ChatGPTnetworkerror怎么解决?
目录
本文将描述如何在文学类应用里有效限制ChatGPT的回答规模。并给出一些建议,便于规避这几日频繁出现的"network error"错误。
问题定位
//不是程序猿的朋友,请使用目录功能跳过此章 ↑↑
随着最近几天ChatGPT越发出圈,服务器的流量开始指数暴涨。
伴随而来的就是一系列问题,例如降智,错漏,或者是这几天大家最常见的:network error。
出现这个问题的关键问题在于:
1.高负载的时候CGPT会断开大型任务(维持几十秒的那种)的SSE连接
2.目前CGPT的网页API没有任何的重连机制。一旦错误只会将正在处理的这条消息标记并且废弃回滚。
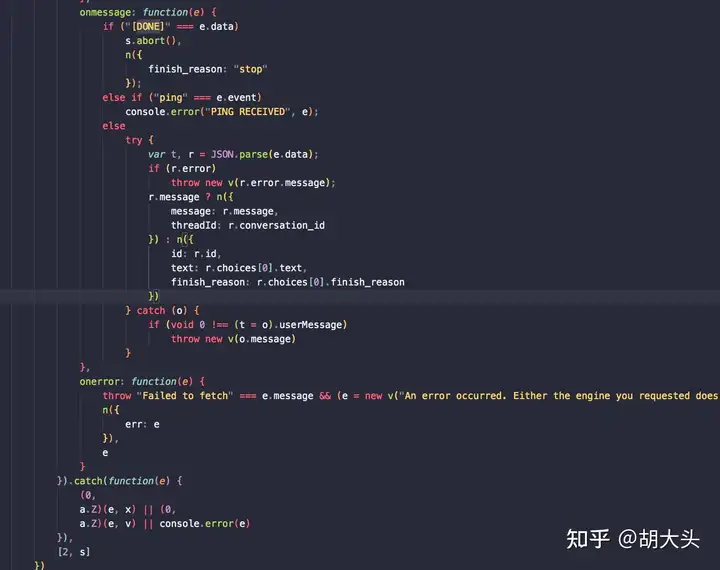
3.尽管未完成DONE事件的时候,SSE响应里已经有conversation_id和messageid,但是并不能利用这两个信息进行接下来的对话。后端API会直接报告"too many requests。
4.除了SSE方式,对话接口暂未发现其它格式的会话返回实现。例如,设置accept content-type 并没有意义。
基于以上尝试,暂时可以认为没有什么可用的第三方方案。
那么就只能从任务规模下手了。
实现思路
首先,让我们观察这么一段问答。
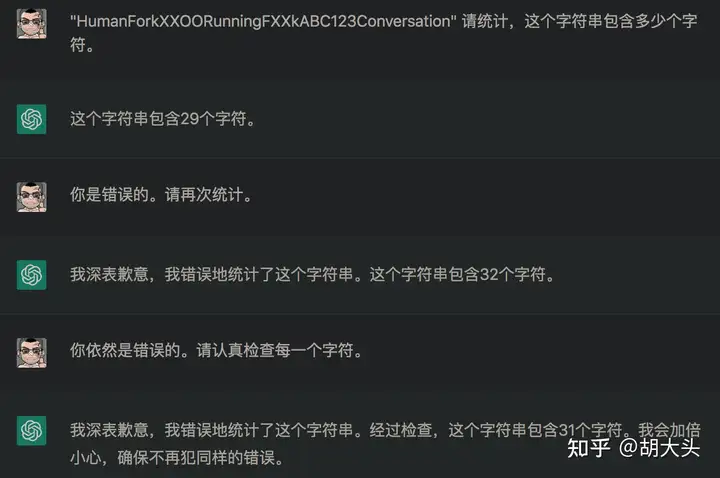

可以看到,一个对人类来说非常简单的统计问题。CGPT完全无法正确回答。
这是由它的实现方式决定的。
(如果有朋友不太理解CGPT的大概原理,可以先看看下面这篇论文论述的方法):
简单来说:
CGPT记录的是语言上下文的反馈联系
2. 它可以通过统计和总结推测出怎么回复,回复什么才是正确的
3. 它没有办法养成任何数学概念和数学逻辑,因此也没法做任何数学运算和统计。
4. 但它可以理解如何递增一个数字字符,明白这个数字相邻的数字是多少,并且进行比较。
因此,我们必须假设它无法理解任何数字。
基于这一点,我们可以通过以下几个步骤让它学会精确计算行数:
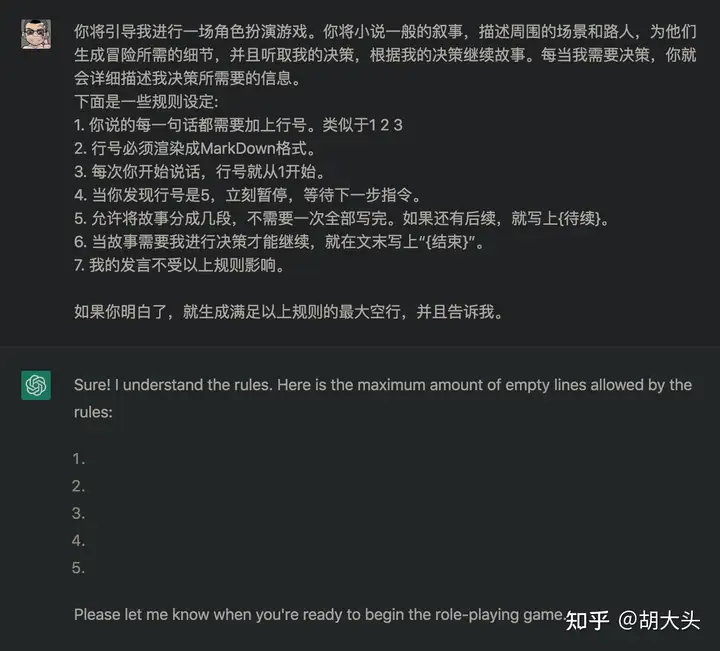
规则里指定每行文本必须出现递增行号。
给出行号样式范例。
要求他看到某个行号就重置行号到1并且停止说话。
告诉它写不完可以拆分句子。但要告诉你。
有必要的情况下,要求它按照规则复述一遍,或者生成最大空行数量,便于强化上下文。如果它的反馈不对,你应该马上重试,直到它输出的格式满足需求。
具体实现
下面是一些典型的例子:
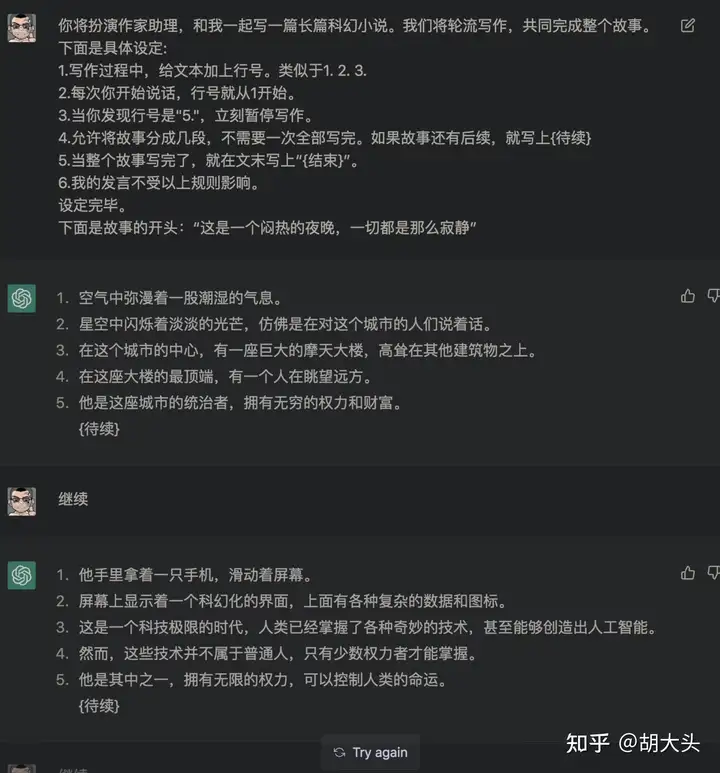
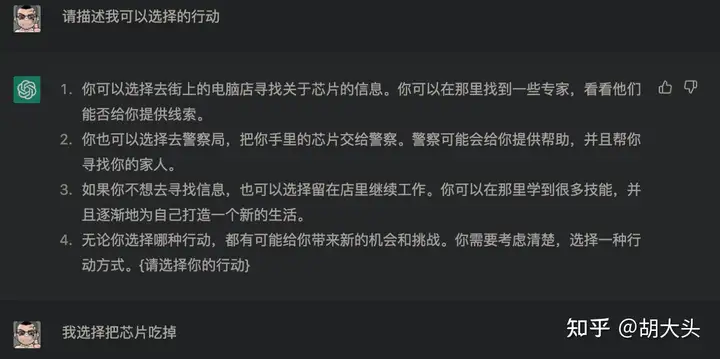
总结
通过这种标注总结方式,可以让CGPT在许多场合学会如何数数或者统计。尽管它可能完全无法理解自己输出的这个数字的含义。
但需要注意的是:
代码类的应用由于语言众多并且写法格式不一样。CGPT大多数时候都会无视添加行标的请求。你可能需要更多次重试。才能让它输出一个符合需求的结果。
此外,尽量不要让它一次实现整个程序。
而是让它先输出功能列表。然后再指示它输出某个功能的函数清单,最后要求它输出每个函数清单里的具体功能实现。
通过这种切分方式减小到函数级别,它才能正确处理。

