体验AI绘画:快速上手StableDiffusion的三种方式
最近几个月,AI绘画算是火出圈了。
随便输入一段文本就能生成天马行空的精美图片,光是想想就让人激动。
我大概是从去年开始关注此类机器学习模型的,最早关注的是OpenAI家的Dall-E,后来才陆续认识了各种Diffusion扩散模型,也就是现在说的AI绘画模型。
AI绘画模型好不好,所有人都可以从审美的角度给出评价,所以,这成了AI技术进步能引起圈外人广泛围观的原因。
当然,现在能这么火,主要还在于Diffusion模型绘画效果比之前的GAN强太多了。
目前,普通人对AI绘画模型就只是好奇,画家或者设计类人员考虑的是获得新的创意。
而我,作为一个关注科技话题的文字编辑,比较好奇AI绘画模型在创作文章配图时的效果。
几个月前,我自己动手尝试了一下几个常见的AI绘画模型,算是近距离的接触了一下当下最火的AI技术。(体验:有了这些AI魔法,人人都是艺术家)
一番尝试后,个人感觉整体效果还可以,但离理想的效果还有不少差距(特别是画人物的时候)。同时也明白,想要效果好还得多学习和了解各种参数,多多尝试。
但想多试几次很难。
首先,因为大部分AI模型都没有开源,所以不能本地部署,Dall-E和Midjourney都没有。
第二,别人在线托管AI模型虽然能用,一般都得排队。
谷歌家的Colab很大方,但用的人多,抢到GPU资源后,能用多久都不一定,有时候一张图片没生成就被别人征用走了,想继续创作就得重新来过,SageMaker Studio Lab也是一样。(做毕设用不起GPU?亚马逊云SageMaker免费给你用)
第三种,付费使用别人托管的服务来生成图片,很多网站新手注册后都会给点积分,消耗完后就得充钱了,有很多还很贵,有很多人已经用这种东西赚快钱了,很明显,这也不适合大量使用。

2022年8月,开源的Stable Diffusion出现了,注意:它是开源的。它是由初创公司StabilityAI,CompVis与Runway合作开发的,它的代码和模型权重都已公开。
Stable Diffusion是根据公开的数据集LAION-5B训练而来的,训练的时候在亚马逊云科技上用256个英伟达A100 GPU,花费15万个小时训练而来的,成本大约需要60万美元。
更厉害的是,它可以在各种有GPU的电脑上运行(建议是10GB以上显存的电脑),包括Win、Linux电脑。
最最最厉害的是,它的用户拥有其生成的图像的权利,并可自由地将其用于商业用途。

StabilityAI的CEO叫Emad Mostaque,他曾表示,之所以将Stable Diffusion开放给所有人使用,就是为了结束大公司对此类技术的控制和主导地位,支持人工智能民主化。
看到这句话,我从路人瞬间粉上了这位大佬。
要知道,我为了体验Dall-E苦等了好几个月,最后发现,它不能在国内注册使用,当我曲线注册的时候,发现必须得有国外的手机来收验证码,看来,OpenAI对国内朋友好像不太友好。
如果你也忍耐不住,想要试试这个有点造福人类意味的AI绘画神器,我推荐三种方式:
第一种,从Huggingface上体验:
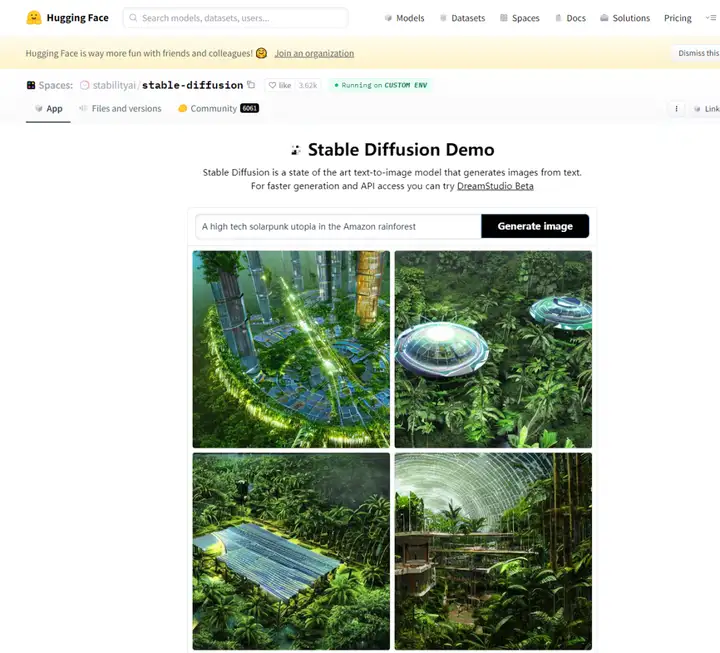
这是Stable Diffusion的一个Demo,也是最便捷的体验方式,输入文本点击生成即可。实际体验后发现,它生成的图片比较小,但速度也比较快。
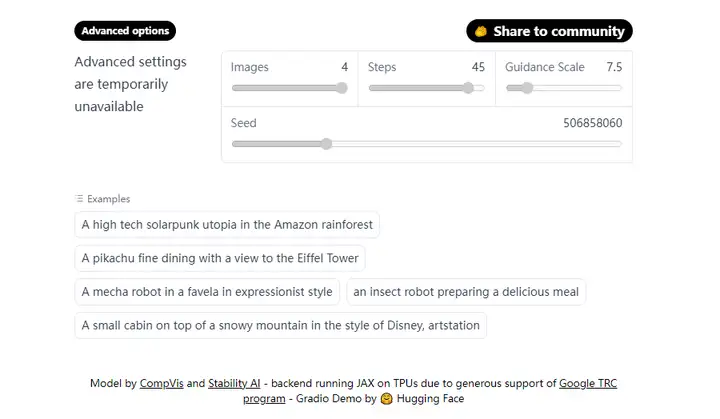
这种方式的优势就是方便,为了输出的效果更好,这里甚至还给你准备了一些示例的文本,可以借鉴这些句式生成你想要的图片。
最大的缺点是灵活性不足,我在打开的时候显示高级选项暂时不可用,仔细一看,这个高级选项里的可配置项也太少了,图片大小都不能调。(当然,默认的512x512是最好的,因为训练的图片就是这个分辨率)
第二种方法:在自己的Windows电脑上安装Stable Diffusionh和图形UI

我在装有3070显卡的电脑上装了Stable Diffusion和一个傻瓜式的图形UI操作界面(Github上开源的基于Gradio的WebUI),如下图所示。
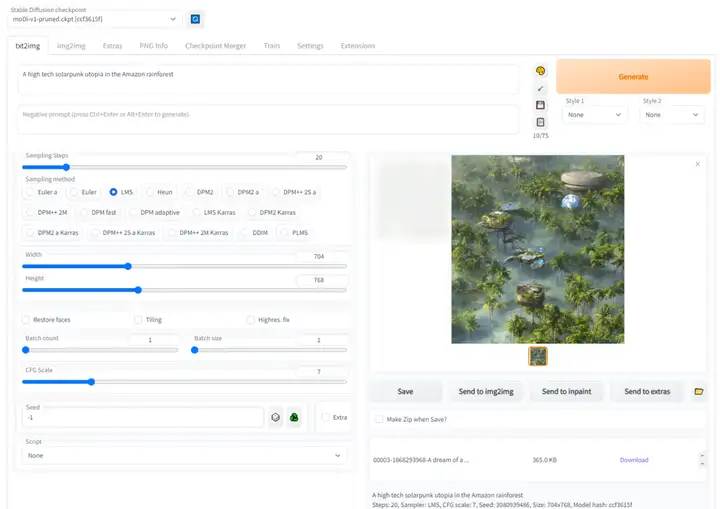
我建议有高性能显卡,并且喜欢折腾的朋友试试这种方式。当然,喜欢深度折腾的朋友直接请教谷歌来安装体验吧,网上关于Stable Diffusion的安装教程现在特别多。
我自己为了节省时间,就找了国内博主的教程来进行安装,安装完成后,所有资料加起来大概30多个GB。

这种方式的优点就是可配置选项非常多,还可以自己安装和更新新的模型,可以自由进行任何尝试,也不限次数。上图是我设置图片大小后生成的一张图片,感觉还挺好看。
这种方式方式的缺点:一方面是需要点折腾的劲头,另一方面,因为是本地部署,所以,需要你有一台高配显卡,我的3070只有8G显存,如果我想生成尺寸大一点的照片,就会提示我显存不够用。
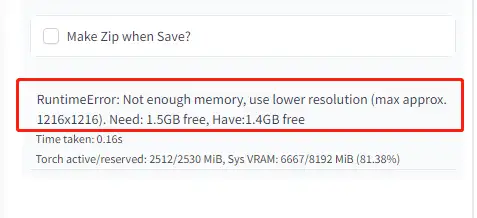
3070已经是我能买的最贵的显卡了,也不想为了这次体验,下血本升级大显存的3090或者4090。
跟我一个想法的应该不在少数,这时候,云主机就非常有优势了。
第三种方法:在UCloud云主机上体验
10月下旬,UCloud的GPU云主机推出了预装有Stable diffusion的镜像,在UCloud控制台创建GPU云主机时,在镜像市场选择AI绘画stable diffusion平台镜像,可以立马得到一台安装配置好的Stable diffusion。
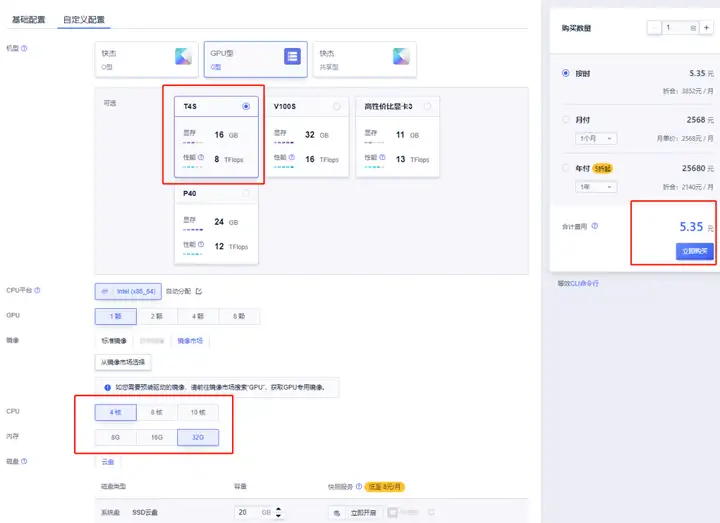
我在华北一可用区B创建了一台4核32GB的T4S主机,GPU显存为16GB,GPU性能为8TFlops。
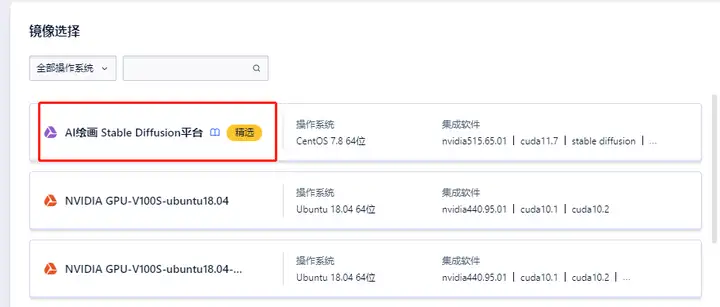
镜像选择的就是AI绘画Stable Diffusion平台,这台主机我是按照每小时5元的成本拿下的,镜像本身是免费的,只需要为计算、存储和网络资源付费。
初始化完成后,我按照官方文档进行了后续设置:
启动服务器里的Jupyter,开启主机防火墙的8888端口。
在本地浏览器里打开Jupyter,将从服务器端拿到的Token输入后即可登录。
然后,就可以在本地浏览器里打开熟悉的Jupyter进行后续操作了。
操作也很简单,在文档中创建新的笔记本,把Kernel设置成ldm。
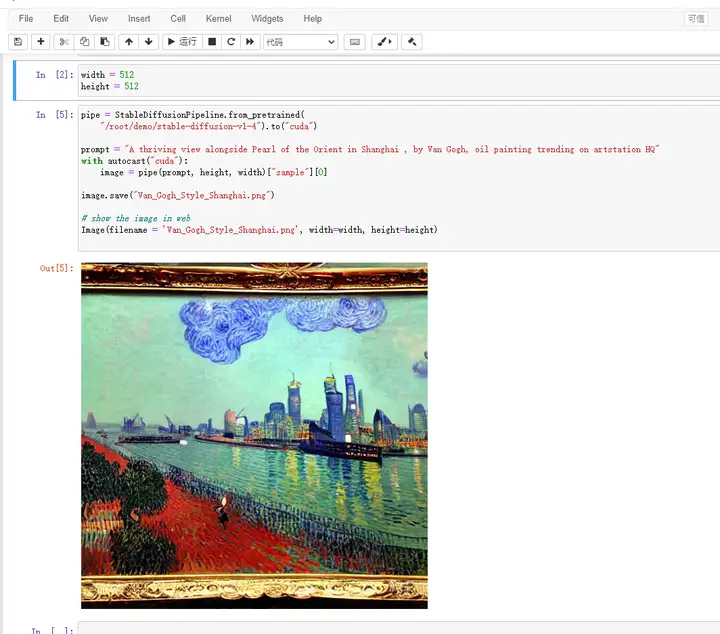
随后,我把一段UCloud官方文档提到的示例代码放进去,一步步执行下去就能生成上图中的图片了。
以上生成图像所使用的文本都是英文的,最近首个中文Stable Diffusion模型太乙也开源了。
重点是,它支持用中文生成图像。下图是Demo路径下的示例代码:
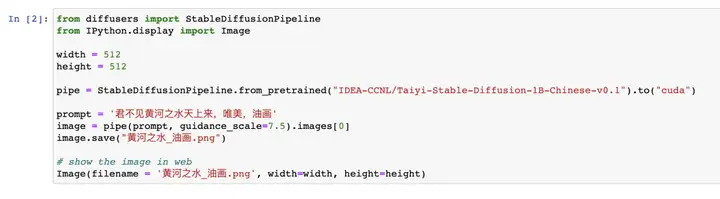
比如输入:君不见黄河之水天上来,唯美,油画,然后就生成了这样一张图片。

再输入枯藤老树昏鸦,小桥流水人家,水墨画,会生成这样一张图片,是不是还挺有意境的。

我自己手动输入大漠孤烟直,长河落日圆,水墨画,得到下面这张图片,我有点被惊艳到了。

下面这一张是基于同一个Promot提示符生成的。

用Jupyter的话,可以进行更多更高自由度的设置,比如我可以修改Prompt提示符的文字,也可以修改图片的尺寸,可以进行更多尝试。
如果暂时没有别的想法了,可以立即把这台云主机删除,在需要的时候可以再次开启,这就是云服务提供的便利,这其实是给更专业的人推荐的方式。
以上就是这次体验到主要内容,想尝试AI绘画的可以从中选择。
结束语
这次体验,感觉Stable Diffusion比之前用的几个模型的效果都要好一点,当然,这只是我个人直观感受,具体的技术实现我完全不了解。
有机会体验一下最前沿,最热门的技术我还是挺激动的,如果你也对它感兴趣,也欢迎各种方式交流。
-
上一篇
熟悉stable diffusion绘图的老铁们都知道,一个能用于SD作图的显卡、一个GPU服务器到底有多贵,即使是云GPU,一个小时使用费没个2块钱也是很难搞下来的,前期任何人在没有合适的变现项目的情况下,基本上很多人是不敢去花大价钱购买这些硬件的,以至于让很多对sd绘图感兴趣的人望而却步,今天我自己服务器上部署了一个SD在线绘图程序!帮助新手学习SD,带大家入门是够了,修行的话还是要靠自身!目前仅对星球好友开放!
sd在线绘图网址:https://sd6666.tocmcc.cn/
打开后提示登录页面,接下来看使用注意事项
使用前注意:
1、需要我来给你扫码登录,账号密码我会发给你,只要你不清除浏览器缓存,后期会自动打开首页绘图主页面!
2、服务器需要休息,遇到不能出图的情况,就是服务器在维护
3、不支持下载模型,已经安装好常用模型,仅供入门学习使用
4、你自己在用的时候,只需要调节服装、表情、场景即可,其他的参数基本不用去动,不会的话直接有道翻译
5、作图最大尺寸为540*960,高清放大 1.2 倍
最简单的绘图
参数界面上的与我保持一致,提示语大概填一下,比如1dog,就会画出来一只狗
AI美女绘图
我自己搭的AI绘画网站已上线,无限作图!
先说一个我的AI绘画专题直播6.13号晚上9点视频号开播:
-
下一篇

你想知道ai绘画工具在线体验方法有哪些吗
原标题:你想知道ai绘画工具在线体验方法有哪些吗
