OpenAI何以掀翻Google布局多年的AI大棋?
来源:飞哥说AI
作者:高佳;创意:李志飞
编辑:好困
【新智元导读】2023年从一场巨头之间的巨额合作开始,一场汹涌已久的AI暗战摆上了台面。
随着微软和 OpenAI 融资的推进,双方在关系变得更加深厚复杂的同时,也在与谷歌等竞争对手的较量中鏖战上风。一面是Google连夜唤回创始人,急推高仿Bard;一面是OpenAI的ChatGPT风头正劲,全民翘首以待GPT-4的到来。一直在AI领域堪称老大哥的Google,在这场棋局中一酸再酸,毕竟一度在LLM领先的Google曾经看似更有赢战先机。从2017年举世发布Transformer,奠定LLM的基石,到2021年5月的I/O大会上,LaMDA惊艳众人的亮相,Google风光无限。直到Bard官宣前,被动一直被视为Google面对ChatGPT的处境。Google如何一步步输掉这盘布局多年的AI大棋,OpenAI又何以让Google棋输先著?首先,让我们回顾一下蕴含在这场旷日持久的AI暗战之下的关键技术时间线。

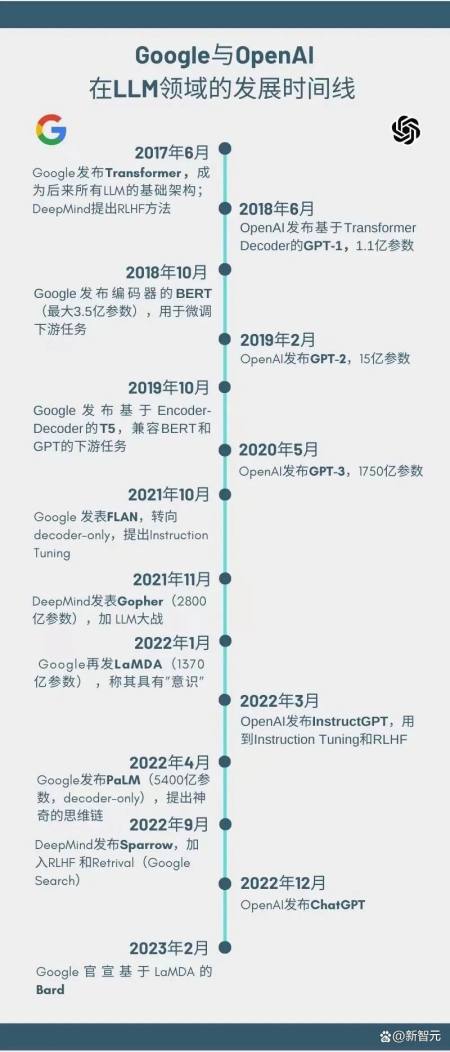
01 Google与OpenAI,LLM领域的发展时间线
从对ChatGPT技术路线的拆解追溯,及其论文中提供的技术点和示意图看,ChatGPT与 InstructGPT 核心思想一致。
其关键能力来自几个方面:强大的基座模型能力(InstructGPT),高质量的真实数据,以及从用户标注中反馈学习(RLHF)等,以此一窥ChatGPT是如何一步步进化成目前的强大形态。
2017年,DeepMind最早提出了RLHF概念,这一后来解锁ChatGPT重要涌现能力的关键,它通过人工标注作为反馈,提升了强化学习在模拟机器人以及游戏上的表现效果。同年6月,Google发布NLP领域的里程碑——Transformer,成为后来所有LLM的基础架构,也为GPT铺就了前提。2018年6月,在Transformer问世不到一年的时间,OpenAI发布了只有解码器(decoder-only)的GPT生成式预训练模型,通过大数据集进行训练,并主张通过大规模、无监督预训练+有监督微调进行模型构建。2018年10月,Google重磅推出著名的具有划时代意义的BERT,一个比GPT大四倍,拥有3.4亿参数的大模型,几乎在所有表现上碾压了GPT。而自带光环的BERT只有编码器,用一种完形填空的方法,其训练效果超过人类表现,宣告NLP范式的改变。2019年2月,被碾压的OpenAI准备背水一战,此时一个重要的命题摆在面前,BERT的大火让是否坚持做生成式模型成为一种灵魂拷问,但OpenAI坚定自己的目标——AGI,孤勇直前地践行生成式,并加倍投入,提出有15亿参数的GPT-2,并没有特别新颖的架构,它只是基于Transformer的解码器,稍做修改。尽管最初OpenAI并不愿意发布它,因担心它可能被用来向社交网络发送假新闻。2019年10月,Google发布了统一的模型框架——T5,基于编码解码器的T5(BERT只有编码,GPT只用解码),最大模型110亿参数并开放。兼容了BERT和GPT下游任务的T5,再次让Google风光无两。2020年5月,卧薪尝胆的OpenAI,在生成式之路一往无前,发布了规模是GPT-2两个数量级的1750亿参数的GPT-3,在业内掀起AGI热浪,也拉响了巨头规模竞赛的号角。2021年10月,Google推出FLAN(1370亿参数),并从此开始重新转向只有解码器的模型,还提出了ChatGPT用到的Instruction Tuning概念。2022年1月,Google再推LaMDA(1370亿参数),展示了接近人类水平的对话质量以及在安全性和事实基础方面的显著改进,并称其可能具有意识。所有人在当时觉得Google已在LLM遥遥领先。2022年3月,OpenAI发表经过魔鬼调教的InstructGPT(1750亿参数),提到采用Instruction Finetune和RLHF,比GPT-3更擅长与人类沟通,但并未引起大规模的关注。2022年4月,Google发布基于通用AI架构的语言模型PaLM(5400亿参数),文中提到了那一神奇的激发ChatGPT逻辑能力的思维链。2022年9月,DeepMind发表Sparrow(700亿),加入RLHF和Retrival,但反应平平。2022年12月,OpenAI的ChatGPT席卷而来,是InstructGPT的兄弟模型,一经问世迅速引爆全球,堪称人类对AGI里程碑的一步。2023年2月,Google发布基于LaMDA的Bard,正式对决ChatGPT。
02功败垂成,Google错失的那些时间点
此时,回头凝望被动应战的Google,来反思Google此前是怎样一步步错失了时间和先机。
错失20个月的解码器押注如果只用解码器的生成式是LLM的王道,2019年10月,Google同时押注编码解码器的T5,整整错失20个月,直到2021年10月发布FLAN才开始重新转变为decoder-only。举棋不定的稠密和稀疏之争如果稠密大模型是王道,Google押注了Mixture of Experts的稀疏多模态结构,全力投入Pathways下一代AI架构,而DeepMind又加入LLM的竞争太晚。直到2020年GPT-3横空出世的18个月后,DeepMind才训练出比GPT-3更大的模型,酝酿许久的Google在2022年4月才发布3倍于GPT-3的PaLM。迟到24个月的RLHF应用而在RLHF上,最早的概念提出者DeepMind及Google,起了个大早却迟到了24个月。早在2017年6月,DeepMind率先提出RLHF,2020年9月OpenAI将其用于GPT-3上,DeepMind直到2022年9月才用于Sparrow,而运筹帷幄的Google到现在还未见RLHF在LLM上的论文,更未见将研究成果应用于任何产品。尽管拥有AI技术和能力,Google的保守迟疑和兵力分散,让其在OpenAI的势如破竹面前,功败垂成。一招迟缓,全线溃败。高手对弈,还需兵贵神速。
03 OpenAI时速下的远见和信念

反观OpenAI的速度和选择,似乎一切都是势之必然。
蕴含着远见和信念的OpenAI更具果敢和魄力。在巨大的不确定未来和竞争对手的压力面前,OpenAI始终坚定最初的目标和信仰,迈出充满信仰力量的一步步。从2018年开始,四年如一日,只用decoder only的GPT,践行着暴力美学——以大模型的路径,实现AGI。图灵奖得主LeCun也说OpenAI的ChatGPT不是什么革命性的东西,只是组合得很好。而正是如此简单朴素的坚持,见证了OpenAI的眼光和执着。从技术路径来看,OpenAI是实用至上的拿来主义。没有知识分子的清高,没有孤勇黑马的桀骜,无论是Transformer、Instruction Tuning、还是RLHF和思维链,不因是别人发明的就避之不用,而是取其精华,默默在自己的大模型里埋首用功。如果 Instruction Tuning 是关键,那Google和DeepMind在2021年10月发明了它以后,直到2022年12月都没有重视过。反观OpenAI只花了5个月就将其用到InstructGPT,坚实了ChatGPT的基础。如果将思维链视为 ChatGPT 能解题的关键,当Google还将它用于象牙塔的实验时,ChatGPT已准备走向产品化。
组织文化和产品路径上,OpenAI坚持产品驱动的AI研究,也始终坚持第一时间把玩具公示于众,敢于直面群嘲,敢于在众目睽睽之下迭代。反观学术驱动的MSR和项目驱动的DeepMind,从功利主义的结果来看,相比OpenAI的躬身入局沙场点兵,Google更像坐而论道纸上谈兵。PR层面,OpenAI并没有过多大公司声誉风险的羁绊和考虑,反而利用大众和媒体充满褒赞和争议的声音,热浪不息,全球风靡。犀利如箭的棋局背后是灵魂棋手的智慧,这也是OpenAI一切远见和信仰的真正来源。2015年,几位满怀对AI革新信仰又才华横溢的年轻人,从成立一个工程型的AI实验室出发,到今天OpenAI成为变革AI的引领者。如果说ChatGPT讲述了一个足够好的预测带来了你所梦想的一切的故事,那么其灵魂人物的前瞻眼光和今天的OpenAI也完美注解了这一句。历史的潮流奔涌向前,硅谷的创新土壤、互相竞逐的技术迭进、巨头的巨额注资,有万千人守护梦想的OpenAI走到历史的必然。
任何大卫击败歌利亚的故事,都值得我们思考。OpenAI此局高踞上风,与微软的联姻也将让两者更强。如今棋布错峙的谷歌,无法再按兵不动了。紧急应战的Bard能否让Google重归尊位?AIGC时代,几位科技巨头们之间的棋局激战正酣,一切还远未到握手言和的时刻。群雄逐鹿,一切才刚刚开始。
-
上一篇
image-20230220231246847 You can think of this as a very advanced autocomplete — the model processes your text prompt and tries to predict what’s most likely to come next.
你可以将它看作是一个非常先进的自动完成功能——模型处理你的文本提示,尝试预测接下来最可能出现的内容。
让我们从一条指示开始
Imagine you want to create a pet name generator. Coming up with names from scratch is hard!
假设你想创建一个宠物名字生成器。从零开始想出名字可真不容易!
First, you’ll need a prompt that makes it clear what you want. Let’s start with an instruction.Submit this promptto generate your first completion.
首先,你需要一个清晰表述你需求的提示。让我们从一条指示开始。提交这个提示来生成你的第一个完成结果。
image-20230220231616699 Not bad! Now, try making your instruction more specific.
不错!现在,试着让你的指示更加具体一些。
image-20230220231757559 As you can see, adding a simple adjective to our prompt changes the resulting completion. Designing your prompt is essentially how you program the model.
你可以看到,将一个简单的形容词添加到我们的提示中可以改变完成结果。设计你的提示本质上就是如何编程这个模型。
添加一些例子
Crafting good instructions is important for getting good results, but sometimes they aren’t enough. Let’s try making your instruction even more complex.
OpenAI快速入门(附代码)
-
下一篇
退休后热衷探索 Web3 的王慧文|图片来源:即刻王慧文
就在最近一段时间,并非 AI 领域专家的王慧文,开始给中国科技圈 AI 领域的各种牛人发微信、打电话、组饭局,至少我认识的几位 AI 精英无一例外都被他尝试组过队。
他一开始可能并没有明确要主导这件事,他只是希望深入参与到中国的通用大模型这件事里,不只是把钱给 VC 去投一下这个赛道。特别是在上一周,王慧文的 GPT 探讨进入了最高密度,从 2 月 8 号到 10 号每天一条朋友圈背后都是一个一个饭局和交流后的激情澎湃。看得出他对参与 GPT 这件事的决心和兴奋不断升级。
其实 ChatGPT 在语言能力上的惊艳表现,背后是 AI 在认知层面的技术飞跃。这就像是一个「金蛋」,里面显然孕育着「龙凤」,但它是怎么生出来的,基因序列是啥样的,到现在还是个迷。甚至,你找来所有 AI 领域的专家,都只能猜测这个飞跃的技术原理,但没有人有确信的答案。
王慧文入场,对中国版OpenAI争夺战意味着什么?
这次的快速入场,带来的不是尘埃落定,而是竞争的加速。