构建结果并附pipeline的代码:
pipeline{
agent any
tools{
maven maven3 //maven3必须是已经在jenkins上配置的工具
}
stages{
stage(checkout code){
steps{
git credentialsId: 2c7a38c6-f536-4e93-bf3c-2ff4563fae8e, url: https://github.com/XXX/pipeline_script_test.git
}
}
stage(mvn test){
steps{
sh "mvn -B -f ${env.workspace}/pom.xml pmd:pmd"
}
}
}
post{
always{ //always表示不管怎么样都做下面的操作
pmd canComputeNew: false, defaultEncoding: , healthy: , pattern: , unHealthy:
}
failure{
step([
$class: Mailer,
notifyEveryUnstableBuild: true,
recipients: "738402018@qq.com",
sendToIndividuals: true
])
echo "failed!Please check pipeline code!"
}
success{
echo "hello!success!"}
}
}构建结果如下:

实例2:
以上就是一些关于jenkins的pipeline的简单介绍,关于实例,之后会陆续更新上来。
如果对文章有疑问或者哪里不懂的请联系我,在力所能及的范围内帮助解答;如果文章有错误,也欢迎指出。
微信号:kakaicoco
devops系列002——jenkins-pipeline介绍
至于安装jenkins这里就不多说了,如果熟悉docker的话一条命令就解决了。
今天想恶补jenkins的小伙伴注意啦!
文末有福利,免费自取哦~
最近看到别人的 jenkins,有我没见过、看不懂但是又好酷好靓的样纸。
大概长以下这样:
还有长以下这样的:
经过一顿搜索 ……原来它就是 我不认识它,它也不认识我的jenkins pipeline
本着好奇心和对知识的求知欲,在网上各种资料一顿乱啃,大概明白了是咋么一回事。
接下来,就从小白开始,一步步完成它。主要分为以下几步:
在 jenkins 上安装 pipeline 插件
创建一个 pipeline 类型的任务
配置 pipeline 脚本。
pipeline 插件安装
在 magage jenkins -> 插件管理 -> avaliable 中,搜索 pipeline,选择并安装。
在 magage jenkins -> 插件管理 -> avaliable 中,pipeline stage view,选择并安装。
安装完成,可以在 New Item 里,看到 pipeline 选项。
创建 pipeline
环境准备就绪 ,嘿哈,可以开始创建流水线了。
在 jenkins 界面,点击 New Item 新建一个任务,选择流水线,就进入下面这个图了。
然后就懵逼了……pipeline 要写脚本 ?
原来,pipeline 是基本 groovy 脚本的。
那,完蛋了。我只会 python,不会 groovy。难不成我要先学一学 groovy,才能写的出来?
翻了翻 groovy,这玩意跟 Java 有关。我太难了,pipeline 太难了!
幸好,在官网当中,提供了其它的方式。
一文带你解读—骚气的jenkinspipeline玩法