云原生的弹性AI训练系列之一:基于AllReduce的弹性分布式训练实践
这篇文章首发于腾讯云原生公众号,是我跟我的同事张望一起完成。
引言
随着模型规模和数据量的不断增大,分布式训练已经成为了工业界主流的 AI 模型训练方式。基于 Kubernetes 的 Kubeflow 项目,能够很好地承载分布式训练的工作负载,业已成为了云原生 AI 领域的事实标准,在诸多企业内广泛落地。尽管 Kubeflow 让基于 Kubernetes 的大规模分布式训练变得可行,但是云原生的极致弹性、降本增效等特性在人工智能场景下没有得到很好地释放。
为了解决目前在云原生 AI 场景下的成本高,资源利用率低等问题,TKE AI 团队在 Kubeflow 社区中推动了弹性训练特性的设计与实现。
在这一文章中,我们主要介绍了数据并行的分布式训练任务的弹性能力在 Kubernetes 上的设计与实现。并且通过实验的方式验证了特定的场景下,在保证训练精度的同时,这一特性能够使成本降低 70%。
背景
首先我们简要回顾一下深度学习的模型训练。这里所说的训练,指的是利用数据通过计算梯度下降的方式迭代地去优化神经网络的参数,最终输出网络模型的过程。在这个过程中,通常在迭代计算的环节,会借助 GPU 进行计算的加速。相比于 CPU 而言,可以达到 10-100 倍的加速效果。而分布式的模型训练,最早是由 Mu Li 在 OSDI’14 上提出的。在传统的模型训练中,迭代计算的过程只能利用当前进程所在主机上的所有硬件资源。但是单机的扩展性始终是有限的,在数据集规模特别大或者模型特别复杂的时候,单机训练的速度就会有些捉襟见肘。分布式的训练可以借助不同主机上的硬件资源进行训练加速,大大提高训练速度。
Horovod 是一款基于 AllReduce 的分布式训练框架。凭借其对 TensorFlow、PyTorch 等主流深度学习框架的支持,以及通信优化等特点,Horovod 被广泛应用于数据并行的训练中。在 Horovod 中,训练进程是平等的参与者,每个进程既负责梯度的分发,也负责具体的梯度计算。如下图所示,三个 Worker 中的梯度被均衡地划分为三份,通过 4 次通信,能够完成集群梯度的计算和同步。
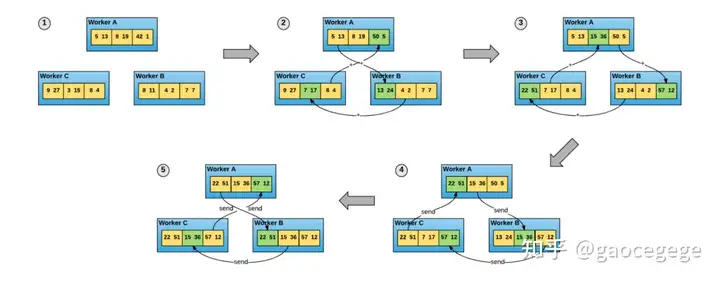
依托 AllReduce 的分布式训练由于其简单易懂的编程逻辑和大幅提升的训练速度,逐渐成为分布式训练的主流方式。然而,当前这种模式依然存在一些问题:
- 首先,AI 训练的成本问题显著。借助于 Kubernetes,大规模分布式训练虽然已经不再复杂,但是高昂的训练成本使得这项技术难以真正做到普惠。
- 其次,相比于单机的训练,分布式训练有更大的可能出现任务失败的情况。在分布式训练中,有多个进程同时参与训练,而其中的某个进程出现了问题,整个训练任务都会因此而失败。尤其是当训练任务需要持续几天甚至几个礼拜时,这个问题就会显得尤为严重。
- 同时,由于一些混部的集群存在业务压力周期性波动的特性,在闲时 GPU 占用率通常不到 40%。但是与之相对的是,在任务密集提交时,集群的资源又会出现紧张的情况。资源利用在时间上的不均衡问题非常突出。
弹性训练
为了解决上述问题,更好地向分布式训练释放云原生的红利,业界提出了弹性训练这一概念。
在传统的深度学习分布式训练任务中,通常任务的实例配置是固定的。这很大程度上限制了任务的灵活性和训练速度,对于整个集群的资源利用率而言也不友好。而弹性训练,就是指让训练任务能够在运行时动态地调整参与计算的实例数量。这使得训练更加灵活,同时可以配合集群的负载进行更好的扩缩容和调度。这一特性为训练场景带来了诸多收益:
- 容错性的提升。在这样的选型下,所有实例的失败都是可以容忍的。任务不再会因为某个进程出错而导致任务整体的失败。
- 资源利用率的提升。在集群资源紧张时,通过减少低优先级训练任务的实例数量,能够保证高优先级训练任务的资源配额,保证业务的 SLA。在集群资源闲置时,又可以通过创建更多实例加入训练的方式,将原本闲置的 GPU 等资源利用起来,加速训练。这不仅使得任务的训练速度得到了提升,同时也提高了集群的资源利用率。
- 实现云原生的 AI 训练,配合竞价实例等云上资源更好地降低上云成本。竞价实例相比于按量付费等实例有着非常大的成本优势,但是也面临着随时可能被回收的问题。弹性训练能够完美地契合这一场景,在竞价实例可用时,在竞价实例中创建训练任务,在竞价实例被回收时,训练任务仍然能够继续下去。
弹性分布式训练能够很好地解决分布式训练在成本、资源利用率和容错等方面的问题。尽管看起来弹性训练只是能够将训练任务的实例动态调整,但是它能够与公有云提供的云原生能力产生相互的作用,产生更大的价值。在我们实际的测试中,基于 Horovod 的弹性训练在竞价实例上,可以将每 GPU 时的花费从 16.21 元降低到了 1.62 元,整个模型训练的成本可以下降接近 70%。而如果在保持花费不变的情况下,竞价实例上的弹性模型训练可以购买到更多的 GPU 卡,训练速度能够提升 5 到 10 倍。原本需要一天的训练任务,可以在几个小时内完成。更进一步地,结合弹性训练与集群调度,有更多的可能性可以探索。
Horovod 是目前在数据并行的分布式训练中应用最多的训练框架之一,因此我们以训练框架 Horovod 为例,介绍 Horovod 的弹性训练方案如何在云原生的环境下落地。
Horovod Elastic
Uber 开源的 Horovod 框架作为数据并行模式下广泛使用的训练框架,在 2020 年夏天也开始着手解决弹性训练这个需求。最终 Elastic Horovod 在 Horovod v0.20.0 版本发布中面世。
为了实现弹性训练的能力,Horovod Elastic 对 Horovod 的架构和实现进行了一定的修改,其中主要包括:
- 聚合操作需要被定义在
hvd.elastic.run函数下 - 每个 worker 都有自身的状态(state),且在训练之前会被同步一次
- worker 的增减会出发其他 worker 上的重置(reset)事件
- 重置事件会激活以下几个操作(不一定全部执行): a. worker 是否应该继续运行 b. 将失效的 worker 列入黑名单 c. 在新的 hosts 上启动 worker 进程 d. 更新 worker 的 rank 信息
- 在重置事件之后,每个 worker 的状态会被同步
在实际操作中,用户需要向horovodrun提供一个discover_hosts.sh脚本,用以实时反馈当前可用的 hosts 以及每个 hosts 上的 slots(以下用discover_hosts.sh指代该脚本,但该脚本无需命名为discover_hosts.sh)。
Horovod Elastic on Kubernetes
在 Elastic 功能推出之前,Kubeflow 社区的 MPI-Operator 是将 Horovod 部署并运行在 Kubernetes 集群上的主流方案。MPI-Operator 虽然经历 v1alpha1、v1alpha2 和 v1 三个版本,但大体上的思想一致。其主要过程包括:
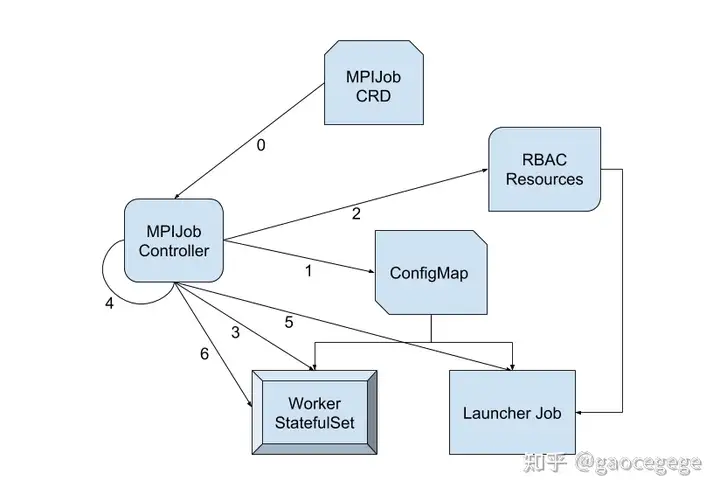
- MPIJob Controller 会根据每一份 MPIJob 的配置,生成一个 launcher pod 和对应个数的 worker pod
- MPIJob Controller 会针对每一份 MPIJob 生成一份 ConfigMap,其中包含两份脚本,一为反应该任务所有 worker pod 的
hostfile,一为kubectl可执行文件 - Launcher pod 上的
mpirun会利用由 ConfigMap 中的kubectl在 worker pod 中拉起进程;需要注意的是,kubectl的执行有赖于 MPIJob Controller 预先创建的 RBAC 资源(如果对应的 Role 中没有给 launcher pod 配置在 worker pod 上的执行权限,launcher pod 在执行kubectl exec时会被拒绝)
此前,MPI-Operator 和 Elastic Horovod 存在几个兼容性上的问题。由于 MPI-Operator 的三个版本间存在些许差异,我们这里只讨论 v1 版本:
- MPI-Operator 尚不提供
discover_hosts.sh,这一点直接导致 Elastic Horovod 无法使用 - 当用户将 worker replicas 调小之后,controller 不会对额外的 worker pod 采取任何措施,这会导致 worker pod 无法释放,训练任务的实例规模也就无法缩小
- 当用户增大 worker replica 后,controller 并不会为 launcher pod 的 Role 配置新增 worker 的执行权限,这会导致 launcher pod 上的 horovodrun 在试图利用
kubectl在新创建的 worker pod 上执行进程时被 Kubernetes 的权限管理机制拒绝
基于这些存在的兼容性问题,我们在社区上提出了 Elastic Horovod on MPIJob:https://github.com/kubeflow/mpi-operator/pull/335。配合对 Horovod 的修改https://github.com/horovod/horovod/pull/2199,能够在 Kubernetes 上实现 Horovod 的弹性训练。
在该方案中,最关键的问题在于如何在 launcher pod 上实现discover_hosts.sh的功能。而在 Kubernetes 上实现该功能的关键,在于如何获取当前处在 Running 状态的 worker pods。这里有两种思路。
- MPIJob Controller 构建
discover_hosts.sh并通过 ConfigMap 同步至 launcher pod - MPIJob Controller 本身就在监听 pods 相关的信息,利用 controller 内的 podLister,可以很快地列出每一个 MPIJob 的 worker pods;
- 根据 pods 的 status.phase,controller 在筛选出 Running 状态的 worker pods 之后,就可以构建出一份反映当前 worker pods 状态的
discover_hosts.sh; - 通过 ConfigMap,controller 可以将
discover_hosts.sh像hostfile、kubectl脚本一样同步至 launcher pod。
- 利用 launcher pod 内已有的
kubectl向 APIServer 实时获取 worker pod 信息 - Launcher pod 自身已经绑定了 pods 的 get 和 list 权限,通过
kubectl或者其他 Kubernetes client 的直接调用,即可获取对应 pod 信息,通过一样的筛选标准也可以返回 Elastic Horovod 期待的信息。
考虑到第二种思路无法限制用户执行discover_hosts.sh的频率,如果用户执行过于频繁或是 MPIJob 规模较大的情况下,会对 Kubernetes 集群造成较大的压力,第一种思路在管控上更为全面。
一种对思路二的修正是将kubectl或是 client 改为一个 podLister 运行在 launcher pod 中,从而降低对 APIServer 的压力。然而这种方式使得 launcher pod 中运行了两个进程。当这个 podLister 进程失效时,缺乏合适的机制将其重新拉起,会造成后续的弹性训练失效。
根据第一种思路,controller 通过 ConfigMap 将discover_hosts.sh同步至 launcher pod 内,并挂载于/etc/mpi/discover_hosts.sh下。同时,该提议中也对 controller 针对另外两个兼容性问题做了相应的修改。这些修改并不会影响到非 Elastic 模式的 MPI 任务,用户只需忽略discover_hosts.sh即可。
当然这种方案也存在一定的问题。ConfigMap 同步至 launcher pod 存在一定的延迟。然而一方面,这个延迟时间是 Kubernetes 管理员可以进行调整的。另一方面相比整个训练所花的时间,同时也相比 Elastic Horovod 在重置上所花的时间,这一部分延迟也是可以接受的。
弹性训练演示
最后,我们通过一个示例来演示如何在 Kubernetes 上运行 Horovod 弹性训练任务。任务创建的过程与普通的训练任务类似,即通过 MPIJob 创建。
bash-5.0$ kubectl create -f ./tensorflow-mnist-elastic.yaml
mpijob.kubeflow.org/tensorflow-mnist-elastic created
bash-5.0$ kubectl get po
NAME READY STATUS RESTARTS AGE
tensorflow-mnist-elastic-launcher 1/1 Running 0 14s
tensorflow-mnist-elastic-worker-0 1/1 Running 0 14s
tensorflow-mnist-elastic-worker-1 1/1 Running 0 14s在示例中,我们一共创建了两个 worker 参与训练。在训练开始后,调整MPIJob.Spec.MPIReplicaSpecs["Worker"].Replicas实例数量,增加一个新的 worker 后,观察实例数量。新的 worker 加入训练,完成数据集的获取和初始化之后,训练任务会不中断地继续训练。其中discover_hosts.sh的内容如下:
bash-5.0$ kubectl exec tensorflow-mnist-elastic-launcher -- /etc/mpi/discover_hosts.sh
tensorflow-mnist-elastic-worker-0:1
tensorflow-mnist-elastic-worker-1:1
bash-5.0$ kubectl edit mpijob/tensorflow-mnist-elastic
mpijob.kubeflow.org/tensorflow-mnist-elastic edited
bash-5.0$ kubectl exec tensorflow-mnist-elastic-launcher -- /etc/mpi/discover_hosts.sh
tensorflow-mnist-elastic-worker-0:1
tensorflow-mnist-elastic-worker-1:1
tensorflow-mnist-elastic-worker-2:1最后,我们再尝试把实例数量调整为一,训练集群中的两个实例会被回收,而训练仍然会继续。
bash-5.0$ kubectl edit mpijob/tensorflow-mnist-elastic
mpijob.kubeflow.org/tensorflow-mnist-elastic edited
bash-5.0$ kubectl get po
NAME READY STATUS RESTARTS AGE
tensorflow-mnist-elastic-launcher 1/1 Running 0 4m48s
tensorflow-mnist-elastic-worker-0 1/1 Running 0 4m48s
tensorflow-mnist-elastic-worker-1 1/1 Terminating 0 4m48s
tensorflow-mnist-elastic-worker-2 1/1 Terminating 0 2m21s日志如下
...
Thu Mar 11 01:53:18 2021[1]:Step 40 Loss: 0.284265
Thu Mar 11 01:53:18 2021[0]:Step 40 Loss: 0.259497
Thu Mar 11 01:53:18 2021[2]:Step 40 Loss: 0.229993
Thu Mar 11 01:54:27 2021[2]:command terminated with exit code 137
Process 2 exit with status code 137.
Thu Mar 11 01:54:27 2021[0]:command terminated with exit code 137
Process 0 exit with status code 137.
Thu Mar 11 01:54:57 2021[1]:[2021-03-11 01:54:57.532928: E /tmp/pip-install-2jy0u7mn/horovod/horovod/common/operations.cc:525] Horovod background loop uncaught exception: [/tmp/pip-install-2jy0u7mn/horovod/third_party/compatible_gloo/gloo/transport/tcp/pair.cc:575] Connection closed by peer [10.244.2.27]:54432
WARNING:root:blacklist failing host: tensorflow-mnist-elastic-worker-2
WARNING:root:blacklist failing host: tensorflow-mnist-elastic-worker-1
Thu Mar 11 01:54:58 2021[1]:Step 50 Loss: 0.207741
Thu Mar 11 01:55:00 2021[1]:Step 60 Loss: 0.119361
Thu Mar 11 01:55:02 2021[1]:Step 70 Loss: 0.131966 这说明通过 MPIJob 的支持,Horovod Elastic 能够手动地扩缩容,满足业务需要。在后续的工作中,我们会继续支持配合 HorizontalPodAutoscaler 的自动扩缩容、指定实例的缩容等高级特性,以满足更多的场景。
总结
在云原生技术不断扩展新的场景边界的过程中,以弹性训练为代表的 AI 基础设施新潮流一定会逐渐在工业界落地,与云原生进行更好地融合,在 AI 场景下充分发挥云计算的价值,帮助业务降本增效。
目前,腾讯云原生 AI 团队正在积极与 PyTorch、Horovod 等开源社区合作,推进弹性训练能力在 Kubeflow 中的落地。在这一系列后续的文章中,我们会逐步介绍在 PS Worker 训练的弹性能力,以及在资源管理和优先级调度等方面的联合优化,分享我们在这一方向上的探索和落地实践。
参考文献
- Li, Mu, et al. Scaling distributed machine learning with the parameter server. 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14). 2014.
- 腾讯机智团队分享–AllReduce算法的前世今生
- Uber Blog: Horovod
- Elastic Horovod

