Jenkins共享库之Groovy语法

上一篇文章我们了解了jenkins 共享库的应用,在里面也用到了groovy的语法,这可能是jenkins门槛稍微高一点的应用,不过不要紧,我会慢慢带你们熟悉这门语言,后面的文章会逐步用共享库的方式,完成构建安卓,node,java等代码的编译,最后也会给你一套可以自动化识别,项目语言然后进行不同语言项目构建的方法。
首先我们来部署一下groovy的环境。
访问Groovy的官网
http://www.groovy-lang.org/
我们可以看到,它是Apache基金会管理的一个项目,和它的一些优点。点击Download,我们会看到很多版本

因为jenkins是运行的2.X的版本,所以我们也下载2.x的版本,可以直接下载windows的版本。连接如下:
https://groovy.jfrog.io/artifactory/dist-release-local/groovy-windows-installer/groovy-2.5.15/下载后完成安装,就会发现桌面上有一个Groovy Console的 图标。我们就可以用这个作为开发工具,来运行我们的groovy程序。
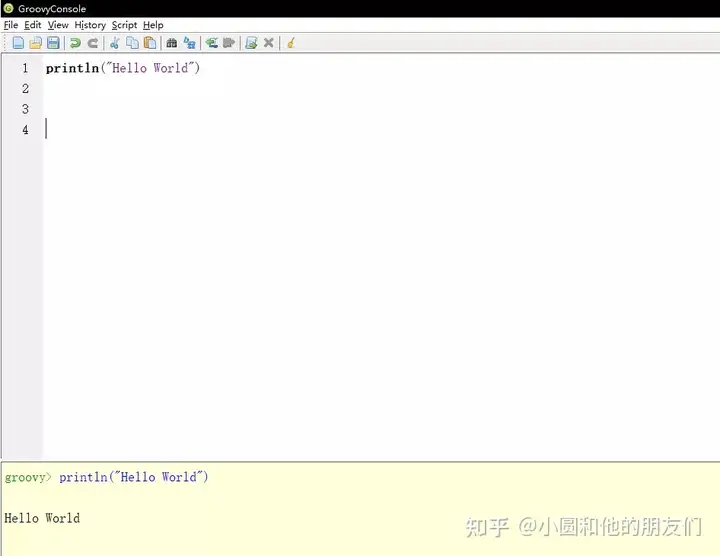
老规矩,先输出一下Hello World.
println("Hello World")然后ctrl + r 运行
接下来我会从数据类型,条件判断,循环控制,和函数来简述一下Grovvy的简单应用。
01 数据类型
字符串string
字符串表示我们可以使用,单引号、双引号、三引号三种方式。这里一定要注意,如果要引用变量,那么一定要用双引号,单引号会原样输出。
在写Jenkins的构建过程中,对字符串的操作用的最多的还是split的方法,有的时候我们会将url传过来的信息,分割一下取出我们想要的内容,拼写路径或者文件名称一类的。
比如,类似如下的操作
def srcName = srcUrl.split("/")[-1]
srcDir = "${workspace}/${srcTmp}"这里还用def这个关键字。那么除了split的方法,操作字符串还有没有其他的方法呢,当然是有。
contains(): 是否包含特定内容 返回true falsesize(): length() 字符串数量大小长度toString(): 转换成string类型indexOf(): 元素的索引endsWith(): 是否指定字符结尾minus() plus(): 去掉、增加字符串reverse(): 反向排序substring(1,2): 字符串的指定索引开始的子字符串toUpperCase() toLowerCase(): 字符串大小写转换split(): 字符串分割 默认空格分割 返回列表
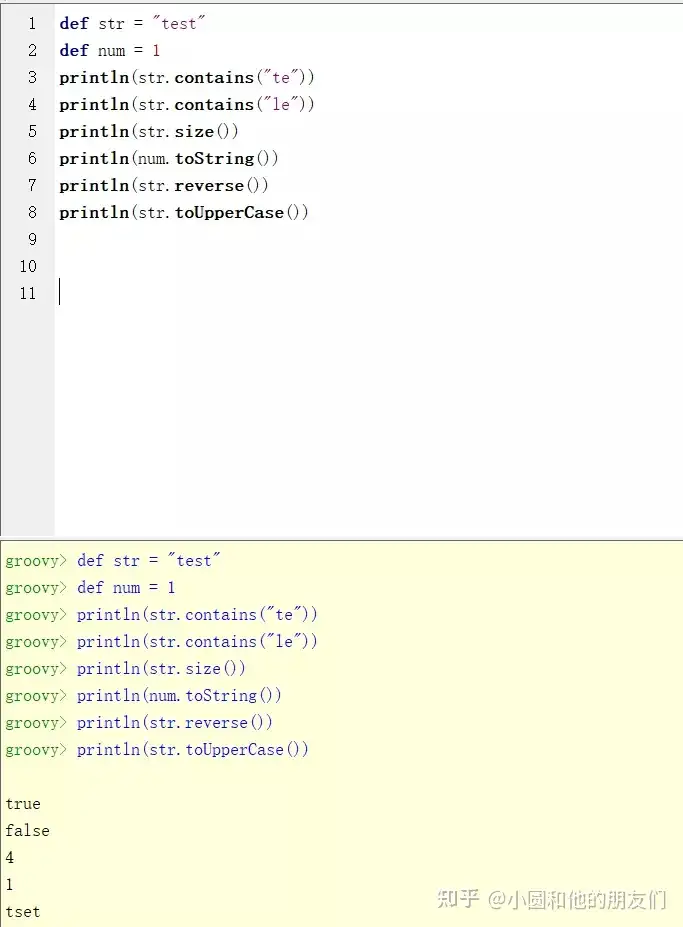
让我们来举几个例子,首先要定义两个变量,一个数字,一个字符串,然后对其进行操作
def str = "test"
def num = 1
println(str.contains("te"))
println(str.contains("le"))
println(str.size())
println(num.toString())
println(str.reverse())
println(str.toUpperCase())我们在编译器中试一下,效果如下
列表list
+ - += -=: 元素增加减少isEmpty(): 是否为空判断add(): 添加元素intersect([2,3]) disjoint([1]): 取交集、判断是否有交集flatten(): 合并嵌套的列表unique(): 去重reverse() sort(): 反转 升序count(): 元素个数join(): 将元素按照参数链接sum() min() max(): 求和 最小值 最大值contains(): 包含特定元素remove(2): removeAll()each{}: 遍历trim: 去除字符串前后的空格
def list1 = ["a", "b", "c"]
def list2 = ["d", "e", "f"]
def list3 = []
def list4 = ["a", "b", "c", "d", "e", "f"]
def list5 = ["a", "b", "c",["d", "e", "f"]]
def list6 = ["a", "b", "c", "a"]
println(list1 + list2)
println(list1.isEmpty())
println(list3.isEmpty())
println(list1.intersect(list2))
println(list4.intersect(list2))
println(list5.flatten())
println(list6.unique())输出
[a, b, c, d, e, f]
false
true
[]
[d, e, f]
[a, b, c, d, e, f]
[a, b, c]映射map
在Jenkins构建中,map是使用的相当频繁的一种数据架构。我们经常拿来定义变量,比如
def args = [
env: env.Environment,
workspace: "/var/lib/jenkins/workspace/cicd-projects",
groupName: env.GroupName,
projectName: null,
gitBranch: env.Branch,
gitUrl: env.RepositoryURL,
extra: null,
envType: env.EnvType
];使用的时候可以如下写法
stage(Pre) {
if (args.projectName == null) {
echo "projectName 为空"
}
echo "git地址:$args.gitUrl"
echo "git分支:$args.gitBranch"
echo "项目组:$args.groupName"
echo "项目名:$args.projectName"
echo "环境:$args.env"
echo "a,b环境: $args.envType"
echo "附加参数:$args.extra"
}对于map也有一些操作的方法
size(): map大小[’key’]: .key get() 获取valueisEmpty(): 是否为空containKey(): 是否包含keycontainValue(): 是否包含指定的valuekeySet(): 生成key的列表each{}: 遍历mapremove(‘a‘): 删除元素(k-v)
比如:
groovy:000> [:]
===> [:]
groovy:000> [1:2]
===> [1:2]
groovy:000> [1:2][1]
===> 2
groovy:000> [1:2,3:4,5:6]
===> [1:2, 3:4, 5:6]
groovy:000> [1:2,3:4,5:6].keySet()
===> [1, 3, 5]
groovy:000> [1:2,3:4,5:6].values()
===> [2, 4, 6]
groovy:000> [1:2,3:4,5:6] + [7:8]
===> [1:2, 3:4, 5:6, 7:8]
groovy:000> [1:2,3:4,5:6] - [7:8]
===> [1:2, 3:4, 5:6]02 条件语句
if语句
在Jenkinsfile中可用于条件判断。他的基本结构如下:
if (表达式) {
//xxxx
} else if(表达式2) {
//xxxxx
} else {
//
}我们可以用来判断项目,用来引用相应的工具。
if (buildType == maven){
Home = tool /usr/local/apache-maven
buildHome = "${Home}/bin/mvn"
} else if (buildType == ant){
Home = tool ANT
buildHome = "${Home}/bin/ant"
} else if (buildType == gradle){
buildHome = /usr/local/bin/gradle
} else{
error buildType Error [maven|ant|gradle]
}switch语句
switch语句的结构如下:
switch("${buildType}"){
case maven":
//xxxx
break;
case ant":
//xxxx
break;
default:
//xxxx
}下面我来举个例子,我们可以用另外的一个方式判断项目,返回响应的构建
switch (projectType){
case "java-gradle":
return new JavaGradleBuild(steps, args);
case "java-maven":
return new JavaMavenBuild(steps, args);
case "android":
return new AndroidBuild(steps, args);
case "web":
return new WebBuild(steps, args);
case "node":
return new NodeBuild(steps, args);
default:
return new Build(steps,args);
}我们可以将每一种构建写成一个groovy文件,然后判断响应的类型,返回一个new出来的实例,这部分内容。我会在后面的文章详细说明。
03 循环语句
for循环语句
test = [1,2,3]
for ( i in test){
///xxxxxx
break;
}比如,我们有一个列表,要遍历列表中内容来进行操作
langs = [java,python,groovy]
for ( lang in langs ){
if (lang == "java"){
println("lang error in java")
}else {
println("lang is ${lang}")
}
}while循环语句
while(true){04 函数和类
我们可以用def来定义一个函数
def PrintMes(info){
println(info)
return info
}
response = PrintMes("DevOps")
println(response)def也可以用来定义一个类中的方法。具体该怎么写呢?
比如,我们有一个文件build.groovy我们想让他作为一个入口文件判断项目的类型,然后运行响应的构建。我们又创建了一个JavaMavenBuild.groovy的文件来存放,构建用Maven工具来编译的Java程序。那我们需要怎么做呢
比如,我们将这两个文件放于/src/com/devops/pipeline/build的路径下。我们在JavaMavenBuild.groovy文件的第一行用package关键字声明一下package com.devops.pipeline.build,然后我们创建一个class,如下:
class JavaGradleBuild extends Build {
JavaGradleBuild(steps, args) {
super(steps, args);
if (args.env == prod) {
...
}
}
}这样我们在build.groovy文件中,就可以用new JavaMavenBuild(steps, args);的方式来引用它了。
最后我来总结一下,今天主要介绍了数据类型,条件判断,循环控制,和函数。Groovy作为脚本语言大部分内容还是比较简单,可能在类的地方有一些麻烦。这里要注意一些写法,比如字符串和单引号和双引号的区别。当我们在构建中,调用一个dockerfile进行容器构建的时候,我们会传一些变量到进去,在java -jar ...的命令中用,就需要注意这些写法。
最近一直有很多同学提到不会写 Jenkins Pipeline 脚本,我都是直接摔一个 Jenkins 官方文档给他们,但是当我自己仔细去查看资料的时候发现并非如此简单,无论是声明式还是脚本式的 Pipeline 都依赖了 Groovy 脚本,所以如果要很好的掌握 Pipeline 脚本的用法,我们非常有必要去了解下 Groovy 语言。
什么是 Groovy
Groovy 是跑在 JVM 中的另外一种语言,我们可以用 Groovy 在 Java 平台上进行编程,使用方式基本与使用 Java 代码的方式相同,所以如果你熟悉 Java 代码的话基本上不用花很多精力就可以掌握 Groovy 了,它的语法与 Java 语言的语法很相似,而且完成同样的功能基本上所需要的 Groovy 代码量会比 Java 的代码量少。
官方网站:https://groovy.apache.org
Groovy简明教程(JenkinsPipeline基础)
精华推荐:重磅发布 - 自动化框架基础指南pdf
Pipeline,简而言之,就是一套运行于Jenkins上的工作流框架,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排与可视化。
Pipeline是Jenkins2.X的最核心的特性,帮助Jenkins实现从CI到CD与DevOps的转变。
Pipeline是一组插件,让Jenkins可以实现持续交付管道的落地和实施。
持续交付管道(CD Pipeline)是将软件从版本控制阶段到交付给用户或客户的完整过程的自动化表现。软件的每一次更改(提交到源代码管理系统)都要经过一个复杂的过程才能被发布。
Pipeline提供了一组可扩展的工具,通过Pipeline Domain Specific Language(DSL)syntax可以达到Pipeline as Code(Jenkinsfile存储在项目的源代码库)的目的。
pipeline默认使用groovy来表示!!!所以学习groovy成为了掌握pipeline的基石。
下面我们一起了解下groovy。