Meta发布生成式AI语音模型Voicebox,精通六种语言,支持多种语音功能最前线
原标题:Meta发布生成式AI语音模型Voicebox,精通六种语言,支持多种语音功能 | 最前线
作者 | 周愚
编辑 | 邓咏仪
美国时间6月16日,Meta正式发布语音生成模型Voicebox。据官网介绍,通过非自回归流匹配(Flow Matching)技术,研究人员无需手动标记不同数据,即可利用长达5万小时的语言和有声书文本训练Voicebox。Voicebox生成语音的速度,可到达目前最先进的自回归模型的约20倍。
不同于过去的语音AI模型一般只有单一用途,Voicebox基于同一通用模型,即可实现基于文本的语音生成、语音编辑和降噪、跨语言转换、多风格语言采样等功能。
在英语文本到文字的转换过程中,Voicebox的平均单词错误率与音频相似度(相较于真实语音)分别为1.9%和0.681,而目前最先进的英语模型Vall-E,则分别为5.9%和0.580。
此外,Voicebox还支持合成包括英语、法语、西班牙语、德语、波兰语和葡萄牙语等六种语言的语音。在跨语言转换的表现上,Voicebox同样优于该领域领先的YourTTS,平均单词错误率从10.9%降低到了5.2%,音频相似度则从0.335提高到了0.481。
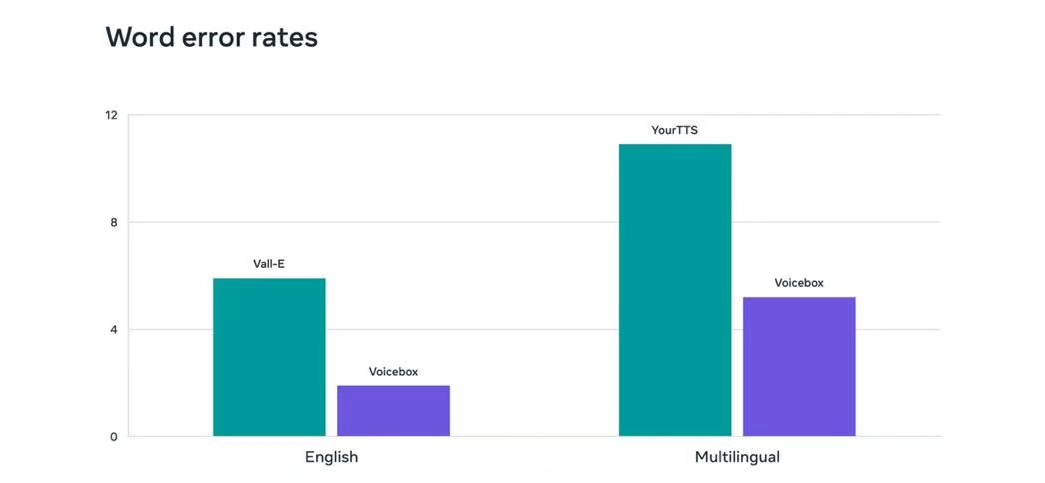
Voicebox与其他语音生成模型单词错误率对比。来源:Meta
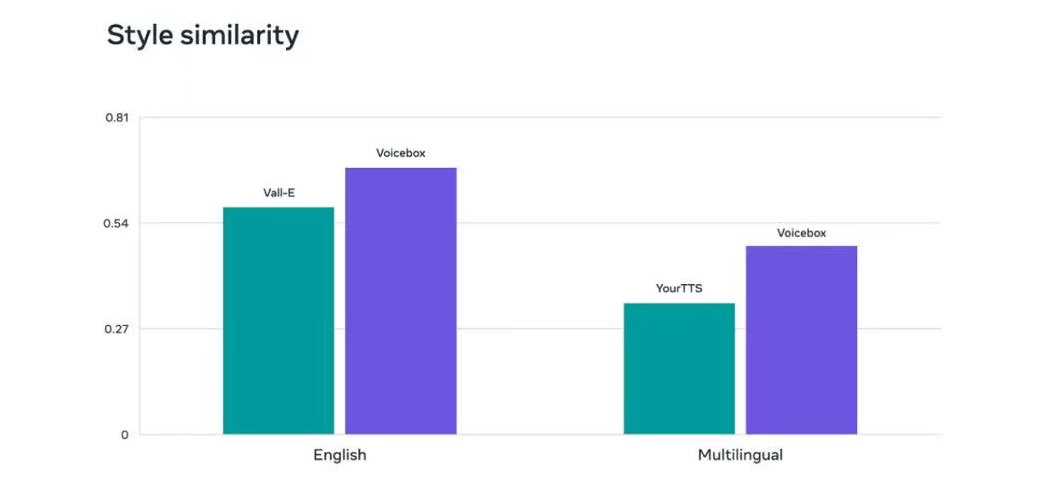
Voicebox与其他语音生成模型音频相似度对比。来源:Meta
在训练过程中,Voicebox会得到一个音频样本和相应的文本,然后部分音频将被屏蔽,该模型需要根据前后音频和给定的文本,生成被屏蔽的音频片段。
经过这种训练的模型可以直接或在少量微调后,适用于许多任务。以降噪和语音错误修改为例,Voicebox在实现这两项看似不同的功能时,均是首先屏蔽出现噪音或错误的部分,然后基于前后已有的音频和原文本或修改后的文本,重新生成该部分语音。
这也是Meta研发Voicebox的主要目标。在一篇披露Voicebox技术细节的论文中,Meta研究人员写道:研究目标是建立一个单一模型,通过上下文学习来执行多种基于文本的语音生成任务。
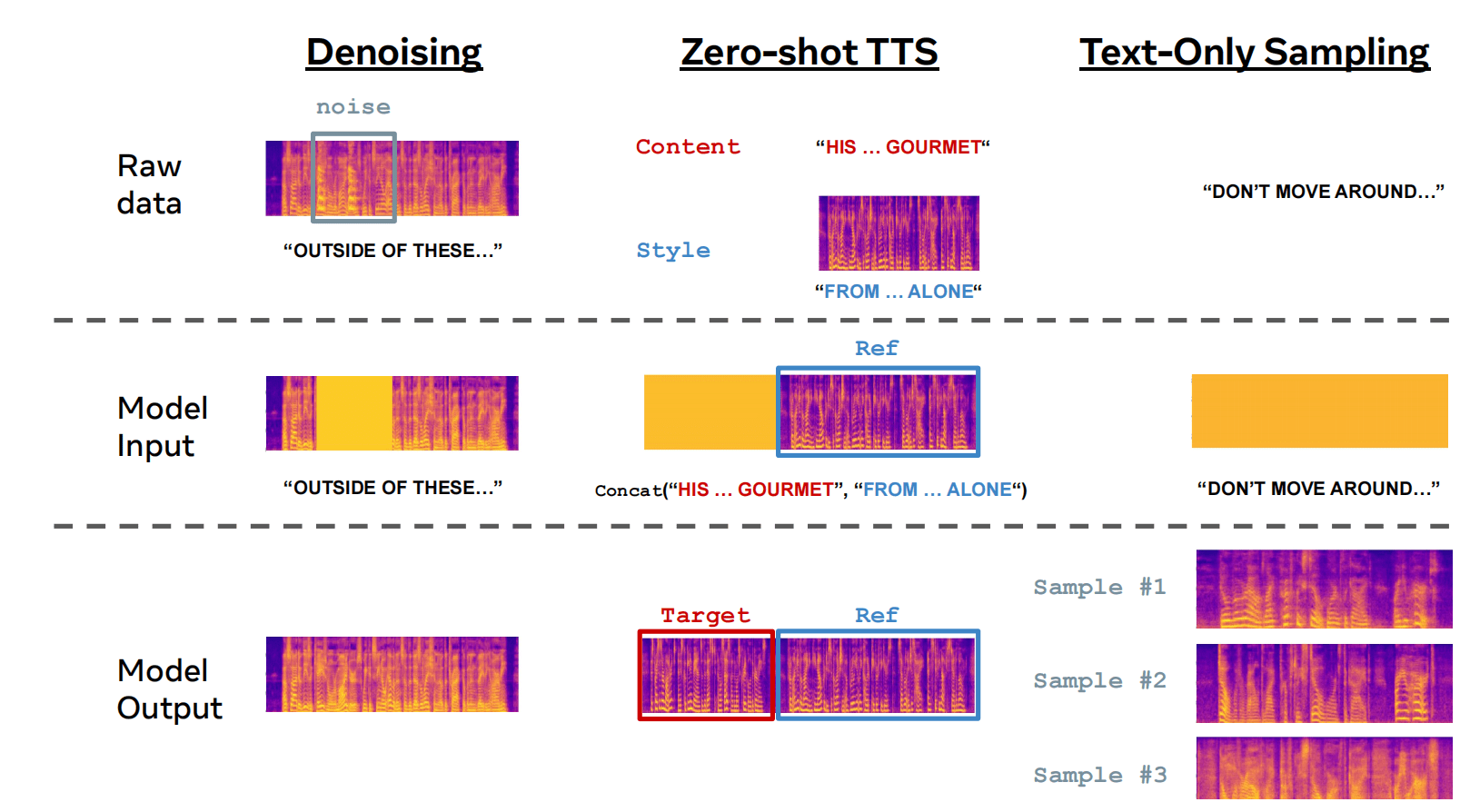
Voicebox通过前后音频学习生成语音。来源:Meta
Voicebox并非是为特定应用程序训练的生成模型,因此还可以执行许多未经过训练的其他任务。
输入长度仅为两秒的音频样本,Voicebox就可以获得相应的音频样式。而后,使用者只需输入文本就可以生成语音。Meta表示,这项功能可为语言功能障碍人士提供语音,或为NPC和虚拟助手定制声音。
同时,Voicebox跨语言转换的功能也可以帮助不同语言的人们进行顺畅的交流。基于六种语言的语音样本和给出的文本,使用者在Voicebox的帮助下便可以轻松生成目标语言的语音。
Voicebox还可以将其生成的语音用于模型训练。Meta的研究结果表明,与真实语音训练出的模型相比,使用Voicebox生成的语音训练出的语音识别模型表现几乎一样好。

Voicebox与其他主流语音生成模型功能对比。来源:Meta
尽管Meta研究团队已经发布了披露技术细节的相关论文,但Meta并没有公开Voicebox的模型或代码,认为需要在开放和责任之间找到适当的平衡。

