MLPerf基准测试权威发榜两品牌宣称AI服务器性能世界第一网友:到底哪家强?
MLPerf是当前全球最具影响力的AI计算基准评测组织,MLPerf成立于2018年5月,得到了众多行业巨头和学术机构的支持和参与,其中包括亚马逊,百度,Facebook,谷歌,哈佛大学,英特尔,NVIDIA,微软,阿里巴巴,和斯坦福大学,由图灵奖得主大卫·帕特森(David Patterson)发起。每年组织全球AI训练和AI推理性能测试并发榜。
此次MLPerf的AI推理基准测试有全球23家公司和单位参与,在数据中心及边缘等场景进行AI计算产品的性能比试。该基准测试包括可代表生产级别的测试用例,测试结果在行业内具有较高权威性。

美国东部时间10月21日,全球备受瞩目的权威AI基准测试MLPerf公布今年的推理测试榜单。
两品牌AI服务器均为世界第一
10月22日,浪潮AI服务器NF5488A5宣称一举创造18项性能纪录,在数据中心AI推理性能上遥遥领先其他厂商产品。
同日,宁畅AI服务器X640宣称: 首登MLPerf,斩获30项AI性能世界第一,同配置测试获16项世界第一。

宁畅工程师介绍,参加MLPerf Inference(推理)基准测试的X640 G30 AI服务器,最高可支持10张NVIDIA A100 PCIe卡或21张NVIDIA T4 PCIe卡,堪称性能猛兽。
在此次基准测试中,浪潮AI服务器NF5488A5在开放优化(Open)和固定任务(Closed)的ResNet50基准性能测试中,均表现优异,相比2019年MLPerf推理榜单的服务器最好性能提升高达3倍。
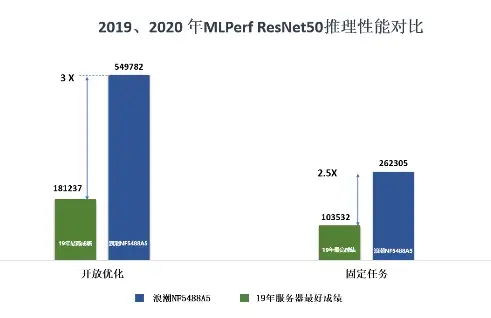
NF5488A5是浪潮自研的新一代AI服务器,是此次MLPerf全球竞赛中唯一可以在4U空间内支持8块安培架构A100芯片实现NVLink高速互联的AI服务器。
浪潮NF5488A5在系统拓扑上采用了超低延迟设计,支持PCIe 4.0全链路极致优化,高频通信单元采用一级拓扑最近连接,最大限度提升处理器到AI芯片间的通信性能。
同时,通过配置NUMA节点,确保每颗处理器与其直连的GPU之间通信性能最优,最大限度降低通信延迟。此外,NF5488A5通过深度优化系统结构设计,确保设备可在高温环境下稳定运行。
而对比行业同配置AI服务器,宁畅X640 G30搭配四张A100 GPU卡的情况下,在Resnet50、SSD、RNN-T、BERT、DLRM等10项测试中分数值取得世界第一;搭配16张T4 GPU卡配置的情况下,X640 G30打破六项世界纪录,性能一骑绝尘。
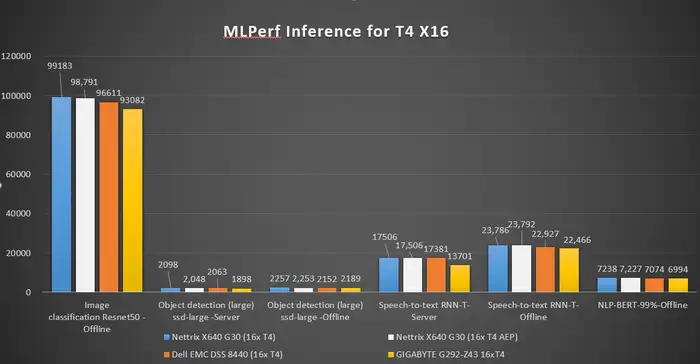
宁畅X640强调,相同配置下取得第一的MLPerf分数,意味着X640 G30 在图像分类、目标检测、医学影像、翻译、推荐、自然语言处理等AI应用场景中有更好性能表现,可为用户带来多高价值。
浪潮AI服务器NF5488A5和宁畅AI服务器X640均宣称打破多项世界纪录,挖掘机技术到底哪家强?
浪潮NF5488A5获数据中心AI性能绝对优势
NF5488A5是浪潮于今年5月推出,是一款新的AI服务器,由8个NVIDIA A100 GPU驱动,与第3代NVLink完全互连,外加2个支持PCIe4.0的最新AMD CPU。它为用户提供终极的AI性能和超高速带宽,同时为各种AI场景提供强大的计算支持,例如智能客户服务,财务分析,智能城市和智能语言处理。
此次浪潮NF5488A5一举创造18项MLPerf推理性能记录,成为创纪录最多的AI服务器。今年的测试中,数据中心AI性能最受关注,全部参与机构提交了507项性能测试数据。
浪潮NF5488A5创下了数据中心22个赛项中的13项性能记录以绝对优势领先,NVIDIA DGX取得了5项数据中心性能记录。而在此前的MLPerf训练榜单中,NF5488A5在最核心的Resnet50训练任务中也创下了性能记录,单机性能高居榜首。
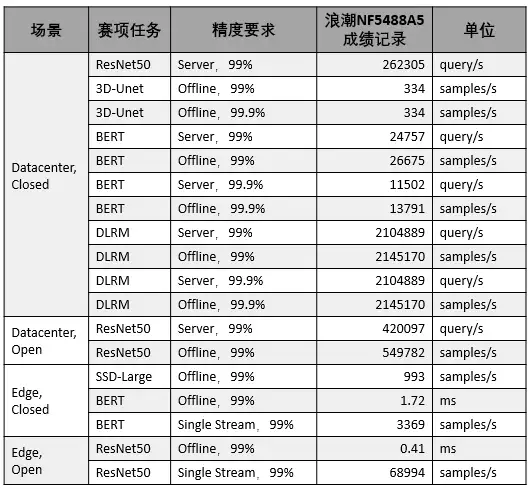
Resnet50是评估AI计算系统和AI芯片性能的全球最广泛接受的标准。在此基准的Resnet50培训任务中,浪潮使用了NF5488A5服务器,该服务器配备了8个NVIDIA A100 GPU和2个AMD EPYC 7742处理器。仅用33.37分钟即可完成ResNet50模型培训,该服务器在单服务器性能方面排名第一。
本次基准测试中,浪潮展示出了卓越的AI计算软硬件协同优化能力。在硬件层面,通过对CPU、GPU硬件性能的精细校准和全面优化,使CPU性能、GPU性能、CPU与GPU之间的数据通路均处于对AI推理最优状态。
在软件层面,结合GPU硬件拓扑对多GPU的轮询调度优化使单卡至多卡性能达到了近似线性扩展;在深度学习算法层面,结合GPU Tensor Core 单元的计算特征,通过自研通道压缩算法成功实现了模型的极致性能优化,在精度无损的情况下性能提升近2倍。
宁畅X640将多卡性能发挥到极致
AI服务器所能支持异构计算GPU卡数量,是决定其AI吞吐量的首要因素。依托团队10余年行业经验,宁畅在全国率先在4U标准机箱中实现21张GPU卡配置,将多GPU卡性能优势发挥到极致。
搭配21张T4 GPU卡的X640 G30,在图像分类、语义识别等众多AI基准测试中,超越搭配20张T4 GPU卡配置的服务器,测试分数斩获14项世界第一。
不仅多GPU卡的性能优越,在单GPU卡平均性能方面(单卡平均性能=整机测试结果/搭载GPU卡个数),横向比较13家服务器厂商提交MLPerf 的53个配置测试结果显示,X640 G30服务器平均单卡性能获得11项第一。
结语
宁畅工程师表示,宁畅服务器不仅在MLPerf平台取得多项世界第一成绩,今年早先时候宁畅双路服务器R620 G30,曾在反映服务器性能的SPEC CPU2017测试中,刷新24项世界纪录。世界纪录的背后,是宁畅工程师为用户提供更优性价比产品,将CPU、GPU等服务器核心部件性能发挥到极致,所做的不懈努力。通过提供硬件、软件等定制化服务,宁畅服务器将有效降低用户TCO
浪潮是全球领先的AI计算领导厂商,其AI服务器在中国的市场份额已连续三年保持在50%以上。浪潮致力于AI计算平台、资源平台和算法平台的研发创新,并通过元脑生态与AI领先企业共同推进AI产业化和产业AI化进程。

作为业内知名峰会,搭载GPU的众多AI服务器自然成为行业关注焦点。那如何才能造出一台优秀的AI服务器?就此问题,服务器新锐厂商宁畅的答案,让人直感够硬核。
图说:宁畅X640 G30内部图
一年一度NVIDAGTC中国又来了!如何造一台优秀AI服务器?这家公司答案够硬核!