分布易用!亚马逊Invent2020官宣AI平台重大进展
在12月9日在线举行的AWS re:Invent 2020上,AWS Amazon Machine Learning副总裁Swami Sivasubramanian着重介绍了机器学习(ML)。这是一场讲座。在这里,他回顾上半年的内容,重点是SageMaker更新和用例。

AWS Amazon Machine Learning副总裁Swami Sibas Bramanian
通过Amazon Sage Maker实现分布式培训
本次机器学习案例开始于一个用户案例研究。使用ML预测比萨订单的Domino比萨,用于融资场景,用于汽车开发的BMW和用于增强购物体验的Nike都正在通过ML实现服务创新。选择它的原因是广度,深度和创新的服务速度, Sibas Bramanian介绍着,随后介绍了Sage Maker的更新。

AWS机器学习服务大致由三层组成:ML基础架构框架,Amazon SageMaker进行的ML开发以及利用ML的AI服务。Sibas Bramanian说:仅今年一年,我们已经增加了250多个新功能,我们很自豪能够提供最全面的ML工具。 正如他过去参与的Amazon S3和DynamoDB帮助基础设施采购工程师一样,机器学习现在也为所有技能水平的人们提供了发展的自由。
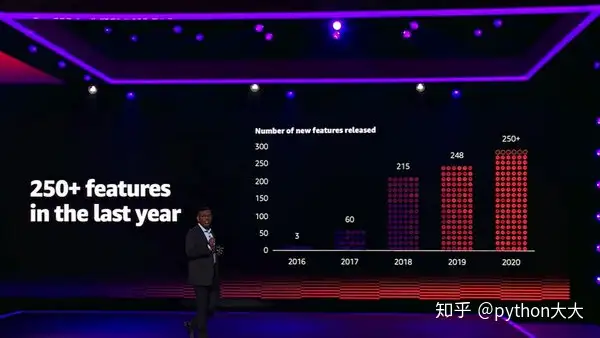
添加了250多个新功能
首先,介绍针对ML框架和机器学习优化的实例和硬件。首先,可以使用多种框架,例如TensorFlow,PyTorch,MXNet,并且吸引人的是,目前有92%的TensorFlow工作负载和91%的PyTorch工作负载正在AWS上运行。AWS还提供了针对机器学习进行了优化的实例,可以加快推理速度的Inferentia,以及用于训练处理的专用芯片(如Trainium)。
为了加快速度,SageMaker添加了促进分布式培训的功能。过去,2017年推出Sage Maker时,培训仅限于垂直扩展,但随后出现了分布式扩展。在此AWS实施中,可以使用数据分区和模型分区两种方法,并且只需添加几行代码即可自动实现对多个GPU实例的分布式处理。在基准测试中,使用TensorFlow进行的培训(用于计算机视觉的 Mask-RCNN花费了28分钟)现在为6分13秒。此外,在PyTorch进行的培训(原本用于自然语言处理的 T5-3B花费了几周的时间)已缩短至5.9天。

在NFL和Intuit中使用Sage Maker的示例
SageMaker是一个ML开发环境,可以高效地开发复杂且昂贵的机器学习。它是一个集成了一系列操作(如数据收集,算法选择,培训环境准备,培训和调整,部署和扩展)的环境,并且在去年引入了50多种新功能。
还介绍了SageMaker的用户。Rideshare LYFT可以将培训时间从每天缩短到每小时,T-Mobile是一家电信运营商,它简化了使用ML的客户消息标签以及ML的使用,例如加快了工作量并优化了交付路线应用程序在增加,创新也在加速。
国家橄榄球联盟(NFL)的珍妮弗·兰顿(Jennifer Lanton)作为用户案例登场。Lanton因大学期间的受伤而放弃了运动员的职业生涯,目前在NFL负责健康和创新,他促进了技术的使用以确保运动员的安全和健康。
下一代统计数据(Next Gen Stats)于2017年与AWS合作建立,可捕获Ameft游戏期间玩家的位置,速度和加速度,并实时对其进行分析。它不仅为球迷提供了享受比赛的分析能力,而且还通过数据分析帮助减少伤害。

詹妮弗·兰顿(Jennifer Lanton)在美国国家橄榄球联盟(NFL)负责健康和创新
在过去的六年中,NFL使用生物力学工程师来分析伤害并开发安全头盔以减少球员的大脑疲劳。根据数据开发的安全帽的使用率已经达到100%,并且在2018年,脑病减少了24%。Lanton说:使用更好的头盔和保护器,安全处理并更改规则。这是由于数据和创新所致。
NFL正在继续使用Computer Vision和SageMaker进行数据分析,并计划将应用范围不仅扩展到脑损伤,还扩展到脚踝受伤。最终,不仅在考虑NFL,而且还考虑回馈社会以减少伤害。
Intuit使通过机器学习轻松提交最终声明成为可能。机器学习已经是他们业务的重要组成部分,并且被用于欺诈检测,客户服务和个性化。仅去年一年,我们就将模型数量增加了50多种,降低了成本,并将审查时间减少了一半。 Sibas Bramanian呼吁:我们已经实现了这一目标。
为数据准备,特征量管理,偏差消除等创建高度精确的模型。
正如首席执行官Andy Jasie在主题演讲中提到的那样,使用SageMaker开发ML所面临的挑战是数据预处理,这占总数的80%。上周宣布了 SageMaker Data Wrangler,以减轻无差异的负担。从各种来源收集的数据可以根据300多种预配置的逻辑进行转换,并且可以在SageMaker Studio中按原样检测并消除不一致之处。除了Amazon S3,Athena,Redshift,LakeFormation作为来源之外,还将很快宣布与Snowflake,Databricks和MongoDB等第三方合作。

可以使用多种资源并与第三方合作
上周,我们还宣布了 Amazon Sage Maker Feature Store,该存储库集成和管理ML开发中的重要功能。可以说是机器学习关键的功能以集成方式进行管理,可以低延迟地进行搜索,并且可以轻松地重用。
接下来,Sibasbramanian先生提出了机器学习中的偏见问题。偏差在这里表示数据中的偏差会妨碍模型的透明度。例如,如果您想创建一种算法来显示在还清抵押贷款之前可能患上大病的算法,如果您拥有大量针对中老年人的数据,而针对年轻人的数据却很少,那么您的预测就会有偏差。另外,即使在概念漂移的情况下,机器学习的精度也会随着时间而下降,因此数据偏差也成为问题。他指出:模型的预测准确性取决于数据和特征,因此我们必须了解模型所使用的数据的偏差,并知道该模型为何做出这种预测。
为了应对这一挑战,最近宣布了可在机器学习工作流程中启用偏差检测的Amazon SageMaker Clarify。AWS ML的Nashley Sefias博士说:偏差出现在ML工作流的许多部分,即使具有不同的专业知识,也很难将它们从ML中删除。 相反,SageMaker Clarify通过一系列工作流程(包括准备期间的数据不平衡和训练后的连续偏差监视)检测偏差,从而提高了模型的透明度。可以将偏差检测为警报,并可以据此更改标签。

AWS ML Nashley Sefias博士解释SageMaker
也是最近宣布的 Amazon SageMaker Debugger中的深度分析是Amazon SageMaker Debugger的一项新功能,用于监视系统资源。概要分析您的一些或所有培训工作,并输出硬件层指标,例如CPU,GPU,网络和存储I / O,以及每个阶段的数据负载。根据分析和建议重新分配资源,以减少培训时间和成本。
在SageMaker中创建具有"可跳舞性"功能的播放列表
随着SageMaker的新服务和功能陆续宣布,机器学习的发展将如何变化?Matt Wood博士向我们展示了一个易于理解的演示。伍德说:建立高度精确的ML模型非常重要。SagaMaker不会妨碍建立ML模型,它只留下钻石。

Matt Wood博士展示了ML开发工作流程
伍德先生展示了如何制作模型来制作出色的播放列表。由于音乐数据具有诸如歌曲标题,流派和节奏的数据,因此这是生成称为可跳舞性的特征量并生成播放列表的示例。
首先,具有各种转换逻辑的Data Wrangler可以轻松地将表格数据转换为要素,然后将数据加载到Future Store中。另外,如果使用Clarify,则可以使用平衡良好的数据和特征量,并且可以创建不偏向特定类型的平衡良好的模型。在改进模型时,您可以使用调试器来优化资源分配和管道,以实现连续CI / CD。可以说,持续的质量控制以及模型构建是此公告的重点。
回到舞台,Sibas Bramanian还提到在边缘设备上部署ML模型。边缘设备资源有限,数量众多,并且经常在移动环境中使用,这使得合并最新的ML环境变得困难。AWS在2018年发布了 SageMaker Neo,该版本实现了针对资源少的边缘设备优化的ML部署,但是这次发布了 SageMaker Edge Manager。
SageMaker Edge Manager可在各种设备(例如智能相机,机器人和移动设备)上优化,保护,监视和维护ML模型。来自边缘设备的预测数据可以定期发送到云中,并且可以使用Sage Maker Model Monitor进行漂移检测和重新学习,以不断提高模型的质量。

宣布SageMaker Edge Manager
