OpenAIChatGPT(二):十分钟读懂GPT-1
本篇文章是 OpenAI ChatGPT 系列文章的第三篇,在之前的文章中,我们已经介绍了基础模块 Transformer 的结构和代码实现。
GPT 系列是 OpenAI 的一系列预训练模型,GPT 的全称是 Generative Pre-Trained Transformer,顾名思义,GPT 的目标是通过 Transformer,使用预训练技术得到通用的语言模型。目前已经公布论文的有 GPT-1、GPT-2、GPT-3。
最近非常火的 ChatGPT 也是 GPT 系列模型,主要基于 GPT-3.5 进行微调。OpenAI 团队在 GPT3.5 基础上,使用人类反馈强化学习 (RLHF) 训练。首先使用了人类标注师撰写约1.2w-1.5w条问答数据,并用其作为基础数据预训练。随后让预训练好的模型(SFT)针对新问题列表生成若干条回答,并让人类标注师对这些回答进行排序。这些回答的排名内容将以配对比较的方式生成一个新的奖励模型(RM)。最后让奖励模型在更大的数据集上重新训练SFT,并将最后两个步骤反复迭代以获得最终的模型。
ChatGPT 本质上是基于 Transformer 的语言模型,在之前的文章中,我们已经详细介绍了 Transformer 的原理和代码实现,这篇文章文章开始,我们将逐一介绍 GPT 系列模型的技术。
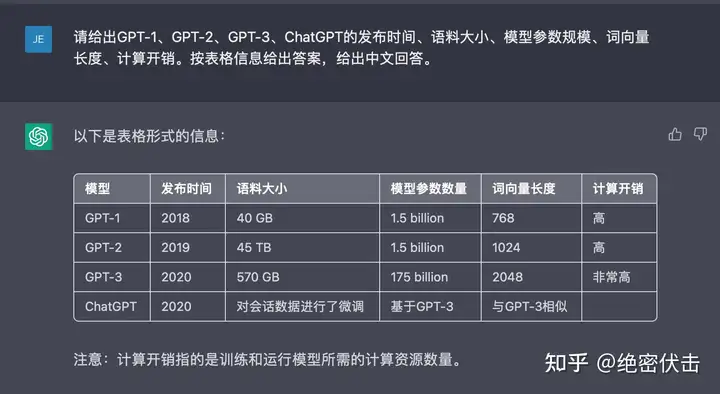
在介绍 GPT-1 之前,我们先让 ChatGPT 帮我们回答下 GPT 系列模型的基础信息,如下图所示。
前言
GPT-1 是 OpenAI 在论文Improving Language Understanding by Generative Pre-Training中提出的生成式预训练语言模型。该模型的核心思想:通过二段式的训练,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)。GPT-1 可以很好地完成若干下游任务,包括文本分类、文本蕴含、语义相似度、问答。在多个下游任务中,微调后的 GPT-1 系列模型的性能均超过了当时针对特定任务训练的 SOTA 模型。
备注:文本蕴含(Textual entailment)是指两个文本片段有指向关系。给定一个前提文本,根据这个前提去推断假说文本与前提文本的关系,一般分为蕴含关系(entailment)和矛盾关系(contradiction),蕴含关系表示从前提文本中可以推断出假说文本;矛盾关系即前提文本与假说文本矛盾。
1. GPT-1 模型结构
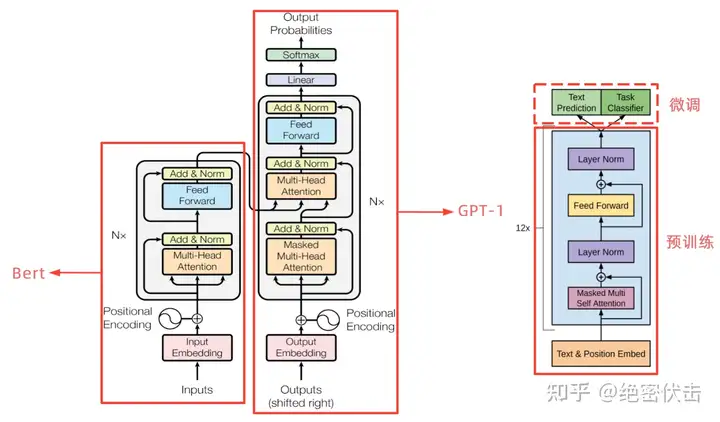
从上图可以看出,GPT-1 只使用了 Transformer 的 Decoder 结构,而且只是用了 Mask Multi-Head Attention。
Transformer 结构提出是用于机器翻译任务,机器翻译是一个序列到序列的任务,因此 Transformer 设计了Encoder 用于提取源端语言的语义特征,而用 Decoder 提取目标端语言的语义特征,并生成相对应的译文。GPT-1 目标是服务于单序列文本的生成式任务,所以舍弃了关于 Encoder 部分以及包括 Decoder 的 Encoder-Dcoder Attention 层(也就是 Decoder中 的 Multi-Head Atteion)。
GPT-1 保留了 Decoder 的Masked Multi-Attention 层和 Feed Forward 层,并扩大了网络的规模。将层数扩展到12层,GPT-1 还将Attention 的维数扩大到768(原来为512),将 Attention 的头数增加到12层(原来为8层),将 Feed Forward 层的隐层维数增加到3072(原来为2048),总参数达到1.5亿。
将预训练和 Fine-tuning 结合起来,GPT-1 的结构可以用下面的图表示:
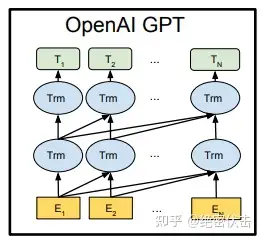
图中最下层 E 表示输入句子单词的 Embedding,中间的 Trm 表示 GPT 的单层 Transformer,最上层的 T 表示预测输出。
除了上面提到的,GPT-1 的 Transformer 结构还有哪些差异?
Q1:GPT-1 采用的是单向的语言模型?
A1:在 GPT 中采用了 Masked Multi-Head Attention,而 Masked Multi-Head Attention 只利用上文对当前位置的值预测,所以 GPT-1 被认为是单向的语言模型。
Q2:GPT-1 中 Position Encoding 的操作有何不同?
A2:在 Transformer 中,由于 Self-Attention 无法捕获文本的位置信息,因此需要对输入的词 Embedding 加入Position Encoding,在 Transformer 中采用了 sin 和 cos 的计算方法,而在 GPT-1 中,不再使用正弦和余弦的位置编码,而是采用与词向量相似的随机初始化,并在训练中进行更新。
从图1的最右侧可以看到,GPT-1 的训练包含两阶段,第一阶段是 GPT-1 模型的预训练过程,得到文本的语义向量;第二阶段是在具体任务上 Fine-tuning,以解决具体的下游任务。
2. 第一阶段:无监督预训练
对于 GPT-1 模型的预训练,同样采用标准语言模型,即通过上文预测当前的词,目标函数表示如下:
L_1\left( \mathcal{U} \right)=\sum_{i}\text{log}P\left( u_i|u_{i-k},...,u_{i-1};\theta \right)\tag1其中k是窗口大小。
GPT-1 使用了12个 Transformer 模块,这里的 Transformer 模块是图1经过变体后的结构,只包含 Decoder 中的Mask Multi-Head Attention 以及后面的 Feed Forward,表示如下:
\begin{align} h_0 & = UW_e+W_p\\ h_l & = \text{transformer_block}\left( h_{l-1} \right) \forall i\in\left[ 1,n \right]\\ P\left( u \right) & = \text{softmax}\left( h_nW_e^T \right) \end{align} \tag2其中U=\left( u_{-k},...,u_{-1} \right)是当前单词u的上文单词向量(比如[3222, 439, 150, 7345, 3222, 439, 6514, 7945],其中数字3222是词在此表中的索引),W_e是词向量矩阵(词的 Embedding 矩阵),W_P是 position embedding,n是 Transformer 层数。
3. 第二阶段:有监督 Fine-tuning
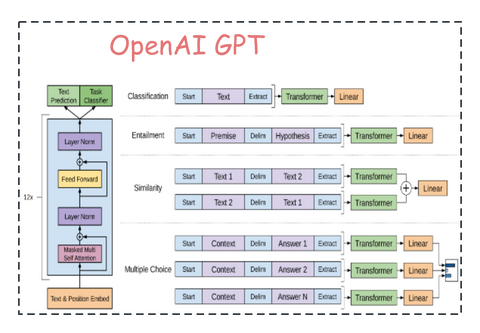
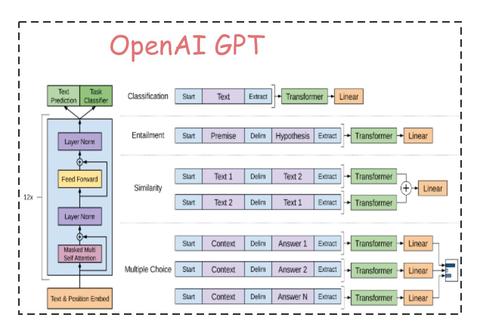
在 GPT-1 模型的下游任务中,需要根据 GPT-1 的网络结构,对下游任务做适当的修改,具体如下图所示:
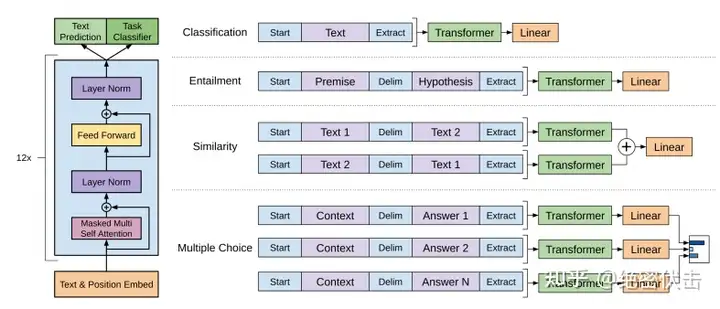
假设带有标签的数据集为\mathcal{C},其中,词的序列为x^1,\cdots ,x^m,标签为y。词序列输入到预训练好的 GPT-1 模型中,经过最后一层 Transformer block 得到输出h_l^m,然后输入到下游任务的线性层中,得到最终的预测输出:
P\left( y|x^1,...,x^m \right)=\text{softmax}\left( h_l^mW_y \right)\tag3此是目标函数为:
L_2\left( \mathcal{C} \right)=\sum_{\left( x,y \right)}\text{log}P\left( y|x^1,...,x^m \right)\tag4合并之前的预训练目标函数,最终的目标函数表示如下:
L_3\left( \mathcal{C} \right)=L_2\left( \mathcal{C} \right)+\lambda L_1\left( \mathcal{C} \right)\tag5
4. 不同下游任务的输入转换
针对不同的下游任务,需要对输入进行转换,从而能够适应 GPT-1 模型结构,比如:
- 分类任务。只需要在输入序列前后分别加上开始(Start)和结束(Extract)标记

- 句子关系任务。除了开始和结束标记,在两个句子中间还需要加上分隔符(Delim)

- 文本相似性任务。与句子关系判断任务相似,不同的是需要生成两个文本表示h_l^m

- 多项选择任务。文本相似任务的扩展,两个文本扩展为多个文本。

5. 代码实现
在之前的一篇文章中,我们已经完整的实现了 Transformer,有了这个基础后,实现 GPT-1 就容易很多,大家可以去看一下 Transformer 的代码实现。
我们看一下ChatGPT是怎么实现的:
有个大致的流程,但是这里面没有体现出 GPT-1 的核心部分:Mask Multi-Head Attention,下一篇文章我们介绍具体的代码实现,并给一个具体的例子,方便大家理解。
总结
GPT-1 是2018年6月提出的模型,比 Bert 还早几个月,当时在9个NLP任务上取得了 SOTA 的效果,但 GPT-1 使用的模型规模和数据量都比较小,这也就促使了 GPT-2 的诞生。
参考
绝密伏击:OPenAI ChatGPT(一):Tensorflow实现Transformer
绝密伏击:OPenAI ChatGPT(一):十分钟读懂Transformer
felixzhao:GPT:Generative Pre-Training
难赋:论文笔记:Improving Language Understanding by Generative Pre-Training
loomstar:GPT1--《Improving Language Understanding by Generative Pre-Training》
Ph0en1x:Transformer结构及其应用详解--GPT、BERT、MT-DNN、GPT-2
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf

Pre AGI 时代的第一场大型舆论「闹剧」。
马斯克和「深度学习三巨头」之一的 Bengio 等一千多位学界业界人士,联名呼吁叫停 AI 大模型研究的新闻,刷屏网络,掀起轩然大波。

GPT 的研究会被叫停吗?在学界业界看来,AI 真的会对人类产生威胁吗?这封联名信是证据凿凿的警示还是徒有恐慌的噱头?支持者、反对者纷纷表态,吵作一团。
在混乱中,我们发现,这份联名信的真实性和有效性都存在问题。很多位列署名区的人们,连他们自己都不知道签署了这封联名信。
另一方面,联名信本身的内容也值得商榷,呼吁人们重视 AI 安全性的问题当然没错,可叫停 AI 研究 6 个月,甚至呼吁政府介入,等待相关规则、共识的制定。这种天真且不切实际的做法,在科技发展的历史上实属少见。
与此同时,不少人发现,OpenAI 开放了一批 GPT-4 API 的接口申请,开发者们正兴奋地想要将这轰动世界的技术成功应用在他们的产品中。Pre AGI 时代的序幕,已经缓缓拉开。
AI 会停下来吗?AI 能停下来吗?
