AI绘画Stable-diffusion扩展最新全面使用指南
前言
文章很长,合理使用目录功能
自从4月的时候我就在玩AI生成,一晃才半年多,技术的飞跃已经是魔法级的了。
网上已经有不少教程,但是在收到的来信中还是很多提到outpainting 和dreambooth,因为网上的教程有很多都缺一些最新内容或者资源过旧,本文将尽量给一个最新的指南。另外本文后面指的小白均是有一定初级动手能力的同学,纯小白还是推荐使用云服务。
Stable diffusion是一个扩散模型,通过不停去除噪音来获得结果的。在AI绘画早期,扩散是发生在像素空间pixel space的,不仅效果不好而且单张图大约需要10-15分钟,后来英国初创公司StabilityAI改进了模型,把核心计算从像素空间改到了潜空间(latent space),稳定性和画质得到了极大提升,并且速度翻了几乎100倍,故名stable diffusion,从此AI绘画进入火热阶段。由于Stable diffusion是一个开源的模型,基本上后面的所有AI绘图的初创公司都是基于的这个模型,所以结果都非常相似。
要使用这项前沿技术,最简单的办法是使用云服务,对于国内同学来说,全中文提词的话使用Tiamat或者盗梦师。不过他们的质量目前都还不太好,特别是盗梦师基本上处于跟没有细调的原始开源版处于同一水平,跟国外Midjourney的品质相比差距较大;而Tiamat在艺术风格上有所改进,但是平均生成速度是50秒到3分钟左右,比较缓慢。
虽然云服务很方便,但Stable Diffusion之所以吸引这么多人乐此不疲的研究是因为它的用法远远不止点几个按钮这么基础,因此要最大化这项技术的效能,最佳办法是本地安装。
主要是四大原因:
首先,本地生成不存在隐私问题,你可以使用任意源图片,也不必担忧你辛苦创作的提词被泄露。
第二,本地生成不存在审查问题,甚至于有些同学特别喜欢生成NSFW的图片,那么绝对只能本地生成;
第三,速度快还免费,只要你有一台强大的pc,本地生成的速度是最快的,不需要排队,不需要避免高峰,通常一台RTX3090的电脑单图3-5秒,4090的电脑2秒左右,很快你就可以制造出一个巨大的图库,并且不要一张一张从网上下载。
第四,本地生成的选项和可操作性要大得多,不再局限于网络上几个简单的题词框和按钮,对风格的控制度高出很多倍,而且有很多好用的扩展功能,例如特别有趣的inpainting和outpainting,而且你可以自由切换底层模型,也可以自己微调模型(Dreambooth),当然代价就是更高的学习成本。如果你打算认真对待这个新生事物,那么绝对应该是用本地版的stable diffusion。
用户界面上stable diffusion有很多种流行的项目,这里推荐使用国外的AUTOMATIC111 的Stable-diffusion-webui,虽然英文会是一个难点,但是强烈推荐使用这个项目。
安装Stable Diffusion Webui
第一步是安装,安装这个问题其实很简单,但是对于新手却很难。对硬件最低要求是需要一个8GB显存以上的Nvidia 1000系显卡,最好是RTX系列显卡,会快不少。AMD和Intel显卡不可以。达不到的同学可以白嫖Google Colab的计算资源(显存16GB+)。
这里面还有一个最主要问题就是科学上网,如果不会的话大概率是进行不下去的(请折回使用云服务),因为要下载的东西比较多,但我们又都知道因为某种特殊原因我国的python pkg,github和huggingface已经处于半下岗状态。
小白步骤如下:
Windows
1. 安装Python 3.10.7,注意安装时要勾上把Python添加到路径 (下载 https://www.python.org/ftp/python/3.10.7/python-3.10.7-amd64.exe )
2. 安装git (下载 https://github.com/git-for-windows/git/releases/download/v2.38.1.windows.1/Git-2.38.1-64-bit.exe )
3. 在合适位置创建一个文件夹xxx,然后打开命令行窗口,执行 cd /d [xxx的路径]
4. 继续执行 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
5. 运行 webui-user.batLinux
1. 执行 sudo apt install wget git python3 python3-venv
2. 执行 bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)
3. 执行webui-user.shMac OS, 不推荐,会出现Cuda错误
对于老手而言,推荐使用Anaconda,自己建立需要的venv,选择安装torch+cuda11.6,跳过项目里的自动torch安装。都是老鸟了,详细过程就不说了。
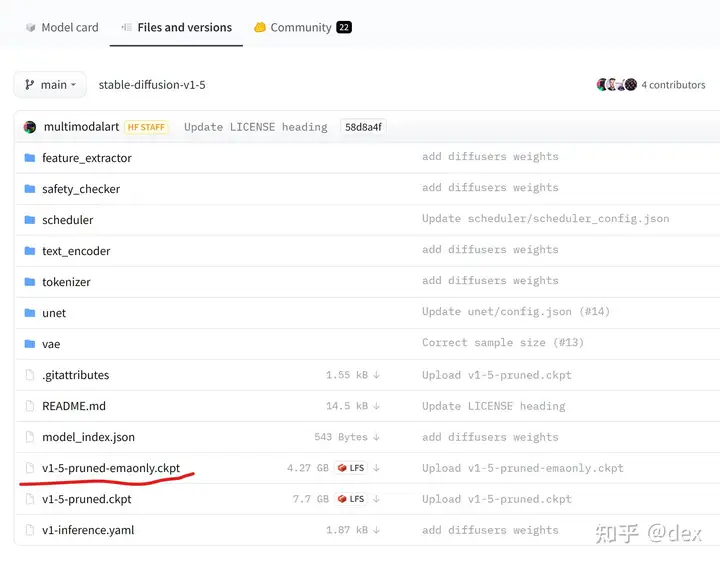
安装好了之后需要下载stable-diffusion 1.5的模型,https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
需要注册一个账号,点击同意开源协议,然后下载如图的文件。
多提一句如果不是从github下载的项目,我推荐一定要检查是否包含git文件夹,因为这项目进化得非常快,几天时间就会加入新功能,新优化等等
启动后会出现一个命令窗口,不能关闭,等出现如图字样时才表示启动完成(启动完成也不能关闭)。

之后就可以在浏览器中输入http://localhost:7860打开stable diffusion的界面,这个框架是用Gradio写的,所以如果喜欢深色,在地址后面添加 ?__theme=dark 即可
基本使用就不多讲了,这里重点说outpainting和dreambooth
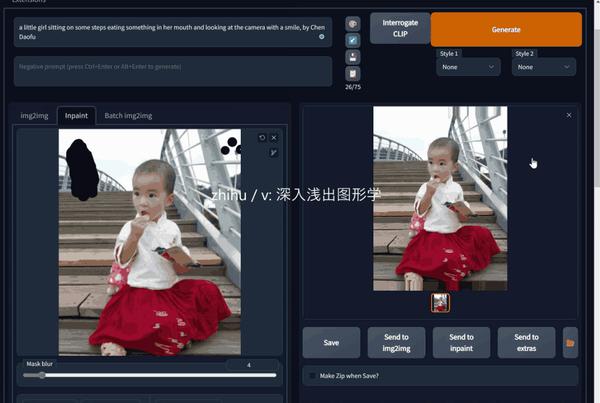
Inpainting
Inpainting相信大家都很熟悉了,就是相当于Photoshop的自动修复(Spot Healing)功能,只不过精度要高得多。列在这里是让大家有一个明显对比。
Outpainting
什么是outpainting
这个创意最早是来自OpenAI Dall-E 的demo,Outpainting 是一种扩展原图的方式,demo如下:
相对于DALL-E的缓慢的速度和云端闭源收费,Stable-diffusion-webui依靠第三方扩展可以无缝支持Outpainting。常用的扩展有infinity 和paintHua。这里介绍这个叫做PaintHua的国产扩展,目前是最好用的outpainting工具,完全免安装,支持历史回退,masking和多选择,只需要在原stable-diffusion-webui上加上几个参数。
配置PaintHua
1. 在Stable-diffusion-webui根目录下找到webui-user.bat,用记事本打开
2. 找到 set COMMANDLINE_ARGS= 这一行
3. 在后面添加 --api --cors-allow-origins=https://www.painthua.com
4. [可选] 到 https://huggingface.co/runwayml/stable-diffusion-inpainting 这里下载填充用的专用模型并放入models\Stable-diffusion,选择这个模型效果比sd-1.5好很多
5. 启动Stable-diffusion-webui,等待启动完成
6. [可选] 如果完成了步骤4,那么打开浏览器localhost:7860 ,把模型切换为专用模型。切记如果跳过这一步那么第四步就是白做
7. 在浏览器中打开网址 www.painthua.com 即可
注意网上有些教程让改webui.bat里面的 app.user_middleware 这行,这个方法已经淘汰了,因为很不安全,基本是给黑客开大门。
使用PaintHua
启动painthua后双击任意空白处可以出现一个初始填充,如果没有,或者显示一大堆英文,那么你上面步骤操作有误。
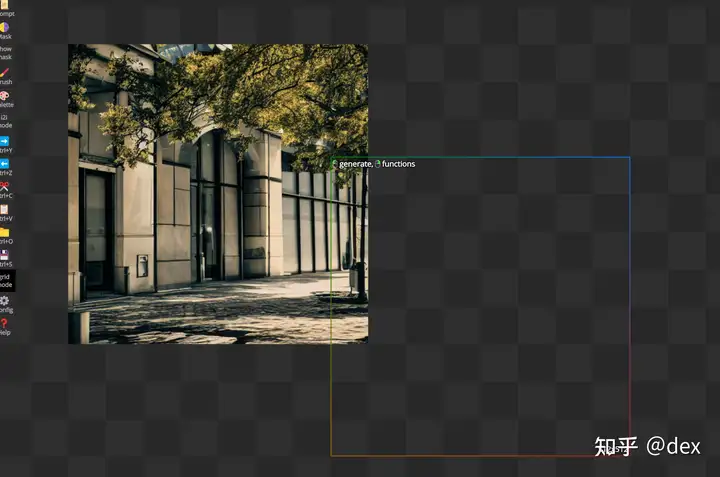
如图注意每次填充后需要点击Accept才算是写入到画板里,如果想要换一个样子点击Accept右边的More按钮,然后之前结果也不会消失,可以按右边的Prev, Next按钮进行切换,十分的好用。点击Cancel可以取消当前填充块。
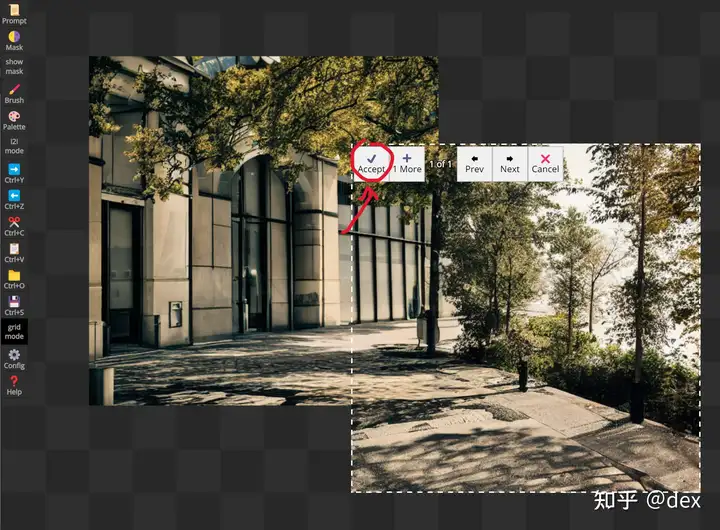
通过使用Mask功能PaintHua也能支持Inpainting,也就是替换原有图片上的区域(如下图),传统PS去除小规模杂物的工作已经可以被彻底替代了,现在小白也能做,甚至可能更好。

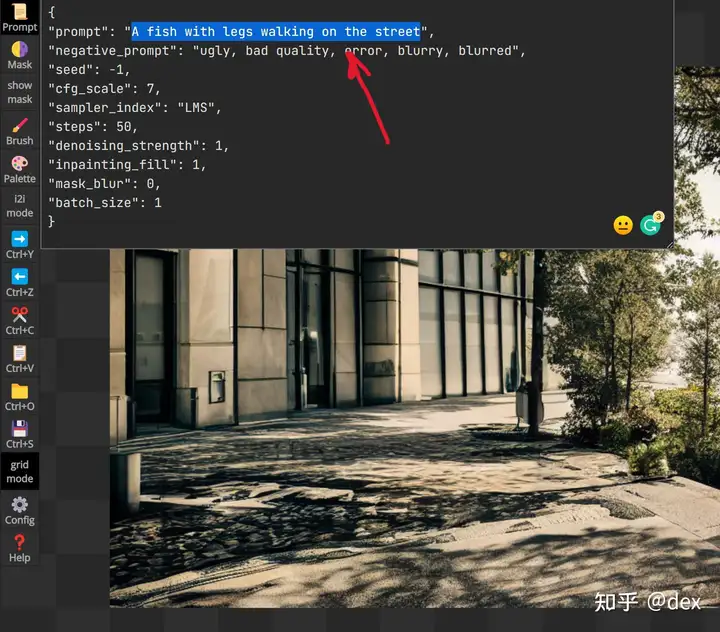
跟生成全图一样,要改变当前图片内容的话需要改变提词,单击左上角的Prompt按钮。记得你的Prompt要跟图片内容差不多才行,否则填充就会很不统一。一般来说要进行多次扩图,需要针对不同区域微调提词。
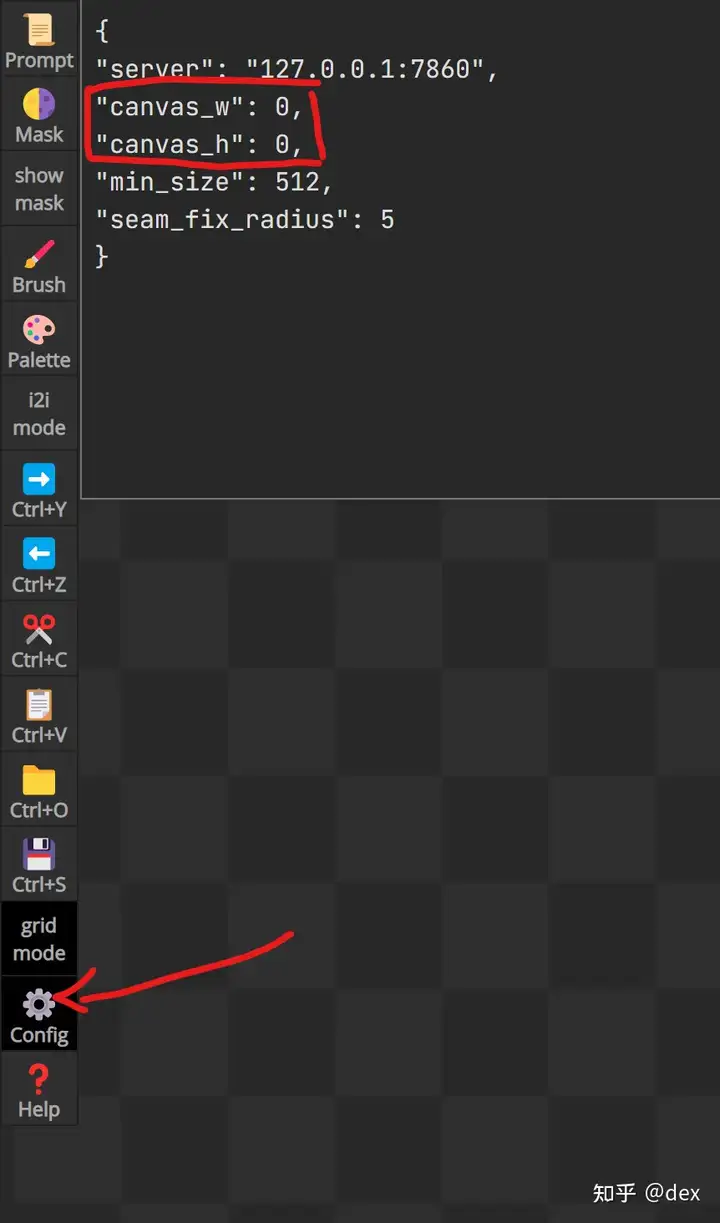
还有一个要注意的就是画布大小,PaintHua的默认画布大小是打开时的浏览器大小并且固定住,打开以后再调整浏览器窗口大小无效。如果想要最大的画布区域Config里面有一个Config/Canvas_w canvas_h的选项,但是实测不能超过4K x 4K,而且每次更改都必须要刷新页面,所以最好第一次就设置好4096x4096,之后打开会自动保存这个设置。如果是中途更改,那么刷新页面前记得保存(Ctrl+S)。
最后要擦除一块区域的话,点击右键拖拽就行
对上面说的这些功能结合使用,很容易得到不错的效果,比如下图在不借助任何其它工具情况下单用stable-diffusion只花了5分钟,整体草稿就形成了:

目前Adobe也在积极集成AI功能进photoshop,可以预见要不了多久,PS求人的需求将很大一部分被AI替代。
对于Painthua就介绍到这里,这个项目里面还有很多细节功能,比如任意填充大小,快捷键,克隆,移动工具等等,可以自己探索。
DreamBooth
这个功能显存要求12GB,可能很多同学硬件是满足不了的,就只能采用云计算的办法,
谷歌Colab云计算入口:Stable-Diffusion
使用方法跟下面一致,但是根据版本的不同,多半需要手动安装bitsandbytes库:
pip install bitsandbytes
或者采用纯命令行方式训练DreamBooth:DreamBooth.ipynb
下面只说本地的。
什么是DreamBooth
原始stable diffusion是无法进行稳定的对象输出的,每一次都相当于摇骰子或者叫抽卡,多次生成之间的主体没有关联性。而Dreambooth改善了这个问题,这货是来自google的一项图片个性化研究,在原图片生成网络上加入了Prior Preservation Loss,经过几张图片的简单训练就可以重新采样潜空间,输出指定的对象。这个个性化定制输出的效果,也让DreamBooth成为目前AI图像生成里面最火的功能之一。


原本Dreambooth是基于Google的Imagen和T5网络的,但是github上有人用stable diffusion和CLIPText重新实现了一遍,这也是我们现在使用到的stable diffusion 版DreamBooth的内核。
如前文所说,dreambooth是需要预先训练的,不是直接使用,整个训练过程如今有了UI,终于不需要再敲命令了!
安装DreamBooth扩展
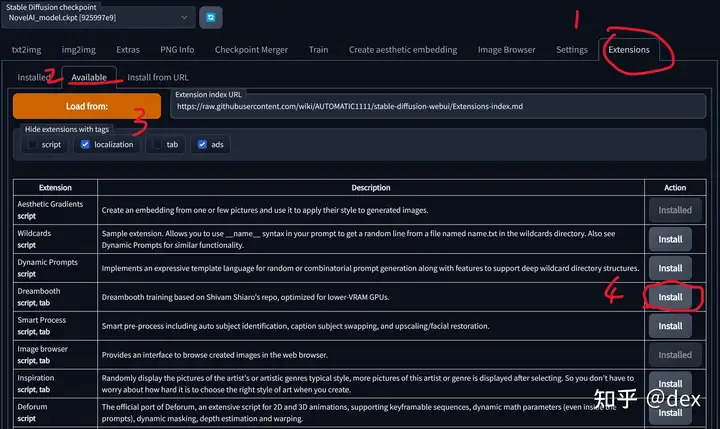
启动stable-diffusion-webui后找到最边上的Extension选项卡,然后选择Available子选项卡,然后点击Load from。这时会看到一串可用扩展的列表,点击DreamBooth那一行的Install按钮然后慢慢等待安装完成即可(安装log在命令窗口里)。
不过这个插件写得不太好,虽然能用但是有很多问题,所以对于老鸟而言,建议去掉requirements.txt对于torch, torchvision, nump, gradio, transformers等重要库的安装,使用stable-diffusion-webui的库
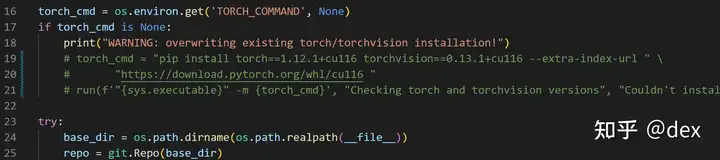
进一步针对老鸟,有些同学依然会遇到torch的覆盖性安装,这时最好注释掉install.py里面的两行代码,自己装torch最方便:
【BUG】如果遇到类似Bad File Error verifying pickled file from … 之类的错误,打开webui-user.bat,在set COMMANDLINE_ARGS=后面添加上 --disable-safe-unpickle (包含空格),然后重启stable-diffusion
Dreambooth的训练需要至少12GB显存,所以至少需要Nvidia RTX3060 12GB以上的显卡。
另外这个dreambooth只支持CUDA 11.6,为什么呢?是因为这里面用到了我之前在调试transformers时编译的Windows 版bitsandbytes库,没有这个库,显存需求得变成24GB,变成必须3090以上显卡才能运行。我在编译这个库的时候只是作为测试,所以只编译了CUDA 11.6版。但是现在一不小心变成了全网唯一的windows版int8 Adam库,必然对具体操作环境造成影响。这个是我编译的库的源链接,有需要测试的同学从这里下载:我的Windows dll链接:https://github/DeXtmL/bitsandbytes-win-prebuilt使用的话需要改一点代码,详见 READMEDll的安全问题想必大家多少听说过,不要相信任何其它来源的。暂时不打算编译11.8版本的
以上安装好后,stable-diffusion-webui界面上会多出一个 DreamBooth选项卡,没有看到这个选项卡则说明安装失败,要去查一下log。
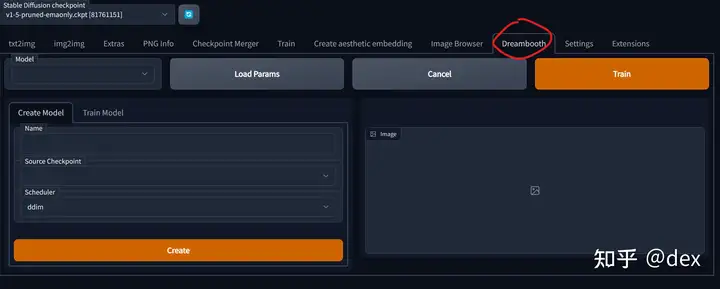
使用DreamBooth
要使用DreamBooth需要首先创建一个空的model,每次训练对应一个model,每个model可以包含一个或多个对象,按照下图填写:
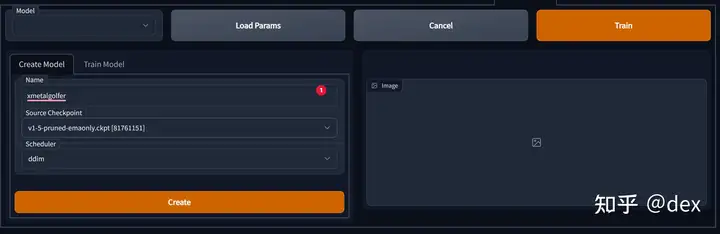
其中名字可以随便取,但一定不能和现有英文词汇重合,最好随便创造一个新词。Checkpoint是指在哪一个stable-diffusion权重上训练,推荐sd-1.5版,最后Scheduler一定要选ddim,其它scheduler的效果比较差。
如果是第一次创建,点击Create后需要多等待一段时间(下载一些模型文件),平均2-3分钟左右,如果时间过长则需要检查一下是否出错。
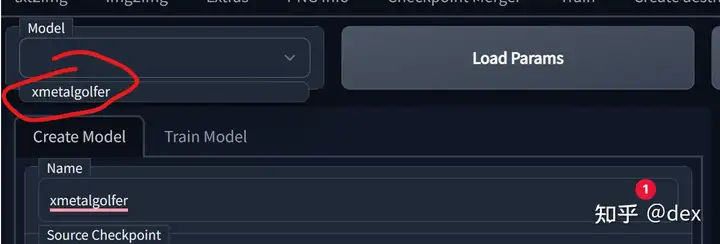
创建好之后上方的Models下拉框里如果出现刚刚创建的模型表示创建成功,如图
然后我们切换到Train Model选项卡,可以看到这里面的选项非常多,但实际需要改动的很少,如图(长图):
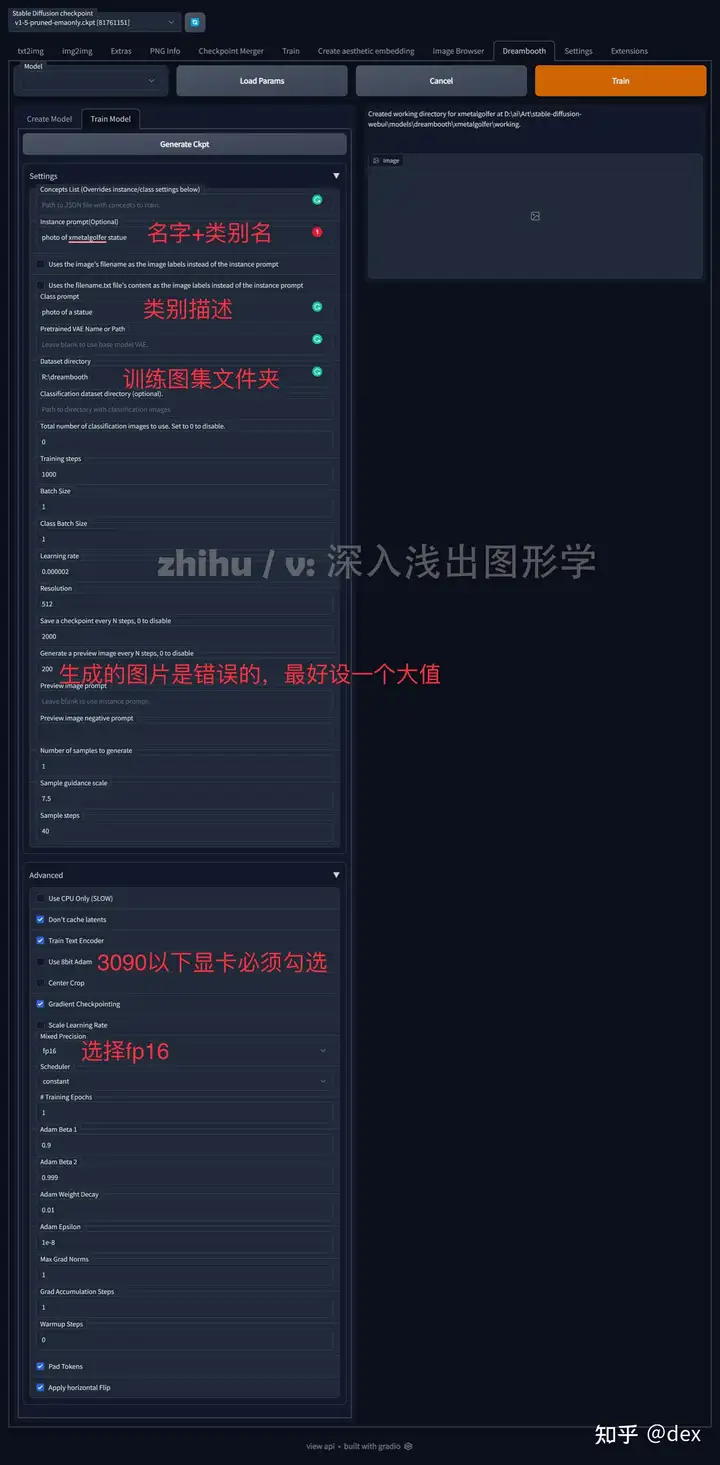
其中Instance prompt是实例词,一般采用photo of xxx的格式,我的物体取名叫xmetalgolfer,它是一个小雕塑statue, 因此这里写 photo of xmetalgolfer statue (可以不写介词a)
Class prompt是类别描述词,直接写photo of statue
Save a checkpoint every N steps, 这个最好写成0,相当于禁用,一般用于调试
Generate preview image every N steps, 这个最好写成5000,相当于禁用,因为输出结果经常是错误的
下面Advanced栏里面,只要不是3090以上显卡的同学都要勾上8bit adam,让系统调用之前说到的bitsandbytes库,降低显存消耗
Mixed Precision精度要选择为fp16,注意不要错选bf16,游戏显卡不支持这个格式
其余值保留默认。
都设置妥当后,点击那个巨大橘黄色按钮Train开始训练
【BUG】注意这个插件的代码不支持大写的扩展名,例如.JPEG无法被正确识别,需要把所有图片扩展名改成小写!追求完美的同学可以改代码( train_dreambooth.py/is_image ),或者等PR
在训练时,如果没有启用8bit Adam,那么内存消耗为16GB,加上stable-diffusion本省消耗的3-5GB,一共20GB左右显存,巅峰时消耗23.6GB,训练时间为8分钟
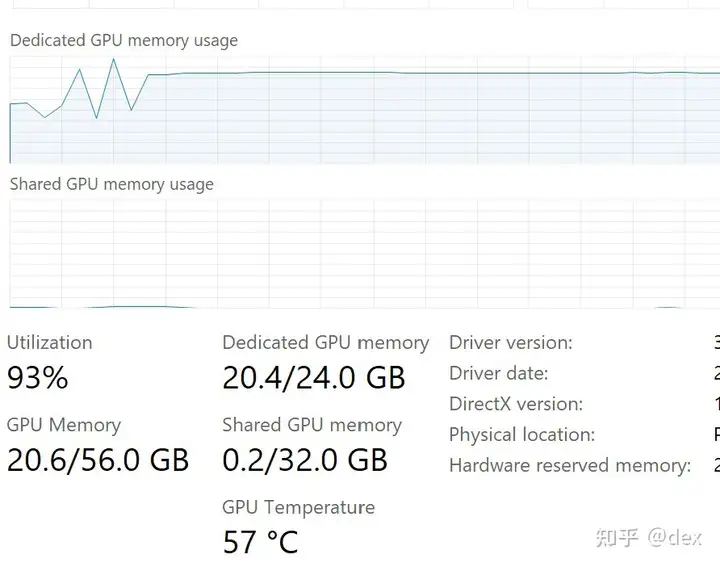
启用8bit Adam之后,训练时间15-20分钟,消耗依然在12GB左右,因此开头提到要一个高显存显卡。
训练完成后,选择你刚刚训练的模型权重,例如我训练了1000步,那么名字就是xmetalgolfer_1000.ckpt,如果保存了中间步骤,有可能还会出现xmetalgolfer_500.ckpt之类的名字。如果名字没有出现那么点击右边的蓝色按钮刷新。
DreamBooth的模型非常容易训练过头(overfit),所以切忌贪杯,不是step越高越好,一般1200次是可以的。
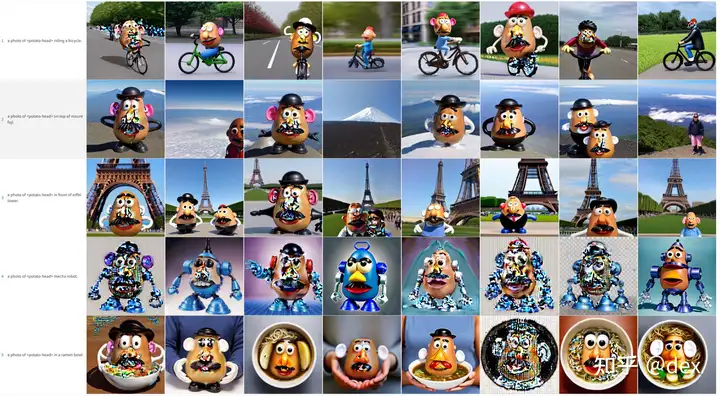
以下是我的结果
训练集:

输出结果
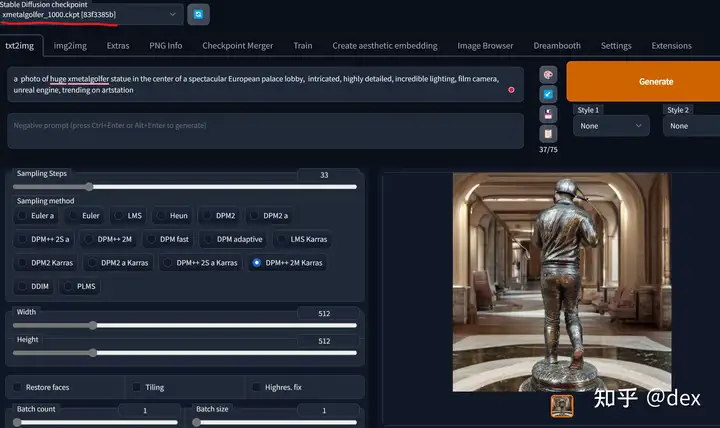


仅仅8分钟的训练,这个结果非常优秀了,如果进一步细调,以及加入classification dataset的话,效果还要好不少。下回有时间的话更新classification和 Prior Preservation的用法。
写了这么多,最后最后,有很多人想要体验二次元NovelAI的模型,这个就不公开给链接了,需要的同学私信我,精力有限,非粉不回。
本次更新就只写了outpainting和dreambooth,未来还有其它重要扩展的话继续在这里添加。
点击关注不迷路
END

