我用GPT-2创造了3000个宠物小精灵,完美复刻《神奇宝贝》!
既然你诚心诚意的发问了,我们就大发慈悲的告诉你!
为了防止世界被破坏,为了守护世界的和平,贯彻爱与真实的邪恶,可爱又迷人的反派角色....
听到这段台词,相信很多朋友都会不由自主地接上一句.......
我们是穿梭在银河的火箭队!白洞!白色的明天在等着我们!
就这样~喵~

没错,它就是《神奇宝贝》中火箭队每次出场都让人忍不住发笑的经典台词。
1997年上映的《神奇宝贝》已经陪伴了我们二十年之久,给不少80、90后的童年留下了美好的回忆,尤其是那800多只宠物小精灵。

会放电的皮卡丘、经常酣睡的妙蛙种子、不好惹的小火龙,还有喵喵、超梦、可达鸭。
这些可可爱爱又奇奇怪怪的动漫小精灵让人记忆犹新,相信很多人小时候都幻想过拥有一支属于自己的精灵宝贝。
最近,一位名为Matthew Rayfield的程序员就满足了自己的愿望。他用《神奇宝贝》中的788只动漫形象作为原型,通过AI生成了3000个全新的宠物小精灵。

而这个AI正是自然语言模型GPT-2.
GPT-2:精灵制造机
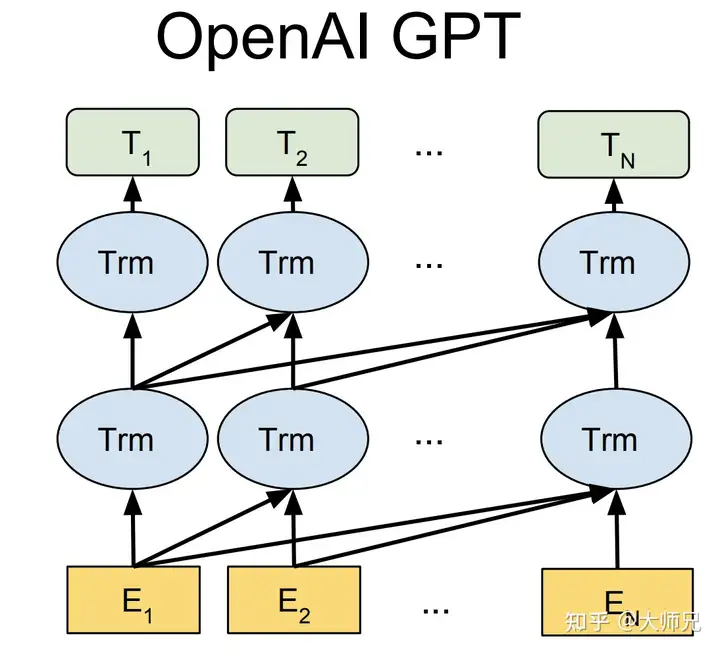
提到NLP模型,我们印象最深的可能是GPT-3。今年该模型因1750亿超大参数量和超强应用,在各大媒体平台频频刷屏。GPT-2,与GPT-3师出同门,都是OpenAI研发的自然语言处理模型,两个模型最大的不同是它的参数量,GPT-2仅为15亿。
但这并不影响它的应用范围。与GPT-3类似,GPT-2也可以用来写故事、画图表,或者玩国际象棋。

最近Rayfield受到GPT-2在国际象棋和民间音乐上应用的启发,也想来搞点不一样的事情。
他突发奇想决定用GPT-2来生成全新的宠物精灵形象,结果效果还不错。Rayfield从3000个生成图像中挑选出了6个,如图:

emm...看起来,小精灵原型还不错,但就是清晰度太差。Rayfield又邀请了业内知名动漫设计师雷切尔布里格斯(Rachel Briggs)来帮他完成这些精灵的重绘工作。
最终,基于GPT-2生成的原型,这些宠物小精灵就变成了这样:



Rayfield简单介绍了他利用GPT-2创建这些精灵的实现过程。大致就是:搜寻了788张小精灵图片(均为64x64像素)作为数据源,然后:
将图像转换为基于文本的格式。用输入文本训练GPT-2模型。使用经过训练的模型生成图像。将基于文本的图像格式转换为PNG。在这个过程中也出现了一些问题。比如在文本格式转换时,出现了很多嘈杂的像素,因此最终调整成了如下格式。

不过,用文字训练GPT-2的过程还相对简单,最棘手的环节是通过代码将输出结果变成规范化的图像格式。这部分代码Rayfield已将其在GitHub开源,感兴趣的朋友可以了解一下。

https://github.com/MatthewRayfield/pokemon-gpt-2
Image GPT:语言模型处理图像任务
需要说明的是,上述Rayfield用GPT-2语言模型来学习图像表征的方法,早已被OpenAI验证。
无监督和自监督的学习,或没有人为标记的数据的学习,在自然语言处理领域取得了令人瞩目的成功,因为像BERT、GPT-2、RoBERTa、T5等 Transformer 模型,在广泛的语言任务中取得了最佳成绩,但同类的模型在图像分类任务中,不能生成较为有用的特征。
出于这一目的,OpenAI尝试利用GPT-2处理图像分类任务,以探究用 Transformer 模型在学习图像表征方面的可行性。
他们发现,当用展开成像素序列——被称为 iGPT(image GPT)的图像来训练 GPT-2模型时,模型似乎能够捕捉二维图像特征,并且能够在没有人类提供的数据标注下,自动生成各种逻辑连续的图像样本。实验结果如图:

人类提供上半图(第一列),GPT-2自动补全下半图,右侧为原始图像
同时,该模型的特征在多个分类任务的数据集上也取得了不错的成绩,尤其是在 ImageNet 上取得了接近于最优的成绩,如下图。

在自然语言处理中,依赖于单词预测的无监督学习算法(如 GPT-2和 BERT)之所以成功,一个可能的原因是下游语言任务的实例出现在训练用的文本中。但相比之下,像素序列并不直接地包含它们所属的图像的标签。
而即使没有明确的监督,图像上的 GPT-2仍然起作用。OpenAI研究团队认为其原因是足够大的 Transformer 模型,通过训练来预测下一个像素,最终它能够学会根据清晰可识别对象来生成具有多样性的样本。

他们采用一种通用的无监督学习算法—生成序列建模进行了测试。具体来说,他们在 ImageNet 上分别训练包含76M、455M 和1.4B 参数的 iGPT-S、iGPT-M 和 iGPT-L Transformer;还在来自 ImageNet 和互联网的图像的混合数据集上训练 iGPT-XL ——一个68亿参数的 Transformer。由于对长序列采用密集注意力(dense attention)的建模计算成本高,他们用32x32、48x48和 64x64的低分辨率进行了训练。
最终实验结果表明,通过计算量来代替二维知识,以及通过从网络中选择的特征,序列 Transformer 可以与最优的卷积网竞争,实现无监督图像分类。此外,通过将 GPT-2语言模型直接应用于图像生成的结果,也进一步表明由于其简单性和通用性,序列 Transformer 在足够的计算量下,有可能成为学习到不同领域的特征的有效方法。
更多OpenAI团队实验内容可参见论文:https://cdn.openai.com/papers/GenerativePretrainingfromPixelsV2.pdf
引用链接:
https://www.reddit.com/r/MachineLearning/comments/jyh0h4/pgeneratingpokemonspriteswithgpt2/
https://matthewrayfield.com/articles/ai-generated-pokemon-sprites-with-gpt-2/
https://openai.com/blog/image-gpt/