AI画画背后的技术原理是什么样的
作者:yichaozhou,腾讯 PCG 应用研究员
AI 画画这个领域发展太快了,要知道去年的 AI 画画还是这个画风的:

现在的 AI 画画已经迅速进化到这个程度:
施法咒语长这样——
film still, [film grain], large crowds, cyberpunk street, street level photograph, Chinese neon signs, time square advertisements, Dark atmospheric city by Jeremy Mann, Nathan Neven, James Gilleard, James Gurney, Makoto Shinkai, Antoine Blanchard, Carl Gustav Carus, Gregory Crewdson, Victor Enrich, Ian McQue, Canaletto, oil painting, brush hard, high quality, (brush stroke), matte painting, (very highly detailed)
生成结果长这样——

关于近期各个模型的惊人结果现在应该已经有很多文章介绍了,本文主要想尽可能直白地解释 AI 画画的原理。因为这块也是最近才开始涉及,有些地方如果没理解对,欢迎指正和交流。
一、计算机如何生成图画
让我们言归正传,AI 是怎么学会画图的呢?
这就要涉及到两个方面了。一个是能生成出像真实图片一样的数据,一个是要听得懂我们想要它生成什么,并给出对应的结果。
首先来说说看如何生成出像真实图片一样的数据。这涉及到机器学习中的一个重要分支——生成模型(generative model)。对于生成图像这个任务来说,通常一个生成模型需要先吞进大量的训练数据(巨量的人类真实图片),然后再学习这些数据的分布,去模仿着生成一样的结果。机器学习的核心无非就是这么回事,难点终究是在如何设计模型让模型能更好学到这样的分布上。
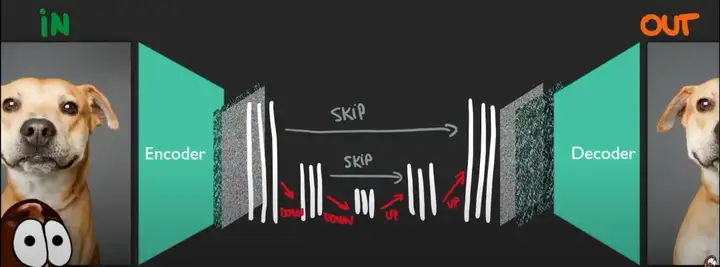
要讲生成模型,有一个不得不提的技术就是 VAE,变分自编码器,即 variational auto-encoder。这其中的 auto-encoder,虽然叫 auto-encoder 但是其实包含了编码器 encoder 和解码器 decoder,是一个对称的网络结构。对于一系列类似的数据,例如图片,虽然数据量很大但是其实是符合一定分布规律的,信息量远小于数据量。编码器的目的就是把数据量为 n 维的数据压缩成更小的 k 维特征。这 k 维特征尽可能包含了原始数据里的所有信息,只需要用对应的解码器,就可以转换回原来的数据。在训练的过程中,数据通过编码器压缩再通过解码器解压,然后最小化重建后数据和原始数据的差。训练好了以后,就只有编码器被用作特征提取的工具,用于进一步的例如图像分类等应用中,故称为 autoencoder。
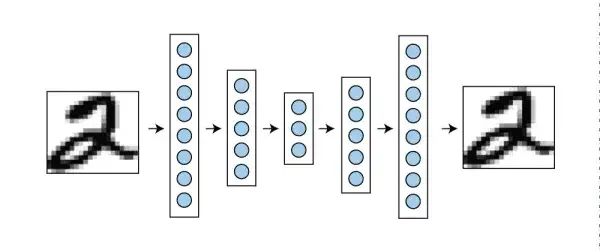
这时候有人想到,既然 auto-encoder 可以从 k 维特征向量恢复出一整张图片,那我给你一个随机生成的 k 维特征向量,是否也可以随便生成什么画面呢?然而实际结果显示,autoencoder 虽然可以记住见过的照片,但是生成新图像的能力很差。于是有了 variational auto-encoder。VAE 在令 k 维特征中的每个值变成了符合高斯分布的概率值,于是对概率的改变可以让图片信息也有相应的平滑的改变,例如某个控制性别的维度,从 0 到 1 可以从一个男性的人脸开始,生成越来越女性化的人脸。

通过控制特征变量来操控人脸生成结果
那么 VAE 其实还是有很多统计假设的,而且我们要判断它生成的效果如何,也需要评估它生成的数据和原始数据的差距大不大。于是有人丢掉所有统计假设,并且把这个评估真(原始数据)假(生成数据)差异的判别器也放进来一起训练,创造了 GAN,生成对抗神经网络。GAN 有两个部分,生成器和判别器。生成器从一些随机的 k 维向量出发,用上采样网络合成大很多的 n 维数据,判别器就负责判断合成出来的图片是真是假。一开始合成出来的都是意义不明的无规律结果,很简单的判别器就可以分辨出来。生成器发现一些生成的方向,比如有成块的色块,可以骗过判别器,它就会往这个方向合成更多的图片,而判别器发现被骗过去了,就会找到更复杂的特征来区分真假。如此反复,直到生成器生成的结果,判别器已经判断不出真假了,这就算是训练好了。这样训练出来的生成器,可以生成非常逼真,即使是人眼也很难分辨的图片,但是是不存在的。到了这时候,计算机已经能学会生成相当逼真的画面了,例如下面这张人脸:

虽然 GAN 因为引进了判别器,能生成非常逼真的图片,但是 GAN 由于要训练对抗网络,实在是太不稳定了,面对吞噬了网络巨量数据的超大规模网络来说非常难以控制。于是这时候另一个更好的选择出现了,也是现在的 AI 画画普遍使用的生成模型——diffusion model(扩散模型)。
Diffusion model 生成图片的过程看似很简单,其实背后有一套非常复杂的数学理论支撑。复杂的理论先放一边,我们先看看 diffusion model 是怎么运行的。
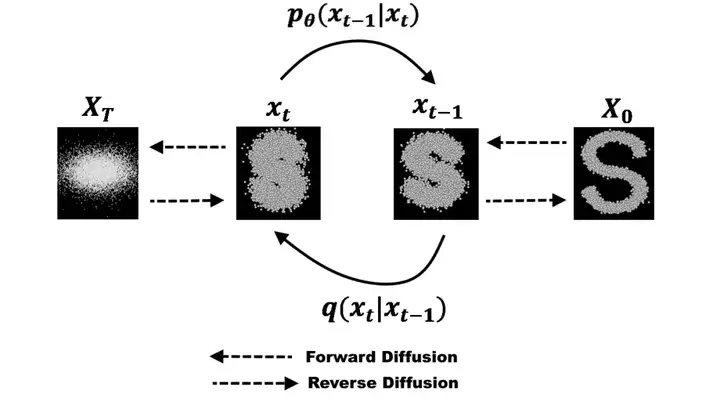
上图是 diffusion model 的两个过程。右边是一个正常的图片,从右到左(Forward Diffusion)做的事情是在逐次叠加符合正态分布的噪声,最后得到一个看起来完全是噪声的图片,这就是所谓的扩散(diffusion)过程。你可以不严谨地想象成你有一块牛排,你在一遍一遍地往上撒椒盐,一直到整块牛排都被椒盐覆盖看不清原来的纹路。由于每次加噪声只和上一次的状态有关,所以是一个马尔科夫链模型,其中的转换矩阵可以用神经网络预测。
从左到右(Reverse Diffusion)做的事情是一步步去除噪声,试图还原图片,这就是 diffusion model 的生成数据过程。
那么为了达到去噪的目的,diffusion model 的训练过程实际上就是要从高斯噪声中还原图片,学习马尔科夫链的概率分布,逆转图片噪声,使得最后还原出来的图片符合训练集的分布。
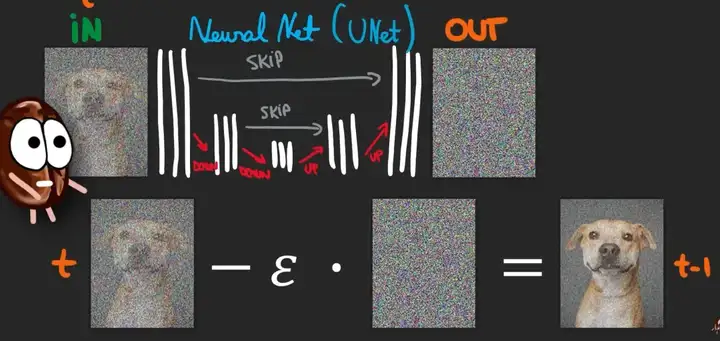
这个去噪的网络是如何设计的呢?我们可以从叠加噪声的过程中发现,原图和加噪声后的图片尺寸是完全一样的!于是很自然能想到用一个 U-net 结构(如下图)来学习。
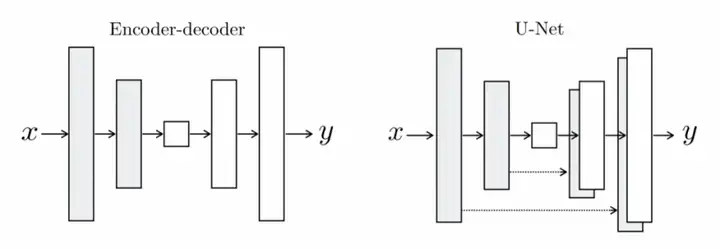
U-net 是一个类似 auto-encoder 的漏斗状网络,但在相同尺寸的 decoder 和 encoder 层增加了直接的连接,以便于图片相同位置的信息可以更好通过网络传递。在去噪任务中,U-net 的输入是一张带噪声的图片,需要输出的是网络预测的噪声,groundtruth 是实际叠加上的噪声。有了这样一个网络,我们就可以预测噪声,从而去除掉它还原图片。因为带噪声的图片=噪声+图片。这也是为什么 diffusion model 会比其他方法生成图片更慢,因为它是需要一轮一轮去噪的,而不是网络可以一次性推理出结果。
以上就是 diffusion model 生成图片的原理,是不是很简单呢!
二、如何控制画面内容
上面解释了计算机如何生成和真实图片相似的图画。接下来解释一下模型是如何理解我们想要它生成什么并给出对应的结果的。
玩过 AI 画画的人应该都知道,AI 画画最主流的模式是在网页输入框中输入一长串吟唱咒语,其中包括想要生成的内容主体、风格、艺术家、一些 buff 等,点击生成后就可以得到一张非常 amazing 的结果(也可能很吓人)。
文字控制模型生成画面最早的做法,其实更像是让生成模型生成一大堆符合常理的图片之后,再配合一个分类器来得到符合条件的结果。在海量的数据面前这显然是不够用的。这个领域的开山之作——DALL·E 中最值得一提的是引入了 CLIP 来连接文字和图片。
这个 CLIP 模型,其实就是用了巨量的文本+图片数据对(互联网可以爬很多很多很多),把图片和文本编码后的特征计算相似性矩阵,通过最大化对角线元素同时最小化非对角线元素,来优化两个编码器,让最后的文本和图片编码器的语义可以强对应起来。
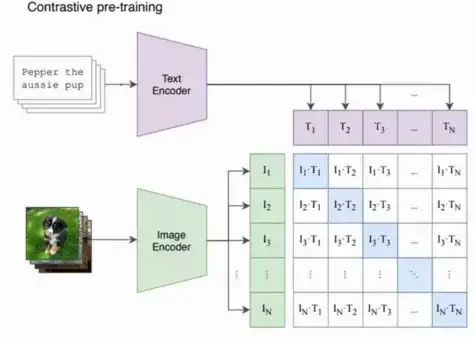
如果不能理解 CLIP 的原理,只要记住 CLIP 把文字和图片对应起来了就可以了。它最大的成功之处不是用了多复杂的方法,而是用了巨量的数据。这样带来的好处是,很多现有的图像模型可以很容易扩展成文本控制的图像模型。原本需要大量人工标注的很多任务,现在只需要用集大成的 CLIP 就可以了,甚至还可能生成新数据,例如在 StyleCLIP 里用文本交互控制生成的人脸:

最开始图片的文字信息大多是以打标签的形式通过大量人工标注来完成,有了 CLIP 以后可以说是彻底打通了文字和图片之间的桥梁,使得图像相关的任务得到大大的扩展,可以说是 AI 画画的基石也不过分。有了这个 CLIP 模型,我们就可以计算任意图片和文本之间的关联度(即 CLIP-score),拿来指导模型的生成了。
这一步其实还分为了几个发展阶段。最开始用的方法(Guided Diffusion)很 naive,就是每次降噪后的图片,都计算一次和输入文本之间的 CLIP-score。原本的网络只需要预测噪声,现在网络不但要预测噪声还需要让去噪后的结果图尽可能和文本接近(也就是 CLIP-loss 尽量小)。这样在不断去噪的过程中,模型就会倾向于生成和文本相近的图片。由于 CLIP 是在无噪声的图片上进行训练的,这边还有一个小细节是要对 CLIP 模型用加噪声的图片进行 finetune,这样 CLIP 才能看出加噪声后的牛排还是一块牛排。
这样做的好处就是 CLIP 和 diffusion model 都是现成的,只需要在生成过程中结合到一起。但缺点是本来就已经很慢的 diffusion model 生成过程变得更慢了,而且这两个模型是独立的,没法联合训练得到更进一步的提升。
于是就有了 Classifier-Free Diffusion Guidence,模型同时支持无条件和有条件的噪声估计,在训练 diffusion model 时就加入文本的引导。这样的模型当然也离不开很多很多的数据和很多很多的卡,除了网络爬取的还有商业图库,构造出巨量的图片和文本对,最后作为成品的 GLIDE 在生成效果上又达到了一次飞跃。虽然现在看有点简陋,但是在当时来说已经很惊人了,恭喜大家看到这里终于追上了 21 年末的进度!

再衍生一下,如果你玩得更花一点,或者试过 AI 给你画头像,这时候输入条件就变成了图片,那么这样要怎么控制生成的结果呢?
这里有几种不同的方法,其实算是不同流派了。
第一种是直接提取图片的 CLIP 特征,就像文字特征一样去引导图片。这样生成出来的结果,图片的内容比较相近,但结构不一定相同。例如下图,模型生成了相似的内容但是完全没有学到超越妹妹的一分美貌呢!

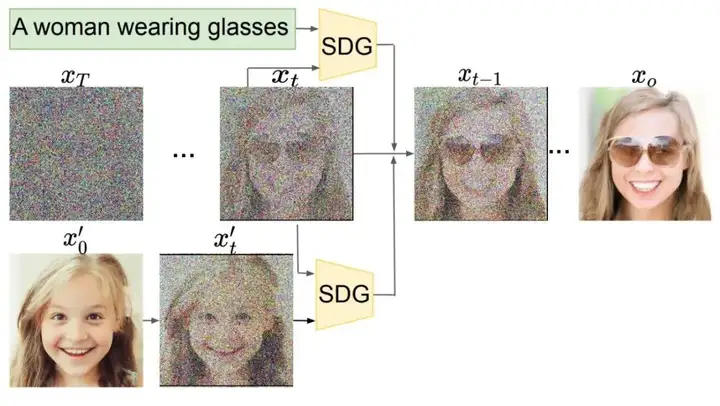
第二种特别好理解,现在主流的 AI 画画 webui 里的 img2img 都是采用这个方法。就是对输入的原图增加几层噪声,再以这个为基础进行常规的去噪。使用你希望的画风相应的咒语,就可以生成和你原图结构类似但画风完全不同的图片。叠加的噪声的强度越高,生成的图片和原图就差距越大,AI 画画的发挥空间就越大。

上图是用这个方法生成的二次元美少女,你把屏幕放远点看这两张图的色块是相近的。因为右边的图片就是基于左边叠加了厚厚的椒盐来作为基础生成的,大致的色块结构依然保留了,但模型也加上了自己的想象(通过文本引导)。
第三种方法是用对应的图片去 finetune 生成网络(Dreambooth),如下图。给模型看很多很多小狗狗的图,让模型学到这只小狗狗的样子,这样只需要再加上一些简单的词汇就可以生成各种各样的小狗狗啦!是不是很可爱呢!

三、为什么 AI 画画效果如此惊人
上面解释了计算机如何生成和真实图片相似的图画,以及模型是如何听懂我们想要它生成什么并给出对应的结果的。到此为止 AI 画画的基本原理已经介绍得差不多了。只想知道 AI 画画原理的话看到这里就可以结束了。
本文最后一部分虽然是选读,但也是 2021 年后至今 AI 画画飞速发展关键的一步。虽然主要都是改进的工作,原理上很无聊没什么说头,但是效果是真的很惊人!不过这块涉及到很多训练网络的 tricks,也许有一定的基础阅读起来会更轻松。
现在最火热的模型就是 Stable Diffusion,因为开源又效果好得到了众多喜爱。另外基于此吸收了巨量二次元插画的 NovelAI 也在二次元画风上异军突起,甚至在火热程度上和 Stable Diffusion 相比有过之而无不及,也是本人入坑的最大契机(谁不想每天的工作就是面对纸片美少女呢)。
讲 Stable Diffusion 为什么这么好,要先从 Latent Diffusion Model 谈起。
让我们来复习一下 diffusion model 的原理:
对一个带噪声的输入图片,训练一个噪声预测 U-net 网络,让它能预测噪声,然后再从输入中减去,得到去噪后的图片。
一般的 diffusion model 是对原始图片进行加噪去噪,噪声图片和原始图片尺寸是一样的。为了节约训练资源和生成时间,通常会用较小的图片尺寸训练,再接一个超分辨率模型。

而在 Latent Diffusion Model 中,diffusion 模块被用于生成 VAE 的隐编码。于是整个流程变成了这样:
课程截图来自:YouTube - How does Stable Diffusion work?
图片先用训练好的 VAE 的 encoder 得到一个维度小得多的图片隐编码(可以理解为将图片信息压缩到一个尺度更小的空间中),diffusion model 不再直接处理原图,而是处理这些隐编码,最后生成的新的隐编码再用对应的 decoder 还原成图片。相较于直接生成图片像素,大幅度减少计算量与显存。
第二个改进是增加了更多的训练数据,并且还多了一个美学评分的过滤指标,只选好看的图片。这就像是如果想要学会画漂亮的画就要多看看大艺术家们的 masterpieces 一样。
训练集里都是漂亮的图片,比如这样的:

或者这样的:

反正就是什么电子包浆很厚的图啊,模糊的图啊,有水印的图啊,都给干掉了,让机器只从漂亮图片里学画画。
最后相比 Latent Diffusion Model 的改进是用上文提到的 CLIP 来让文本控制图片的生成方向。
最后提一下二次元画风的 NovelAI,其实在技术上没有非常新的内容,就是拿巨量二次元图片去 finetune 原始 Stable Diffusion 模型。主要一些改进是 CLIP 用了倒数第二层更贴近文本内容的特征、把训练数据扩展为长宽比不限(为了能容纳下完整的人像)、增加了可支持文本输入长度从而让咒语变得更灵活也更复杂。我个人认为效果好还是因为吞了巨量的图片外加宅宅们的热情让这个模型迅速发扬光大,甚至还有《元素法典》、《参同真解》等众多咒语书,更衍生出了众多辅助绘制工具,可能这就是爱吧!

