揭秘ChatGPT数据集之谜:背后的故事与挑战
ChatGPT是一种基于人工智能技术的语言模型,能够进行自然语言交互。然而,这个引人注目的技术背后隐藏着一个谜团:其数据集的故事与挑战。本文将深入探索ChatGPT数据集的来源、构建过程以及相关挑战。

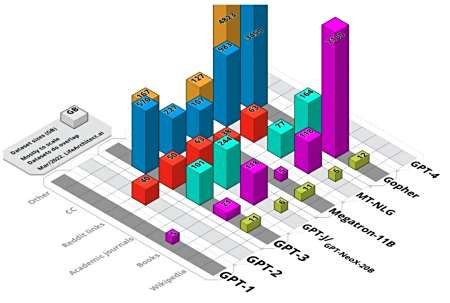
一、数据集来源
ChatGPT的数据集是通过对广泛的互联网文本进行训练而得到的。这些文本包括维基百科、论坛帖子、新闻文章等各种来源。OpenAI,作为ChatGPT的开发者,使用了一个自动化的爬虫程序来收集这些文本数据。
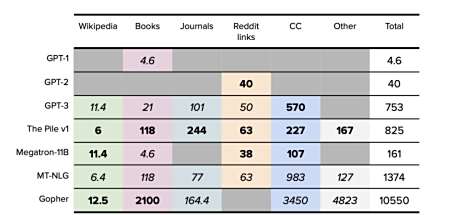
二、数据集构建过程
数据清洗:由于互联网文本的多样性,数据清洗是数据集构建的重要步骤。OpenAI使用了多种技术和算法来处理和过滤数据,以确保数据集的质量和一致性。这包括去除敏感信息、修复语法错误等。
人工筛选:数据清洗之后,OpenAI进行了人工筛选,以进一步过滤和纠正数据中的问题。这一过程涉及专业的团队成员对数据进行审核和编辑,以消除有害或不适当的内容,并提高模型的安全性。
三、数据集挑战与限制
内容偏差:由于数据集来源于互联网,其中包含了大量的偏见、主观观点和错误信息。这可能导致模型在回答问题或提供信息时出现偏差或不准确的情况,需要进行后期的校准和纠正。
不当言论:互联网上存在大量的不当言论和敏感内容,这些内容可能被模型学习并重复。OpenAI采取了严格的筛选和审核措施来减少这种风险,但无法完全消除。
隐私保护:数据集中可能包含使用者的个人信息和敏感内容,这对隐私构成一定的风险。OpenAI采取了措施来最小化这种风险,如匿名化处理和数据加密。
四、应对挑战的努力
为了解决数据集挑战带来的问题,OpenAI致力于改进ChatGPT的设计和训练方法。他们在增加多样性的同时,加强了模型对指令的理解和对不适当内容的处理能力。此外,OpenAI还与研究社区和使用者进行合作,接受反馈并进行模型的更新和改进。
ChatGPT是一项令人印象深刻的技术,但其数据集的背后却存在一系列故事和挑战。数据集的来源和构建过程需要经过细致的处理和筛选,同时面临内容偏差、不当言论和隐私保护等挑战。然而,OpenAI通过改进模型的设计和训练方法,并与社区合作,努力解决这些挑战,以提供更加准确、安全和可靠的ChatGPT服务。

