ChatGPT—InstructGPT详解
前言
GPT系列是OpenAI的一系列预训练文章,GPT的全称是Generative Pre-Trained Transformer,顾名思义,GPT的目的就是通过Transformer为基础模型,使用预训练技术得到通用的文本模型。目前已经公布论文的有文本预训练GPT-1,GPT-2,GPT-3,以及图像预训练iGPT。据传还未发布的GPT-4是一个多模态模型。最近非常火的ChatGPT和今年年初公布的[1]是一对姐妹模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。所以要搞懂ChatGPT,我们必须要先读懂InstructGPT。
1. 背景知识
在介绍ChatGPT/InstructGPT之前,我们先介绍它们依赖的基础算法。
1.1 GPT系列
基于文本预训练的GPT-1[2],GPT-2[3],GPT-3[4]三代模型都是采用的以Transformer为核心结构的模型(图1),不同的是模型的层数和词向量长度等超参,它们具体的内容如表1。
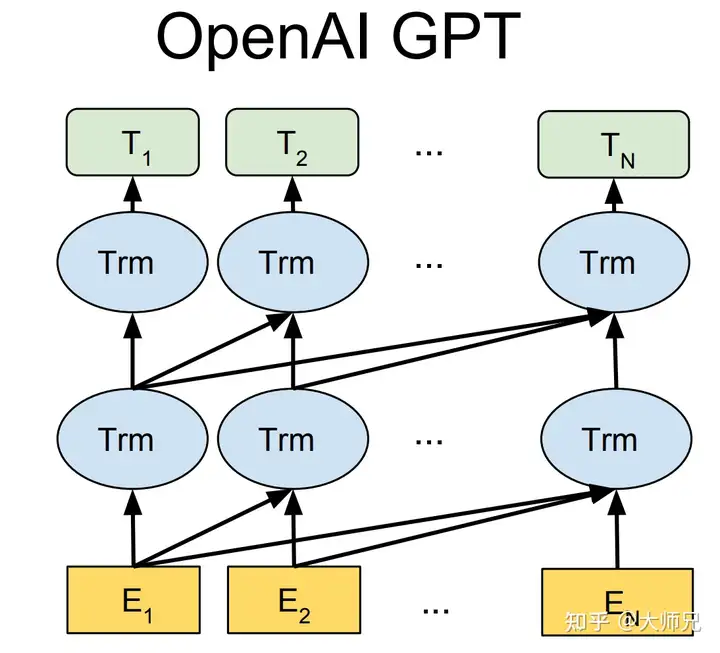
表1:历代GPT的发布时间,参数量以及训练量
| 模型 | 发布时间 | 层数 | 头数 | 词向量长度 | 参数量 | 预训练数据量 |
|---|---|---|---|---|---|---|
| GPT-1 | 2018 年 6 月 | 12 | 12 | 768 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 48 | - | 1600 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 96 | 96 | 12888 | 1,750 亿 | 45TB |
GPT-1比BERT诞生略早几个月。它们都是采用了Transformer为核心结构,不同的是GPT-1通过自左向右生成式的构建预训练任务,然后得到一个通用的预训练模型,这个模型和BERT一样都可用来做下游任务的微调。GPT-1当时在9个NLP任务上取得了SOTA的效果,但GPT-1使用的模型规模和数据量都比较小,这也就促使了GPT-2的诞生。
对比GPT-1,GPT-2并未在模型结构上大作文章,只是使用了更多参数的模型和更多的训练数据(表1)。GPT-2最重要的思想是提出了所有的有监督学习都是无监督语言模型的一个子集的思想,这个思想也是提示学习(Prompt Learning)的前身。GPT-2在诞生之初也引发了不少的轰动,它生成的新闻足以欺骗大多数人类,达到以假乱真的效果。甚至当时被称为AI界最危险的武器,很多门户网站也命令禁止使用GPT-2生成的新闻。
GPT-3被提出时,除了它远超GPT-2的效果外,引起更多讨论的是它1750亿的参数量。GPT-3除了能完成常见的NLP任务外,研究者意外的发现GPT-3在写SQL,JavaScript等语言的代码,进行简单的数学运算上也有不错的表现效果。GPT-3的训练使用了情境学习(In-context Learning),它是元学习(Meta-learning)的一种,元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
通过上面的分析我们可以看出从性能角度上讲,GPT有两个目标:
- 提升模型在常见NLP任务上的表现效果;
- 提升模型在其他非典型NLP任务(例如代码编写,数学运算)上的泛化能力。
另外,预训练模型自诞生之始,一个备受诟病的问题就是预训练模型的偏见性。因为预训练模型都是通过海量数据在超大参数量级的模型上训练出来的,对比完全由人工规则控制的专家系统来说,预训练模型就像一个黑盒子。没有人能够保证预训练模型不会生成一些包含种族歧视,性别歧视等危险内容,因为它的几十GB甚至几十TB的训练数据里几乎肯定包含类似的训练样本。这也就是InstructGPT和ChatGPT的提出动机,论文中用3H概括了它们的优化目标:
- 有用的(Helpful);
- 可信的(Honest);
- 无害的(Harmless)。
OpenAI的GPT系列模型并没有开源,但是它们提供了模型的试用网站,有条件的同学可以自行试用。
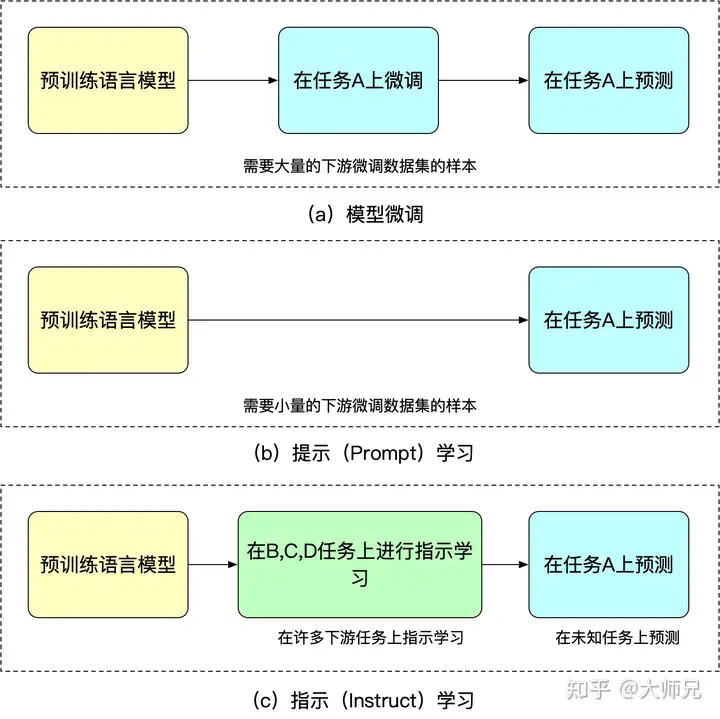
1.2 指示学习(Instruct Learning)和提示(Prompt Learning)学习
指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》[5]文章中提出的思想。指示学习和提示学习的目的都是去挖掘语言模型本身具备的知识。不同的是Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。我们可以通过下面的例子来理解这两个不同的学习方式:
- 提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了。
- 指示学习:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差。
指示学习的优点是它经过多任务的微调后,也能够在其他任务上做zero-shot,而提示学习都是针对一个任务的。泛化能力不如指示学习。我们可以通过图2来理解微调,提示学习和指示学习。
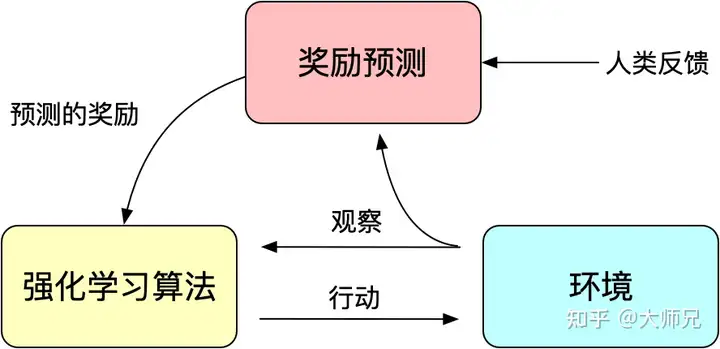
1.3 人工反馈的强化学习
因为训练得到的模型并不是非常可控的,模型可以看做对训练集分布的一个拟合。那么反馈到生成模型中,训练数据的分布便是影响生成内容的质量最重要的一个因素。有时候我们希望模型并不仅仅只受训练数据的影响,而是人为可控的,从而保证生成数据的有用性,真实性和无害性。论文中多次提到了对齐(Alignment)问题,我们可以理解为模型的输出内容和人类喜欢的输出内容的对齐,人类喜欢的不止包括生成内容的流畅性和语法的正确性,还包括生成内容的有用性、真实性和无害性。
我们知道强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模型训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人工反馈的强化学习便应运而生。
RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》[6],它通过人工标注作为反馈,提升了强化学习在模拟机器人以及雅达利游戏上的表现效果。
InstructGPT/ChatGPT中还用到了强化学习中一个经典的算法:OpenAI提出的最近策略优化(Proximal Policy Optimization,PPO)[7]。PPO算法是一种新型的Policy Gradient算法,Policy Gradient算法对步长十分敏感,但是又难以选择合适的步长,在训练过程中新旧策略的的变化差异如果过大则不利于学习。PPO提出了新的目标函数可以在多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。其实TRPO也是为了解决这个思想但是相比于TRPO算法PPO算法更容易求解。
2. InstructGPT/ChatGPT原理解读
有了上面这些基础知识,我们再去了解InstructGPT和ChatGPT就会简单很多。简单来说,InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。InstructGPT/ChatGPT的训练流程如图4所示。
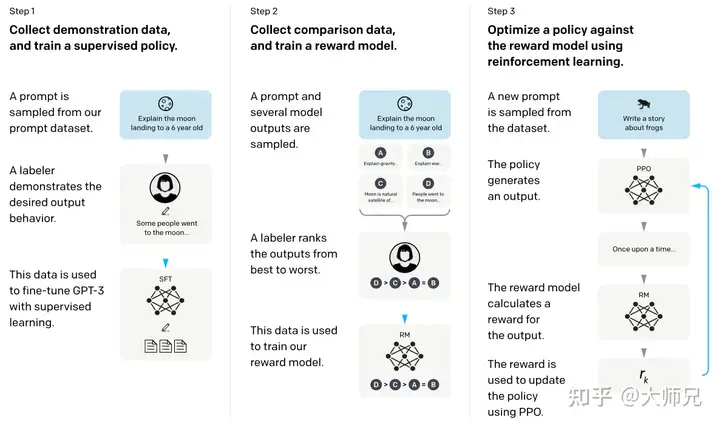
从图4中我们可以看出,InstructGPT/ChatGPT的训练可以分成3步,其中第2步和第3步是的奖励模型和强化学习的SFT模型可以反复迭代优化。
- 根据采集的SFT数据集对GPT-3进行有监督的微调(Supervised FineTune,SFT);
- 收集人工标注的对比数据,训练奖励模型(Reword Model,RM);
- 使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型。
根据图4,我们将分别介绍InstructGPT/ChatGPT的数据集采集和模型训练两个方面的内容。
2.1 数据集采集
如图4所示,InstructGPT/ChatGPT的训练分成3步,每一步需要的数据也有些许差异,下面我们分别介绍它们。
2.1.1 SFT数据集
SFT数据集是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler)。并且他们对labeler进行了培训。在这个数据集中,标注工的工作是根据内容自己编写指示,并且要求编写的指示满足下面三点:
- 简单任务:labeler给出任意一个简单的任务,同时要确保任务的多样性;
- Few-shot任务:labeler给出一个指示,以及该指示的多个查询-相应对;
- 用户相关的:从接口中获取用例,然后让labeler根据这些用例编写指示。
2.1.2 RM数据集
RM数据集用来训练第2步的奖励模型,我们也需要为InstructGPT/ChatGPT的训练设置一个奖励目标。这个奖励目标不必可导,但是一定要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT/ChatGPT的做法是先让模型生成一批候选文本,让后通过labeler根据生成数据的质量对这些生成内容进行排序。
2.1.3 PPO数据集
InstructGPT的PPO数据没有进行标注,它均来自GPT-3的API的用户。既又不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。
2.1.4 数据分析
因为InstructGPT/ChatGPT是在GPT-3基础上做的微调,而且因为涉及了人工标注,它们数据总量并不大,表2展示了三份数据的来源及其数据量。
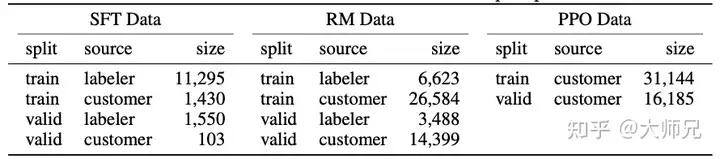
论文的附录A对数据的分布进行了更详细的讨论,这里我列出几个可能影响模型效果的几项:
- 数据中96%以上是英文,其它20个语种例如中文,法语,西班牙语等加起来不到4%,这可能导致InstructGPT/ChatGPT能进行其它语种的生成,但效果应该远不如英文;
- 提示种类共有9种,而且绝大多数是生成类任务,可能会导致模型有覆盖不到的任务类型;
- 40名外包员工来自美国和东南亚,分布比较集中且人数较少, InstructGPT/ChatGPT的目标是训练一个价值观正确的预训练模型,它的价值观是由这40个外包员工的价值观组合而成。而这个比较窄的分布可能会生成一些其他地区比较在意的歧视,偏见问题。
此外,ChatGPT的博客中讲到ChatGPT和InstructGPT的训练方式相同,不同点仅仅是它们采集数据上有所不同,但是并没有更多的资料来讲数据采集上有哪些细节上的不同。考虑到ChatGPT仅仅被用在对话领域,这里我猜测ChatGPT在数据采集上有两个不同:1. 提高了对话类任务的占比;2. 将提示的方式转换Q&A的方式。当然这里也仅仅是猜测,更准确的描述要等到ChatGPT的论文、源码等更详细的资料公布我们才能知道。
2.2 训练任务
我们刚介绍到InstructGPT/ChatGPT有三步训练方式。这三步训练会涉及三个模型:SFT,RM以及PPO,下面我们详细介绍它们。
2.2.1 有监督微调(SFT)
这一步的训练和GPT-3一致,而且作者发现让模型适当过拟合有助于后面两步的训练。
2.2.2 奖励模型(RM)
因为训练RM的数据是一个labeler根据生成结果排序的形式,所以它可以看做一个回归模型。RM结构是将SFT训练后的模型的最后的嵌入层去掉后的模型。它的输入是prompt和Reponse,输出是奖励值。具体的讲,对弈每个prompt,InstructGPT/ChatGPT会随机生成K个输出(4\leq K\leq 9),然后它们向每个labeler成对的展示输出结果,也就是每个prompt共展示C_K^2个结果,然后用户从中选择效果更好的输出。在训练时,InstructGPT/ChatGPT将每个prompt的C_K^2个响应对作为一个batch,这种按prompt为batch的训练方式要比传统的按样本为batch的方式更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型中一次。
奖励模型的损失函数表示为式(1)。这个损失函数的目标是最大化labeler更喜欢的响应和不喜欢的响应之间的差值。
loss(θ)=−1(K2)E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]\operatorname{loss}(\theta)=-\frac{1}{\left(\begin{array}{c}K \\ 2\end{array}\right)} E_{\left(x, y_w, y_l\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_w\right)-r_\theta\left(x, y_l\right)\right)\right)\right] \tag1
其中r_\theta\left(x, y\right)是提示x和响应y在参数为\theta的奖励模型下的奖励值,y_w是labeler更喜欢的响应结果,y_l是labeler不喜欢的响应结果。D是整个训练数据集。
2.2.3 强化学习模型(PPO)
强化学习和预训练模型是最近两年最为火热的AI方向之二,之前不少科研工作者说强化学习并不是一个非常适合应用到预训练模型中,因为很难通过模型的输出内容建立奖励机制。而InstructGPT/ChatGPT反直觉的做到了这点,它通过结合人工标注,将强化学习引入到预训练语言模型是这个算法最大的创新点。
如表2所示,PPO的训练集完全来自API。它通过第2步得到的奖励模型来指导SFT模型的继续训练。很多时候强化学习是非常难训练的,InstructGPT/ChatGPT在训练过程中就遇到了两个问题:
- 问题1:随着模型的更新,强化学习模型产生的数据和训练奖励模型的数据的差异会越来越大。作者的解决方案是在损失函数中加入KL惩罚项\beta \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right)来确保PPO模型的输出和SFT的输出差距不会很大。
- 问题2:只用PPO模型进行训练的话,会导致模型在通用NLP任务上性能的大幅下降,作者的解决方案是在训练目标中加入了通用的语言模型目标\gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_\phi^{\mathrm{RL}}(x)\right)\right],这个变量在论文中被叫做PPO-ptx。
综上,PPO的训练目标为式(2)。\text { objective }(\phi)=E_{(x, y) \sim D_{\pi_\phi}^{\mathrm{RL}}}\left[r_\theta(x, y)-\beta \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right)\right] + \gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_\phi^{\mathrm{RL}}(x)\right)\right] \tag2
3. InstructGPT/ChatGPT的性能分析
不可否认的是,InstructGPT/ChatGPT的效果是非常棒的,尤其是引入了人工标注之后,让模型的价值观和的正确程度和人类行为模式的真实性上都大幅的提升。那么,仅仅根据InstructGPT/ChatGPT的技术方案和训练方式,我们就可以分析出它可以带来哪些效果提升呢?
3.1 优点
- InstructGPT/ChatGPT的效果比GPT-3更加真实:这个很好理解,因为GPT-3本身就具有非常强的泛化能力和生成能力,再加上InstructGPT/ChatGPT引入了不同的labeler进行提示编写和生成结果排序,而且还是在GPT-3之上进行的微调,这使得我们在训练奖励模型时对更加真实的数据会有更高的奖励。作者也在TruthfulQA数据集上对比了它们和GPT-3的效果,实验结果表明甚至13亿小尺寸的PPO-ptx的效果也要比GPT-3要好。
- InstructGPT/ChatGPT在模型的无害性上比GPT-3效果要有些许提升:原理同上。但是作者发现InstructGPT在歧视、偏见等数据集上并没有明显的提升。这是因为GPT-3本身就是一个效果非常好的模型,它生成带有有害、歧视、偏见等情况的有问题样本的概率本身就会很低。仅仅通过40个labeler采集和标注的数据很可能无法对模型在这些方面进行充分的优化,所以会带来模型效果的提升很少或者无法察觉。
- InstructGPT/ChatGPT具有很强的Coding能力:首先GPT-3就具有很强的Coding能力,基于GPT-3制作的API也积累了大量的Coding代码。而且也有部分OpenAI的内部员工参与了数据采集工作。通过Coding相关的大量数据以及人工标注,训练出来的InstructGPT/ChatGPT具有非常强的Coding能力也就不意外了。
3.2 缺点
- InstructGPT/ChatGPT会降低模型在通用NLP任务上的效果:我们在PPO的训练的时候讨论了这点,虽然修改损失函数可以缓和,但这个问题并没有得到彻底解决。
- 有时候InstructGPT/ChatGPT会给出一些荒谬的输出:虽然InstructGPT/ChatGPT使用了人类反馈,但限于人力资源有限。影响模型效果最大的还是有监督的语言模型任务,人类只是起到了纠正作用。所以很有可能受限于纠正数据的有限,或是有监督任务的误导(只考虑模型的输出,没考虑人类想要什么),导致它生成内容的不真实。就像一个学生,虽然有老师对他指导,但也不能确定学生可以学会所有知识点。
- 模型对指示非常敏感:这个也可以归结为labeler标注的数据量不够,因为指示是模型产生输出的唯一线索,如果指示的数量和种类训练的不充分的话,就可能会让模型存在这个问题。
- 模型对简单概念的过分解读:这可能是因为labeler在进行生成内容的比较时,倾向于给给长的输出内容更高的奖励。
- 对有害的指示可能会输出有害的答复:例如InstructGPT/ChatGPT也会对用户提出的AI毁灭人类计划书给出行动方案(图5)。这个是因为InstructGPT/ChatGPT假设labeler编写的指示是合理且价值观正确的,并没有对用户给出的指示做更详细的判断,从而会导致模型会对任意输入都给出答复。虽然后面的奖励模型可能会给这类输出较低的奖励值,但模型在生成文本时,不仅要考虑模型的价值观,也要考虑生成内容和指示的匹配度,有时候生成一些价值观有问题的输出也是可能的。

3.3 未来工作
我们已经分析了InstrcutGPT/ChatGPT的技术方案和它的问题,那么我们也可以看出InstrcutGPT/ChatGPT的优化角度有哪些了。
- 人工标注的降本增效:InstrcutGPT/ChatGPT雇佣了40人的标注团队,但从模型的表现效果来看,这40人的团队是不够的。如何让人类能够提供更有效的反馈方式,将人类表现和模型表现有机和巧妙的结合起来是非常重要的。
- 模型对指示的泛化/纠错等能力:指示作为模型产生输出的唯一线索,模型对他的依赖是非常严重的,如何提升模型对指示的泛化能力以及对错误指示示的纠错能力是提升模型体验的一个非常重要的工作。这不仅可以让模型能够拥有更广泛的应用场景,还可以让模型变得更智能。
- 避免通用任务性能下降:这里可能需要设计一个更合理的人类反馈的使用方式,或是更前沿的模型结构。因为我们讨论了InstrcutGPT/ChatGPT的很多问题可以通过提供更多labeler标注的数据来解决,但这会导致通用NLP任务更严重的性能下降,所以需要方案来让生成结果的3H和通用NLP任务的性能达到平衡。
3.4 InstrcutGPT/ChatGPT的热点话题解答
- ChatGPT的出现会不会导致底层程序员失业?从ChatGPT的原理和网上漏出的生成内容来看,ChatGPT生成的代码很多可以正确运行。但程序员的工作不止是写代码,更重要的是找到问题的解决方案。所以ChatGPT并不会取代程序员,尤其是高阶程序员。相反它会向现在很多的代码生成工具一样,成为程序员写代码非常有用的工具。
- Stack Overflow 宣布临时规则:禁止 ChatGPT。ChatGPT本质上还是一个文本生成模型,对比生成代码,它更擅长生成以假乱真的文本。而且文本生成模型生成的代码或者解决方案并不能保证是可运行而且是可以解决问题的,但它以假乱真的文本又会迷惑很多查询这个问题的人。Stack Overflow为了维持论坛的质量,封禁ChatGPT也是情理之中。
- 聊天机器人 ChatGPT 在诱导下写出「毁灭人类计划书」,并给出代码,AI 发展有哪些问题需关注?ChatGPT的「毁灭人类计划书」是它在不可遇见的指示下根据海量数据强行拟合出来的生成内容。虽然这些内容看起来很真实,表达也很流畅,这说明的只是ChatGPT具有非常强的生成效果,并不表示ChatGPT具备毁灭人类的思想。因为他仅仅是一个文本生成模型,并不是一个决策模型。
4. 总结
就像很多人们算法刚诞生时一样,ChatGPT凭借有用性,真实性,无害性的效果,引起了业内广泛的关注和人类对AI的思考。但是当我们看完它的算法原理之后,发现它并没有业内宣传的那么恐怖。反而我们可以从它的技术方案中学到很多有价值的东西。InstrcutGPT/ChatGPT在AI界最重要的贡献是将强化学习和预训练模型巧妙的结合起来。而且通过人工反馈提升了模型的有用性,真实性和无害性。ChatGPT也进一步提升大模型的成本,之前还只是比拼数据量和模型规模,现在甚至也引入了雇佣的外包这一支出,让个体工作者更加望而却步。
附:
本文作者通过和@人民邮电出版社的合作,目前此专栏的大部分内容经过反复的校正和排版已发布成书籍《深度学习高手笔记——卷1:基础算法》和《深度学习高手笔记——卷2:前沿应用》,内容经过作者和出版社的专业审核人员的10余轮的教改,内容的丰富性,算法讲解的精确性,叙述文本的流畅度已大幅提升。目前卷1已多平台上架,欢迎大家点击下面链接购买。

参考
- ^Ouyang, Long, et al. "Training language models to follow instructions with human feedback." *arXiv preprint arXiv:2203.02155* (2022).https://arxiv.org/pdf/2203.02155.pdf
- ^Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training.https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
- ^Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. and Sutskever, I., 2019. Language models are unsupervised multitask learners. *OpenAI blog*, *1*(8), p.9.https://life-extension.github.io/2020/05/27/GPT%E6%8A%80%E6%9C%AF%E5%88%9D%E6%8E%A2/language-models.pdf
- ^Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. Language models are few-shot learners. *arXiv preprint arXiv:2005.14165* (2020).https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- ^Wei, Jason, et al. "Finetuned language models are zero-shot learners." *arXiv preprint arXiv:2109.01652* (2021).https://arxiv.org/pdf/2109.01652.pdf
- ^Christiano, Paul F., et al. "Deep reinforcement learning from human preferences." *Advances in neural information processing systems* 30 (2017).https://arxiv.org/pdf/1706.03741.pdf
- ^Schulman, John, et al. "Proximal policy optimization algorithms." *arXiv preprint arXiv:1707.06347* (2017).https://arxiv.org/pdf/1707.06347.pdf

图片来源:英伟达
多年来,黄仁勋一直倡导AI和机器学习,长期押注AI的潜力也注定了英伟达是ChatGPT浪潮中受益最多的公司之一。因为,对于大型语言模型来说,算力是其中最重要的一环,因此高度依赖英伟达强大的GPU芯片。
今年年初至今,英伟达股价的涨幅已超80%。英伟达2023财年第四季度财报显示,该公司的AI数据中心业务再次成为最大的收入来源。尽管四季度营收同比下滑21%,但基于AI芯片的销售,该公司在当季的表现略好于市场预期。

图片来源:谷歌财经
如今,谷歌、亚马逊等正在自研芯片的科技巨头,英伟达的未来之路并不好走。有分析认为,英伟达不太可能和巨头在云服务上直接竞争,但可能会推出特定的AI产品。此外,鉴于微软是唯一一家尚未推出AI芯片的超大规模厂商,其与英伟达的合作对双方来说意义重大。英伟达可以更好地耕耘数据中心,微软不一定需要通过构建基础设施来与亚马逊竞争,而是依靠前者成为AI最大的参与者之一。
AI正迎来iPhone时刻
GTC开发者大会于3月20日~23日举行,本届大会将举办超过650场由技术、商业、学术和政府领域领导者主持的会议。
在3月21日晚的主旨演讲中,黄仁勋介绍了英伟达在AI领域的最新进展,并展示了这些技术在包括科技、医疗、金融、图像、物流配送等各行各业的应用场景,并宣布了包括量子硬件公司 Anyon Systems、Atom Computing、电信巨头AT&T Corp、医疗保健技术提供商美敦力、甲骨文、Adobe、Getty Image等一批全新的合作伙伴。

图片来源:英伟达
我们正处于AI的iPhone时刻,黄仁勋说道,初创公司正在竞相打造颠覆性产品和商业模式,而科技巨头们也在寻求突破。他表示,新的AI技术和迅速蔓延的应用正在改变科学和各行各业,并为成千上万的新公司开辟新的疆域。这将是迄今为止最重要的一次GTC。
提速10倍!黄仁勋首谈ChatGPT专用GPU,英伟达GTC大会还有哪些看点?
如果要问,除了OpenAI和微软之外,谁是ChatGPT引领的人工智能(AI)革命中最大的赢家?毫无疑问,英伟达
抖音短视频运营学习路线图—揭秘抖音为什么要养号?提供全面的抖音养号实操方法
抖音短视频运营学习路线图,带你全面系统性学习抖音短视频运营!第四篇:抖音养号实操方法