打造一个AI大模型,需要多少算力?
在席卷全球的AI热潮中,一个不容忽视的潜在阻力是算力的不足。算力是AI发展的基础设施,AI训练需要将数据集进行重复多轮处理,算力的大小代表着对数据处理能力的强弱。
据OpenAI测算,2012年开始,全球AI训练所用的计算量呈现指数增长,平均每3.43个月便会翻一倍,目前计算量已扩大30万倍,远超算力增长速度。随着百度、360、华为等公司纷纷入局AI领域,国内厂商对算力的需求将迎来井喷。
综合OpenAI的研究经验,以及中国企业大模型的研发进度等因素,广发证券分析师刘雪峰等对国内AI大模型的训练和推理阶段算力需求,以及相应的成本进行了测算。
算力需求
首先,分析师根据GPT-3的数据测算了国内AI大模型训练和推理所需的AI服务器需求。
分析师认为:
根据商汤招股说明书的数据,GPT-3的大模型的所需要训练355个GPU-年。在当前各家公司推出AI大模型意愿较强的背景下,我们认为科技公司用于训练AI大模型的时间为1个月,因此其需要训练AI大模型的AI加速卡的数量为4260个。
我们认为,AI大模型有望成为各科技厂商竞争的关键领域,因此假设国内有意愿开发AI大模型的公司有10个,则由于AI大模型训练而新增的AI加速卡需求空间为4.3万个,国内由于AI大模型训练而新增的AI服务器的需求空间约为5325台(本文均假设单台AI服务器搭载8个AI加速卡)。
根据英伟达官网的数据,A100针对于BERT类的AI大模型可实现每秒推理1757次,因此可假设单片A100用于AI大模型每秒生成1757个单词,与单次客户需要生成的内容数量相当。
截止2023年3月27日,百度文心一言已收到12万家企业申请测试。我们预计,国产类ChatGPT的访客量规模较为庞大。
2023年3月29日,在2023数字安全与发展高峰论坛上,三六零公司现场演示了360大语言模型在360浏览器上的应用。分析师认为,内容生成类应用已成为各科技厂商开发AI大模型积极探索的方向,因此假设国内未来开发并应用类ChatGPTAI大模型的数量为10个。针对不同情境分析师进行了以下假设:
- 国产类ChatGPT的定位是仅给注册企业内部使用,则假设每天访问量为5000万人次,每人与ChatGPT对话5次,由此测算下来,由于AI大模型推理而新增的AI加速卡需求空间为4.3万个,新增的AI服务器需求空间为5425台。
- 国产类ChatGPT的定位是面向个人用户开放使用,则分别假设每天访问量为1亿或3亿人次,每人与ChatGPT对话5次,由此测算下来,由于AI大模型推理而新增的AI加速卡需求空间为8.7万或26.0万个,新增的AI服务器需求空间为1.1万或3.3万台。
因此,乐观假设下,国内AI大模型在训练与推理阶段或将产生相当于1.1万台或3.8万台高端AI服务器的算力需求。
成本测算
此外,分析师强调,多模态大模型是AI大模型的发展方向,应用前景广阔。今年以来,全球多家科技厂商陆续发布多模态大模型,如谷歌的PaLM-E大模型、OpenAI的GPT-4大模型以及百度的文心一言大模型。
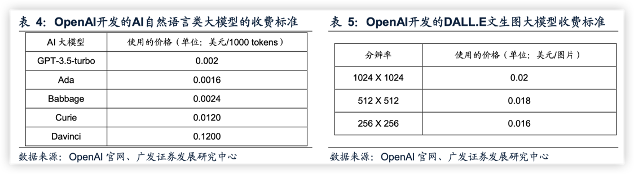
相较于自然语言类模型,多模态模型在训练阶段融合了文字、图像、三维物体等多维度数据的训练,可交互的信息类型较多,通用性得到了大大增强。分析师参考OpenAI和百度的AI大模型的收费标准后,对各行业用户用于生成类任务的成本进行了以下假设:
- 生成文本的价格为0.003美元/1000tokens,相当于0.02元人民币/1000tokens(参考汇率:1美元=6.88元人民币)。Tokens是包括了单词、标点符号在内的字符,因此可以简单理解为单个文字。
- 生成图片的价格为0.02美元/张,相当于0.15元人民币/张。
多模态大模型API开放后,各行业用户用于内容生成类任务的使用成本敏感性分析:基于以上假设条件,我们对各行业用户调用多模态大模型的API用于内容生成任务的成本做关于文本生成量和图片生成量的敏感性分析。
我们预计中短期内,基于多模态大模型的单日调用量的范围预计在5000万人次到3亿人次之间。假设每天每人生成文本内容5次,每次生成文本内容为1000个tokens,则生成文本数量的范围预计在2.5千亿到15千亿个tokens之间。
假设每天每人生成图片5张,则生成图片的数量范围预计在2.5亿张-15亿张。由此,我们测算出,各行业用户调用多模态大模型的API用于内容生成任务的成本如下表所示。
分析师也强调,AI大模型技术仍处于发展早期,技术迭代的节奏和方向处于快速变化中,在AI算力需求测算中,也需考虑由于算法优化导致AI模型消耗算力成本降低的因素。考虑到软件优化带来的降本提效因素,实际硬件需求和算力成本可能较此前测算的数值较低一些。
综上,分析师指出,在暂不考虑软件层面算法优化带来的模型消耗算力成本下降的前提下,国内大模型在训练与推理阶段或将产生相当于1.1万台或3.8万台(乐观假设下)高端AI服务器的算力需求,以单片A100售价10万元人民币、AI加速卡价值量占服务器整机约70%计算,则对应约126亿元(人民币)或434亿元增量AI服务器市场规模。
分析师预计,前述AI服务器的增量需求或将在1-3年的维度内逐步落地。
本文主要观点来自广发证券分析师刘雪峰(执业:S0260514030002)等发布的报告《国内AI大模型的训练和推理阶段算力需求测算》,有删节
-
上一篇

训练AI模型如何选择合适的GPU
-
下一篇
随着OpenAI推出的ChatGPT惊艳世界开始,原本认为只是存在于各个厂商宣传口号中的AI技术,突然之间每个人都能够轻松使用,并得到不错的体验。人工智能时代的大门仿佛一下打开了。
AI什么时候能够彻底改变人类的生活,能够改变到什么程度,目前尚无定论,但AI已经成为了科技界最热门的领域,它带给了人类无限的期待和想象,成为各国科技竞争的最重要、最耀眼的一条赛道。
当前各大科技厂商已经疯狂布局人工智能,加速训练各种大模型,并快速的把大模型能力集成到各种产品和应用之中,以期在这场新的范式转换和技术浪潮中占得先机。
大明星ChatGPT是如何炼成的
人工智能(AI)是一个广泛的术语,指的是任何能够进行智能行为的技术。过去比较常用来进行一些重复、简单的辅助工作,比如流水车间的组装加工、车辆自动驾驶等,而当前火爆的ChatGPT是一种名为生成式AI(Generative AI)的人工智能系统,它通过在大型数据集上进行训练,并使用深度学习算法生成与数据内容相似的新内容,从而实现类似人类创造力的功能。于是人们突然发现AI已经发展到可以进行文字、图片、音乐的创作工作!这让以往认为最难被AI取代创意设计行业从业者们都开始感受到了焦虑。
凡事都不是一蹴而就的,如同一个人一样,生成式AI想要完成赋予它的创作工作,是需要有一个学习的过程的。这个过程就是训练,以ChatGPT为例,他的训练过程大致分为数据预处理、模型训练和模型评估三个阶段。简单来说就是从海量的真实数据中,筛选出合适的足够多的数据,处理成模型算法能够理解的数据集格式之后,用数据集对模型算法进行训练,再对训练出来的模型进行评估验证、微调,再训练,反复锤炼,完成生成式AI模型的训练过程。完成训练之后的AI模型,再根据用户的输入,生成新的内容,这个过程,就是AI的推理。也就是我们平时应用AI来生成文字、图片、音乐等创作的过程了。
增加GPU,AI大模型训练加速就OK了吗
从AI模型的训练过程中不难看出,AI大模型想要能够应用,必须要有反复训练调整的一个过程,谁能更快更好的完成AI大模型的训练并投入到产品应用之中,谁的AI系统就能够在竞争中占据有利地位。
AI大模型训练,下一个加速点在哪?