AI模型部署典型策略
【编者按:模型部署是AI开发生产流程中的重要步骤。对于许多组织而言,选择最佳的模型部署策略以扩展到生产级系统,都是一项复杂且具有挑战的工作。
今天IDP将和大家一同,跟随Yashawi Nayak,全面了解模型部署策略。
这篇文章是为那些想了解ML模型如何在生产中部署以及在部署这些模型时可以使用什么策略的人准备的。本文将说明部署ML模型的基本方法,可以采取的不同部署策略,以及这些策略一般在哪里实施。每个数据科学团队都会有一套不同的要求,所以要慎重考虑。
以下是译文,Enjoy!】
作者| Yashawi Nayak
编译| 岳扬
1. 了解机器学习模型的部署
与部署软件或应用程序相比,模型部署是不一样的。一个简单的ML模型生命周期会有如下这些阶段,如范围界定、数据收集、数据工程、模型训练、模型验证、部署和监控。
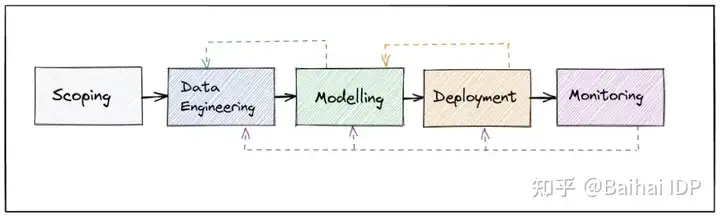
当我们在部署ML模型时,需要考虑一些因素,比如:
- 模型的大小和打包——模型的大小对我们如何打包有巨大的影响。较小的模型通常可以被放置在FastAPI服务器中,并在Docker容器中进行封装。然而,较大的模型可能需要在部署期间加载——从远程存储中拉取,并通过模型服务器(如TFServing或TorchServer)运行。
- 模型的再训练和版本维护——对模型的再训练频率影响着部署策略。你是否经常需要比较你的模型性能?你在生产环境中需要多长时间才能更新你的模型?你会在生产环境中维护你的模型的不同版本吗?
- 流量和请求路由——根据流量和模型的类型决定实时推理或批量模型部署。你想将多少流量分流到每个版本的模型?有多少用户会有机会访问某一个模型版本?
- 数据和概念漂移——随着时间的推移,现实世界的数据在不断变化,这可能不会被反映在模型中。比如说,购买力与工资的关系如何,可能每年或每月都在变化。或者在新冠疫情期间,消费者的购买模式如何变化。但模型大多依赖于历史数据,这影响到我们的部署架构设计:我们应该重新训练和重新部署吗?我们是否应该暂时只对模型进行重新训练和阶段性的调整?这个因素在数据科学团队的长期部署战略中发挥较大的作用。
对于这些因素,我们有模型部署的六个常见策略。这些策略主要是从DevOps和UX方法论中借用的,在ML场景中也同样适用。
通常,在技术层面上,生产环境中的模型部署涉及到API端点网关、负载平衡器、虚拟机集群、服务层、某种形式的持久性数据存储和模型本身。
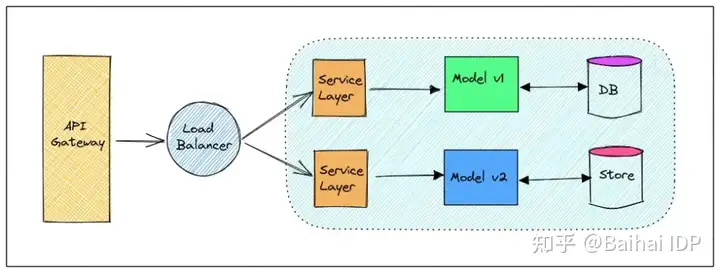
部署策略通常在负载均衡器和服务层面进行配置,主要是配置路由和入口规则。
以一个动物识别和分类系统为例。从一个简单的猫狗分类器开始,这将是模型的首个版本。假设我们已经训练了一个模型的副本来识别考拉,所以第二个版本是一个猫狗考拉分类器。我们将如何部署模型的最新版本?
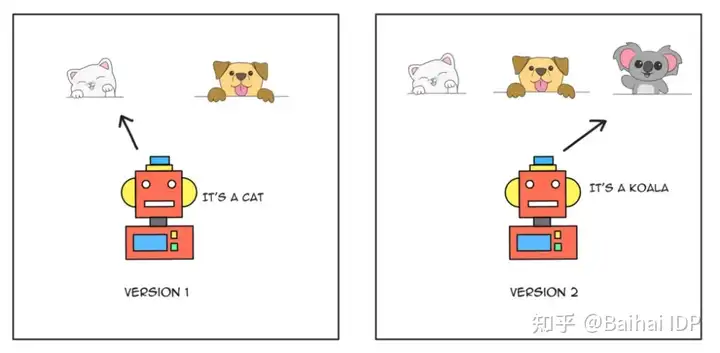
2.模型部署策略
2.1 Big Bang:重新部署
WHAT:这种形式的部署是一种从头开始的部署方式。你必须移除现有的部署,才能部署新的。
WHERE:在开发环境中一般是可以接受的。可以用不同的配置重新创建部署,次数不限。通常情况下,部署管道会移除现有的资源,并在其位置上创建新的版本。
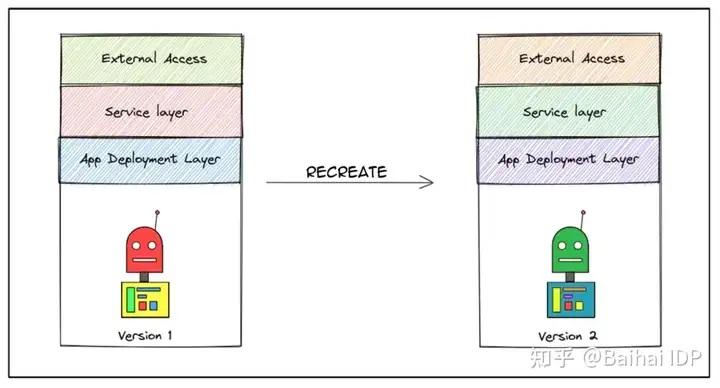
这种部署方式会造成到一定时间的中断。现在这样的机器学习开发的速度是不可接受的。
在我们的例子中,我们用版本2替换版本1,这过程中就会替换掉所有相关的基础设施和库配置。
2.2 滚动更新策略
WHAT:滚动更新策略是逐一更新模型/应用程序的所有实例。假设你目前有4个正在运行应用程序的pod,然后使用滚动更新策略部署新版本的模型,这样一个接一个的pod会被替换成新的。这种方法造成服务中断的时间为零。
WHERE:当你想用一个新的版本快速更新你的整个模型集时会很有用。使用这种策略也允许你在需要时回滚到旧版本。该策略主要用于测试环境,当团队需要测试新版本的模型时。
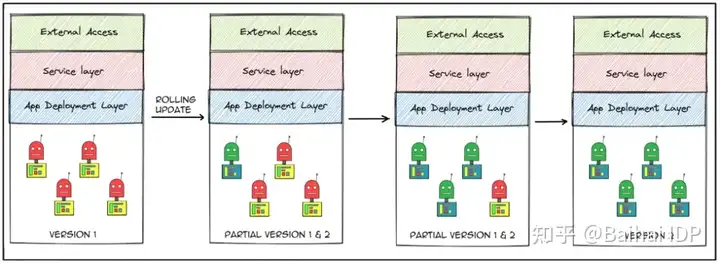
一般来说,这不会是生产系统中的唯一实现方法,除非你仅在整个系统中部署一个特定版本的模型。在上述例子中,我们只替换了模型应用pod,保持其他基础设施原样不动。
2.3 Blue/Green 部署
WHAT:这种部署形式本质上是一种服务器交换的部署形式。在这种部署形式中,有两个相同的系统可用,用户的请求被转到其中一个系统,而更新则在另一个系统上完成。一旦更新通过测试和验证,用户的请求就会被路由到较新的系统,其实本质上是把旧的模型换成新的。
WHERE:主要是在普通应用程序或网络应用场景中使用该种部署方式,也可以用于模型部署,在批处理和实时推理部署中都可以使用。由于该模式是将负载均衡指向一组不同的机器,因此造成服务中断的时间基本上为零。
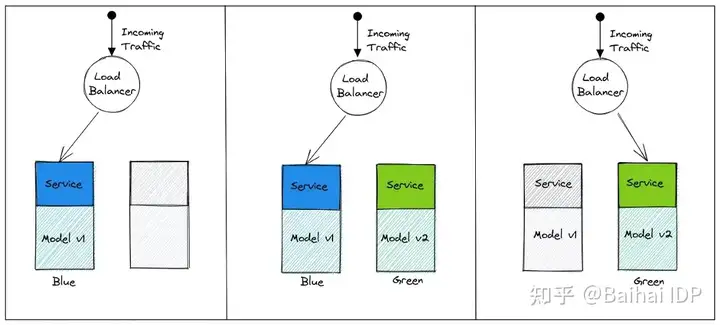
如你所见,我们用新的模型版本创建一个新的相同系统,然后只需将流量切换到新的系统。
然而,我们需要把维护两个相同的基础设施系统的成本考虑进去。是否选择这种方法取决于基础设施的规模和承受能力。
2.4 金丝雀(Canary)部署
WHAT:在Canary部署中,我们将更新后的模型部署到我们现有的系统中,并给部分用户推送新版本模型。这意味着我们的一小部分用户将能够访问最新的模型,其余的用户仍将使用旧的版本。
这种部署方式主要是用来测试新版本的运行情况。通常,一小部分用户(大约5%-30%)会接触到最新版本,因为这有助于ML工程师和开发人员了解哪些功能可能需要推出,哪些需要重构。
WHERE:当团队需要了解新模型的性能时,通常会在模拟环境(staging)和生产环境(production)中进行Canary部署。这可以通过两种方式进行:
- 金丝雀滚动部署
- 金丝雀并行部署
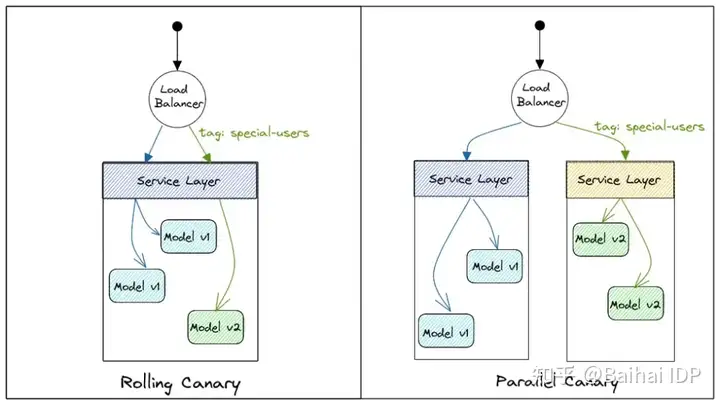
滚动部署(Rolling Deployment)将最新模型放到同一集群内的少量实例上,并将一组用户请求发送到这些pod。
并行部署(Parallel Deployment)在现有实例旁边创建了一组较小的新实例,并将一定比例的用户请求发送到这些pod上。
用户的请求通常通过头信息进行标记,然后通过负载均衡器的配置,将其发送到相应的目的地。这意味着有一组用户被选择来查看最新的模型,而且同一组用户每次都会看到最新模型。用户请求不会被随机地发送到新的pod。这说明Canary部署具有会话亲和性。
在上文的猫狗考拉分类器例子中,假设选定10%的用户可以向模型提交图像,这10%的用户提交的图像将用考拉选项进行分类,其余用户只能使用猫狗分类器。
2.5 A/B测试
WHAT:这种方法在用户体验研究中使用最多,可以用来评估用户喜欢什么。在机器学习场景中,我们可以使用这种部署方式来了解用户喜欢什么,哪种模式可能对他们更有效。
WHERE:全球范围内的推荐系统部署中大多采用此种部署模式。根据人口统计学,例如一个在线购物网站采用了两种不同类型的推荐引擎,一个服务于一般的用户,一个服务于特定的地理区域——有更多的母语支持。工程师们可以在一段时间后确定哪种引擎能给用户带来更顺畅的体验。

回到我们举的那个例子中,假设我们在全球范围内部署了猫狗分类器,但我们在澳大利亚-太平洋岛屿地区部署了版本1和版本2,用户请求有可能被随机发送到版本2。然后重新训练版本2以识别更多的当地动物品种并部署它,你认为澳大利亚的人们会喜欢哪个版本?
Note:那么Canary和A/B测试之间有什么区别?主要的区别是:
- Canary是基于会话亲和性(来自客户端的请求总是路由到同一个服务器进行处理)的,大多数情况下,同一组用户将看到最新的模型,而在A/B测试中,用户被随机发送到不同的版本。
- Canary是专门用来测试应用程序或模型是否按预期工作的,而A/B更多的是为了了解用户体验。
- Canary的用户比例从未超过50%,很小比例的用户请求(理想情况下低于35%)被发送到较新的测试版本。
2.6 影子部署(Shadow)
WHAT:影子部署用于生产环境中,用生产数据测试最新版本的模型。生成用户请求的副本并发送给新模型,但现有的系统也会同时给出响应。
WHERE:假如有一个高流量的生产系统,为了验证新模型如何处理生产数据和流量负载,可以用影子模式部署新模型。每次向模型发送请求时,都会向更新的版本发送一个请求副本。只由现有的模型发送响应,而新模型不发送响应。
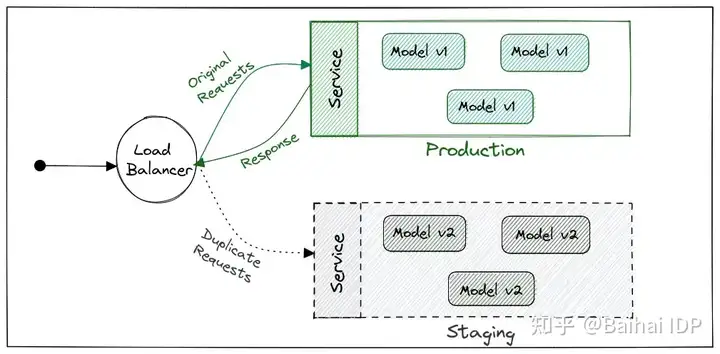
影子部署主要是用来了解生产负荷、流量和模型性能,其主要用于高容量预测服务。系统架构和设计的复杂性随着使用这种部署方式而增加。我们必须有包括服务网格、请求路由和基于用例的复杂数据库设计。
在本文举的例子中,我们可能会将版本2使用影子部署,以了解版本2如何处理生产负载,也了解从哪里得到更多的考拉分类请求 或任何特定类型的模型请求模式。
现在我们对如何在各种情况下部署模型有了基本了解。根据不同的要求,数据科学团队可能需要使用这些方法的组合,这需要根据具体的业务场景来决定。